
Every AI application developer faces the same challenge: LLM tokens cost real money. Each API call to GPT-5, Claude 4, or Gemini 2.5 burns through your budget, character by character. JSON has served as the universal data format for two decades, but its verbose syntax was designed for human readability and web APIs—not for token-sensitive AI systems.
TOON (Token-Oriented Object Notation) changes that equation. This format delivers 30-60% token reduction compared to standard JSON while maintaining lossless data representation. For high-volume AI applications processing millions of tokens daily, this translates directly to substantial cost savings and faster response times.
Understanding the Token Economy of Modern LLMs
Modern LLM pricing operates on a token-based model where both input and output consume billable units. As of November 2025, typical pricing ranges from $0.25 to $15 per million input tokens depending on the model tier. Output tokens command even higher rates—between $1.25 and $75 per million tokens.
Consider a production AI system processing 10 million tokens monthly at GPT-4o pricing ($5 per million input tokens, $20 per million output tokens):
- Input costs: $50/month
- Output costs: $200/month
- Total: $250/month
Scale that to 100 million tokens monthly and you’re looking at $2,500 in API costs alone. Reducing token consumption by 40% through format optimization saves $1,000 monthly—$12,000 annually—without changing a single line of application logic.
This math explains why token efficiency matters. Every unnecessary bracket, quote, or repeated key name in your data payload directly impacts your bottom line.
JSON: Built for the Web, Not for AI
JSON emerged in the early 2000s as a lightweight alternative to XML. Douglas Crockford designed it for human readability and machine parsability across web APIs. For those purposes, JSON excels.
JSON’s Structural Overhead
Standard JSON requires explicit delimiters for every structural element:
- Curly braces
{}for objects - Square brackets
[]for arrays - Colons
:for key-value pairs - Commas
,for element separation - Quotes
""around all string keys and values
Each of these characters consumes tokens. For simple objects, the overhead remains negligible. For large datasets with repeated structures, the overhead compounds dramatically.
Consider this employee dataset in formatted JSON:
{
"employees": [
{
"id": 1,
"name": "Alice Chen",
"department": "Engineering",
"salary": 120000,
"yearsExperience": 8,
"active": true
},
{
"id": 2,
"name": "Bob Martinez",
"department": "Marketing",
"salary": 95000,
"yearsExperience": 5,
"active": true
},
{
"id": 3,
"name": "Carol Kim",
"department": "Engineering",
"salary": 110000,
"yearsExperience": 6,
"active": false
}
]
}
This structure repeats field names ("id", "name", "department", etc.) for every single record. With 100 employee records, you write the same six field names 100 times. With 1,000 records, you write them 1,000 times.
For an LLM, these repeated keys provide no additional semantic value—the model already understood the schema from the first object. But you pay for every repetition.
Compact JSON: A Partial Solution
Minified JSON removes whitespace and newlines:
{"employees":[{"id":1,"name":"Alice Chen","department":"Engineering","salary":120000,"yearsExperience":8,"active":true},{"id":2,"name":"Bob Martinez","department":"Marketing","salary":95000,"yearsExperience":5,"active":true}]}
This reduces tokens by eliminating formatting, but it preserves all structural overhead. You still repeat field names, maintain all quotes, and include every bracket and brace. Token reduction typically reaches 20-30% compared to formatted JSON—helpful but not transformative.
More importantly, compact JSON sacrifices human readability entirely. Debugging prompts or validating data structures becomes significantly harder.
TOON: Purpose-Built for Token Efficiency
TOON takes a fundamentally different approach by recognizing that AI models don’t need the same structural hints humans require. The format eliminates redundant syntax while maintaining complete data fidelity.
Core Design Principles
TOON achieves token efficiency through three key strategies:
1. Indentation-Based Structure
Like YAML, TOON uses whitespace to represent nesting instead of explicit delimiters:
user:
id: 123
name: Ada Thompson
created: 2025-01-15T10:30:00Z
No curly braces. No brackets for simple objects. The indentation clearly communicates hierarchy without consuming tokens for punctuation.
