Building a Multi‑Agent Research Pipeline addresses critical bottlenecks in modern application development where manual information gathering consumes significant development time. Research workflows involving data validation, source verification, and report compilation create delays in product development cycles. Traditional automation approaches fail because research tasks require contextual decision-making and adaptive information processing capabilities.
n8n’s AI Agent nodes solve this challenge by implementing intelligent automation that adapts to different research scenarios. You can build autonomous research systems that gather current information, synthesize findings, and validate accuracy without manual intervention or custom coding.
This guide demonstrates building a production-ready multi-agent research system using n8n’s visual workflow builder. The pipeline processes text queries and returns structured research reports with automated source validation. You’ll implement three specialized agents that collaborate to deliver comprehensive research outputs.
The implementation reduces research time from hours to minutes while maintaining accuracy through automated fact-checking. Development teams can integrate this system into knowledge bases, competitive analysis tools, or customer research platforms.
What is a Multi‑Agent Research Pipeline?
A multi-agent research pipeline distributes research tasks across specialized AI agents that excel at specific functions. Each agent focuses on one aspect of the research process while passing processed data to subsequent agents.
- Search Agent executes web queries using search APIs and retrieves current information from multiple sources. It analyzes research queries and formulates effective search strategies based on the topic and required information depth.
- Summarization Agent processes raw search results into structured insights. It extracts key facts, identifies trends, and organizes information into readable summaries while maintaining source accuracy.
- Fact-Checking Agent validates summarized content against original sources. It identifies unsupported claims, factual inconsistencies, and missing context to prevent information errors from propagating through your application.
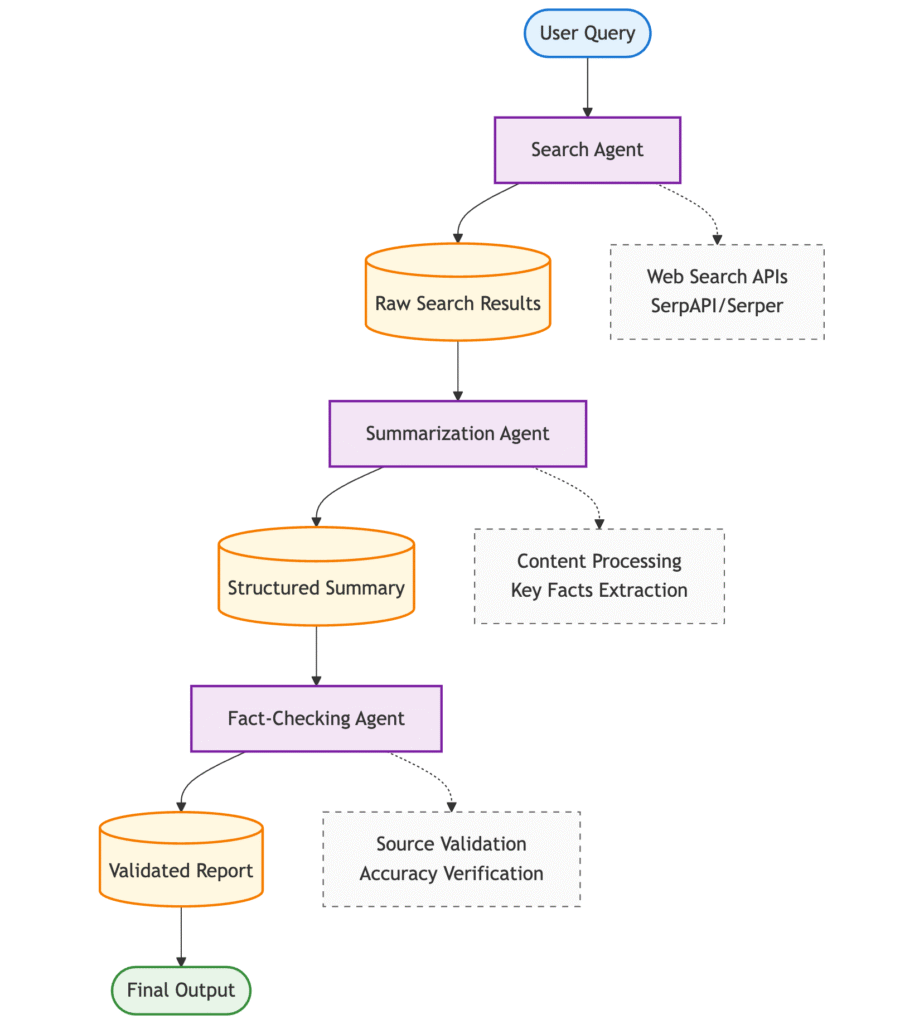
This architecture provides several advantages over single-agent systems. Specialized agents perform better at focused tasks than generalist agents handling multiple responsibilities. The modular design allows independent optimization of each component without affecting the entire pipeline.