2. Minimal Quoting
TOON applies quotes only when necessary to prevent parsing ambiguity:
- Unquoted:
name: Ada Thompson - Quoted:
note: "Cost: $5.00" - Quoted:
status: "true"(prevents boolean interpretation)
This selective quoting maintains clarity while reducing token count. The format automatically handles the logic—developers don’t need to memorize quoting rules.
3. Tabular Array Format
This represents TOON’s most significant innovation. When processing arrays of uniform objects (same fields, primitive values), TOON declares the schema once and streams data as rows:
employees[3]{id,name,department,salary,yearsExperience,active}:
1,Alice Chen,Engineering,120000,8,true
2,Bob Martinez,Marketing,95000,5,true
3,Carol Kim,Engineering,110000,6,false
The header line employees[3]{id,name,department,salary,yearsExperience,active}: communicates three critical pieces of information:
- Array length:
[3]indicates three records - Field schema:
{id,name,...}defines the structure - Delimiter scope: Following lines use comma separation
Each data row contains only values—no repeated keys, no extra quotes, no structural punctuation beyond the delimiter.
How TOON Compares to CSV?
CSV (Comma-Separated Values) also uses tabular formatting. However, CSV lacks structural awareness:
- No nested object support
- No explicit type information
- No array length validation
- No delimiter declaration in the format itself
TOON provides CSV’s compactness while preserving JSON’s structural capabilities. You can nest objects, mix data types, and validate structure—capabilities CSV cannot offer.
For pure flat tabular data, CSV remains slightly more compact (typically 5-10% fewer tokens than TOON). But TOON adds minimal overhead to provide structural guarantees that improve LLM comprehension and reduce parsing errors.
Real-World Token Comparisons
Concrete examples demonstrate TOON’s efficiency advantages across different data patterns.
Example 1: Uniform Employee Records (100 records)
JSON (formatted): 126,860 tokens
Repeated keys, quotes, and structural punctuation for every record.
JSON (compact): 78,856 tokens
Whitespace removed but all structural overhead preserved.
TOON: 49,831 tokens
Tabular format with schema declared once.
Token reduction: 60.7% vs formatted JSON, 36.8% vs compact JSON
Example 2: E-commerce Orders with Nested Structures (50 orders)
orders[2]{orderId,customer,items,total,status}:
ORD-001,customer:
id: C-123
name: John Smith
items[2]{sku,qty,price}:
A1,2,9.99
B2,1,14.50
24.48,shipped
ORD-002,customer:
id: C-456
name: Sarah Wilson
items[3]{sku,qty,price}:
C3,1,29.99
D4,2,7.50
E5,1,12.00
56.99,pending
This example demonstrates TOON’s handling of nested structures. The outer array uses tabular format, while nested customer objects and item arrays maintain their own appropriate formats.
JSON (formatted): 108,806 tokens
JSON (compact): 68,975 tokens
TOON: 72,771 tokens
Token reduction: 33.1% vs formatted JSON
Notice that compact JSON actually beats TOON here by 5.5%. When data contains significant nesting and non-uniform structures, compact JSON can be more efficient. TOON doesn’t claim universal superiority—it optimizes for specific patterns where it delivers maximum value.
Example 3: Time-Series Analytics (60 days of metrics)
metrics[5]{date,views,clicks,conversions,revenue,bounceRate}:
2025-01-01,5715,211,28,7976.46,0.47
2025-01-02,7103,393,28,8360.53,0.32
2025-01-03,7248,378,24,3212.57,0.50
2025-01-04,2927,77,11,1211.69,0.62
2025-01-05,3530,82,8,462.77,0.56
JSON (formatted): 22,250 tokens
TOON: 9,120 tokens
Token reduction: 59.0%
Highly uniform data with primitive values represents TOON’s sweet spot. The more rows you add, the greater the savings compound.
LLM Comprehension: Accuracy Beyond Token Count
Token efficiency means nothing if models struggle to parse the format. Comprehensive benchmarks tested retrieval accuracy across four major LLM families using 209 data retrieval questions spanning field lookups, aggregations, filtering, and structural validation.