Error isolation prevents failures in one agent from breaking the complete workflow. You can modify search strategies, adjust summarization focus, or enhance fact-checking rigor independently.
How does this differ from traditional search APIs? Standard search APIs return raw results that require manual processing. This pipeline automatically processes, synthesizes, and validates information before delivering structured reports.
Prerequisites to Build the Pipeline
This section covers API credentials and external service setup required for the research pipeline. We assume you have an operational n8n instance and basic familiarity with AI Agent nodes.
OpenAI API Configuration
The pipeline requires OpenAI access for language model functionality across all three agents.
- Account Setup:
- Create an OpenAI account at platform.openai.com
- Add billing information and a minimum $5 credit
- Generate an API key from the API Keys section
- Copy the key for n8n credential configuration
- n8n Credential Creation:
- Navigate to Settings → Credentials in your n8n instance
- Click “Add Credential” and select “OpenAI”
- Paste your API key and save the credential
- Test the connection to verify functionality
Reference the OpenAI credentials documentation for detailed setup instructions.
Web Search API Setup
Choose between SerpAPI and Serper API based on your volume requirements and budget constraints.
SerpAPI Configuration (Recommended)
SerpAPI provides comprehensive Google search results with official n8n integration.
- Setup Process:
- Register at serpapi.com/users/sign_up
- Retrieve API key from serpapi.com/manage-api-key
- Note: 100 free searches per month, then $50/month for 5,000 searches
- n8n Integration:
- Go to Settings → Credentials
- Select “Add Credential” → “SerpAPI”
- Enter your API key and test the connection
Reference the SerpAPI credentials documentation for configuration details.
Serper API Configuration (Budget Alternative)
Serper delivers fast results at competitive pricing for high-volume applications.
- Setup Process:
- Sign up at serper.dev
- Copy API key from dashboard
- Note: 2,500 free searches for new accounts, then $50/month for 166,000 searches
- n8n Integration:
- Navigate to Settings → Credentials
- Choose “Add Credential” → “HTTP Header Auth”
- Set Name:
X-API-KEY, Value: your Serper API key
Reference the HTTP Header Auth documentation for setup guidance.
Cost Analysis
| Service | Development Phase | Production Phase (Monthly) | Volume Capacity |
|---|---|---|---|
| OpenAI | $5-10 testing budget | $20-50 operational cost | gpt-4o-mini recommended |
| SerpAPI | 100 free searches | $50+ for 5,000+ searches | Professional reliability |
| Serper | 2,500 free searches | $50+ for 166,000+ searches | High-volume applications |
The pipeline uses gpt-4o-mini to balance cost efficiency with processing quality across all agents.
If you doesn’t have a n8n instance, you can refer this guide to setup one in your google cloud account: Deploy N8n on Google Cloud
Step 1: Configure the Research Input Trigger
Start by creating the input mechanism that captures research queries and initializes the agent workflow.
Add Manual Chat Trigger:
- Create new workflow in n8n
- Remove default trigger if present
- Add “Manual Chat Trigger” node
- Configure settings:
- Node name: “Research Query Trigger”
- Webhook ID: “research-webhook”
- Leave other settings as default
The Manual Chat Trigger captures user input in the chatInput field and provides an interactive testing interface through n8n’s built-in chat functionality.
Step 2: Build the Search Agent
Create the information gathering component that processes research queries and executes web searches.
Add AI Agent Node:
- Connect AI Agent to trigger output
- Configure agent parameters:
- Node name: “Search Agent”
- Prompt Type: “Define below”
- Text:
{{ $json.chatInput }} - System Message: “You are a research specialist. Use the web search tool to find current, accurate information about the user’s query. Focus on credible sources and recent data.”
Attach Language Model:
- Click “+” under Chat Model connection
- Select “OpenAI Chat Model”
- Configure model settings:
- Model: “gpt-4o-mini”
- Temperature: 0.2
- Max Tokens: 1000
- Select your OpenAI credentials
The low temperature setting (0.2) produces consistent, factual responses while the 1000 token limit allows processing multiple search results.
Step 3: Implement Search Tools
Add web search capabilities using your preferred search API. You can implement both options for redundancy.
SerpAPI Implementation
Add SerpAPI Search Tool:
- Click “+” under Tools connection on Search Agent
- Select “SerpAPI Search Tool”
- Configure parameters:
- Engine: “google”
- Query:
{{ $fromAI('query') }} - Location: “United States”
- Device Type: “desktop”
- Select your SerpAPI credentials
Serper API Implementation
Add HTTP Request Tool:
- Click “+” under Tools connection on Search Agent
- Select “HTTP Request Tool”
- Configure tool settings:
- Name: “web_search”
- Description: “Search the web for current information”
- URL: “https://google.serper.dev/search”
- Authentication: “Generic Credential Type”
- Auth Type: “HTTP Header Auth”
- Request Method: “POST”
- Body Parameters:
- q:
{{ $fromAI('query') }} - num: “10”
- q:
- Select your Serper HTTP Header Auth credentials
Both tools connect via the ai_tool connection type, allowing the agent to determine when search functionality is needed.
Step 4: Create the Summarization Agent
Build the data processing component that converts raw search results into structured insights.
Add Second AI Agent:
- Connect new AI Agent to Search Agent main output
- Configure summarization settings:
- Node name: “Summarizer Agent”
- Prompt Type: “Define below”
- Text: “Create a clear summary from these search results focusing on: key facts, recent developments, statistics, and main conclusions.\n\nSearch Results:\n{{ $(‘Search Agent’).item.json.output }}”
- System Message: “You are an expert information synthesizer. Create accurate, concise summaries from search results. Focus on factual content and maintain objectivity.”
Attach Language Model:
- Add “OpenAI Chat Model” sub-node
- Configure model parameters:
- Model: “gpt-4o-mini”
- Temperature: 0.1
- Max Tokens: 800
- Select your OpenAI credentials
The lower temperature (0.1) increases consistency while the 800 token limit focuses responses on essential information.
Step 5: Implement Fact-Checking Agent
Create the validation layer that verifies summarized content against original sources.
Add Third AI Agent:
- Connect new AI Agent to Summarizer Agent main output
- Configure fact-checking parameters:
- Node name: “Fact Checker Agent”
- Prompt Type: “Define below”
- Text: “Compare this summary against original search results and identify: factual accuracy, unsupported claims, contradictions, missing context.\n\nSummary:\n{{ $(‘Summarizer Agent’).item.json.output }}\n\nOriginal Sources:\n{{ $(‘Search Agent’).item.json.output }}”
- System Message: “You are a fact-checking specialist. Compare claims against source material and identify discrepancies objectively.”
Attach Language Model:
- Add “OpenAI Chat Model” sub-node
- Configure verification settings:
- Model: “gpt-4o-mini”
- Temperature: 0
- Max Tokens: 600
- Select your OpenAI credentials
Zero temperature maximizes consistency in verification decisions, while 600 tokens focuses on accuracy assessment.
Step 6: Compile Final Research Report
Structure the output data using a Set node that combines all agent results into a comprehensive report.
Add Set Node:
- Connect Set node to Fact Checker Agent main output
- Configure data assignments:
- Node name: “Compile Final Report”
- query:
{{ $('Research Query Trigger').item.json.chatInput }} - searchResults:
{{ $('Search Agent').item.json.output }} - summary:
{{ $('Summarizer Agent').item.json.output }} - factCheck:
{{ $('Fact Checker Agent').item.json.output }} - timestamp:
{{ new Date().toISOString() }} - researchReport: Markdown-formatted report combining all outputs
This creates structured JSON data suitable for API responses, database storage, or integration with external systems.
Testing and Results
Execute comprehensive testing using n8n’s chat interface to verify pipeline functionality and output quality.
Testing Procedure
Initialize Workflow:
- Click “Test workflow” to prepare execution environment
- Click “Open chat” button (appears near canvas bottom)
- Chat interface opens in side panel for interactive testing
Submit Test Queries:
"What are the latest quantum computing breakthroughs in 2025?"
"How has cybersecurity evolved since the rise of AI?"
"Current trends in renewable energy storage technology"
"Recent developments in autonomous vehicle safety"
Monitor Execution:
- Open each AI Agent node during execution
- Click “Logs” tab to view processing details
- Verify search results contain relevant, current information
- Check summaries capture key points accurately
- Confirm fact-checking identifies discrepancies when present
Expected Output Structure
The pipeline generates structured JSON responses with this format:
{
"query": "What are the latest quantum computing breakthroughs in 2025?",
"searchResults": "Quantum computing research in 2025 shows significant progress in error correction, with IBM announcing 1000-qubit processors and Google demonstrating quantum advantage in optimization problems...",
"summary": "Major quantum computing advances in 2025 include IBM's 1000-qubit processor breakthrough, Google's optimization algorithm demonstrations, and Microsoft's topological qubit developments. Key metrics show 99.9% error correction improvement...",
"factCheck": "Verified: IBM's 1000-qubit announcement aligns with source material from March 2025. Google's optimization claims supported by published research. No contradictions identified.",
"timestamp": "2025-01-10T15:30:00.000Z",
"researchReport": "# Research Report: Latest Quantum Computing Breakthroughs\n\n## Summary\n[Structured insights]\n\n## Verification\n[Accuracy assessment]\n\n## Sources\n[Original search data]"
}
Quality Assessment Criteria
High-Quality Results Include:
- Current information with specific dates and sources
- Statistical data with proper context and verification
- Clear identification of trends and developments
- Accurate fact-checking that catches inconsistencies
Common Issues to Address:
- Generic responses lacking query-specific details
- Outdated information from cached search results
- Summaries containing unsupported claims
- Fact-checking that misses obvious discrepancies
Performance Optimization:
- Monitor API response times (target: <10 seconds total)
- Track token usage across all agents
- Verify search result relevance and recency
- Test edge cases with ambiguous or technical queries
Does your testing reveal any patterns in search quality or agent performance? Adjust system messages and search parameters based on observed results to improve accuracy and relevance.
Conclusion
This multi-agent research pipeline transforms manual research workflows into automated, intelligent systems. The modular architecture allows independent optimization while maintaining production reliability across different research scenarios.
The implementation demonstrates practical AI automation using n8n’s visual workflow capabilities. Three specialized agents collaborate to produce comprehensive, validated research reports from simple text queries. Each component focuses on its core function while contributing to overall system accuracy.
Key advantages include automated source validation, consistent report formatting, and scalable information processing. The pipeline handles routine research tasks efficiently, freeing developers to focus on product features and strategic analysis.
Consider integrating this system into knowledge management platforms, competitive intelligence tools, or customer research workflows. The standardized output format supports various downstream applications while the API-based architecture scales with application requirements.
Future enhancements might include specialized domain agents, multi-language support, or integration with vector databases for semantic search capabilities. The foundation provided here supports these advanced features while maintaining operational stability.
How might automated research capabilities change your development workflow? Start with simple queries to test accuracy, then gradually implement more complex research scenarios as you refine the agent configurations for your specific use cases.
FAQs
How do I choose between SerpAPI and Serper API for my research pipeline?
Choose based on volume requirements and budget constraints. SerpAPI offers 100 free searches monthly, then $50/month for 5,000 searches. It provides comprehensive data parsing, official n8n integration, and enterprise support features. Serper API gives 2,500 free searches initially, then $50/month for 166,000 searches with 1-2 second response times. Use SerpAPI for development and moderate-volume production deployments. Choose Serper for high-volume applications where cost efficiency outweighs additional features.
What’s the most cost-effective way to run this pipeline in production?
Use gpt-4o-mini instead of gpt-4 to reduce OpenAI costs by approximately 60% while maintaining adequate research quality. Configure appropriate token limits: Search Agent (1000), Summarizer (800), Fact Checker (600). Set temperature values low (0.1-0.2) to reduce response variability and improve consistency. Monitor usage through OpenAI’s dashboard and implement rate limiting for high-volume scenarios. Group multiple research queries into batch processing when possible since n8n charges per workflow execution.
Can this pipeline handle technical or specialized research topics?
Yes, but requires domain-specific configuration. Modify the Search Agent’s system message to include technical terminology and preferred source types. Add domain-specific search parameters like site:arxiv.org for academic papers or site:github.com for technical documentation. Configure the Summarization Agent to maintain technical accuracy and include specialized metrics. The Fact-Checking Agent may need enhanced instructions for validating technical claims against authoritative sources. Test with sample queries in your domain to refine accuracy.
How do I integrate the research pipeline with external applications?
Add integration nodes after the “Compile Final Report” Set node. For Slack notifications, use the Slack node with webhook URLs or bot tokens. For email reports, configure the Email node with SMTP credentials or services like SendGrid. For database storage, add PostgreSQL, MySQL, or MongoDB nodes to store research results. For API access, use the Webhook node to expose the pipeline as a REST endpoint. Map the structured research data to required formats for each integration target.
What should I do if the agents return irrelevant or inaccurate results?
Improve search query formulation by modifying the Search Agent’s system message to create more specific, targeted queries using relevant keywords. Adjust search tool parameters like result count, location targeting, or time restrictions for current information. Enhance agent instructions to specify quality criteria, preferring academic papers, official reports, and established news sources. Monitor search patterns across multiple test queries and refine prompts based on observed issues. Implement result filtering based on domain authority or publication dates. Consider adding secondary search strategies when initial results prove inadequate.