Accuracy Results:
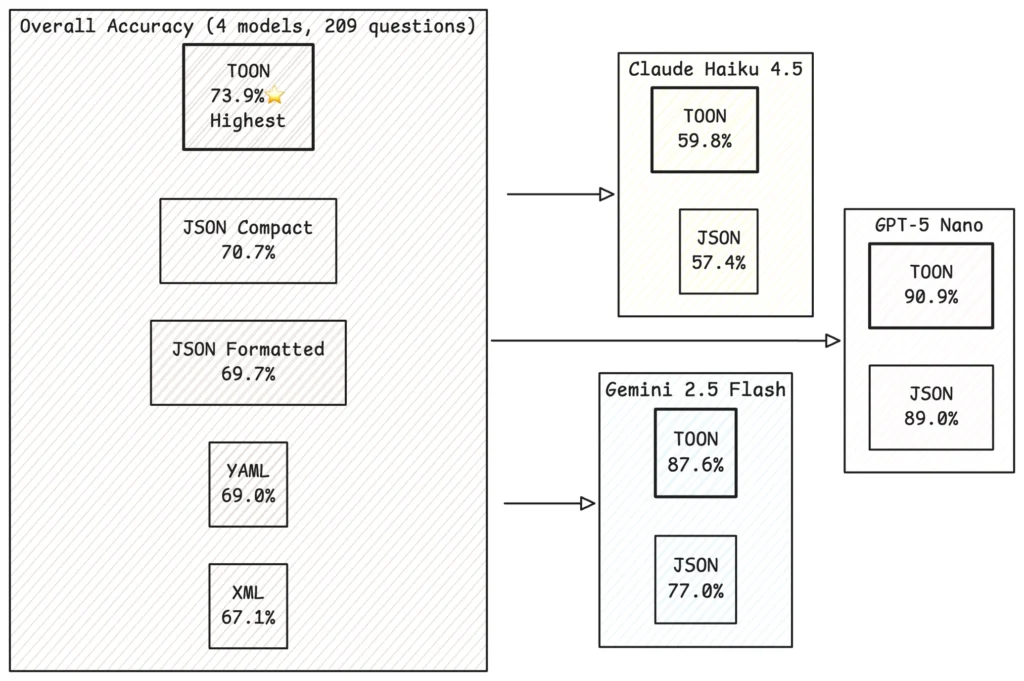
Why TOON Improves Comprehension
The explicit structure helps LLMs in several ways:
Array Length Declarations
The [N] notation tells the model exactly how many elements to expect:
users[3]: ...
This prevents counting errors and enables validation. If the declared length doesn’t match actual rows, the model can detect corruption or truncation.
Field Schema Headers
The {field1,field2,...} pattern declares which fields exist and their order:
users[3]{id,name,role}:
Models don’t need to infer schema from data—it’s explicitly stated. This reduces ambiguity and parsing errors.
Reduced Syntactic Noise
Fewer brackets, quotes, and punctuation means clearer signal-to-noise ratio. The model processes semantic content rather than structural overhead.
When to Use TOON vs JSON ?
Format selection depends on your specific data patterns and use case.
TOON Excels With:
- High tabular eligibility (>60%) Arrays of uniform objects with primitive values—employee records, transaction logs, product catalogs, time-series data. The more uniform your data, the greater TOON’s advantage.
- LLM input optimization Any scenario where you’re sending structured data to AI models for analysis, classification, or retrieval. Token reduction directly impacts costs.
- High-volume AI applications Systems processing millions to billions of tokens monthly where even 20% reduction yields substantial savings.
- Structured data validation Applications requiring explicit schema declaration and length validation to catch truncation or corruption.
JSON Remains Better For:
- Deep nesting (5+ levels) Highly nested configuration objects or complex hierarchical data where tabular formatting offers no advantage.
- Non-uniform structures Data where objects in arrays have different fields, requiring individual object representation.
- Universal API compatibility Public APIs requiring maximum ecosystem compatibility across all programming languages and platforms.
- Existing infrastructure Systems with mature JSON pipelines where conversion overhead outweighs token savings.
Hybrid Approach
Many production systems use both formats strategically:
- JSON for internal application logic and public APIs
- TOON for LLM interactions where token efficiency matters
Convert at the boundary between your application and AI services:
import { encode, decode } from '@toon-format/toon';
// Application uses JSON internally
const data = await fetchEmployeeData();
// Convert to TOON for LLM
const toonData = encode(data);
const prompt = `Analyze this employee data:\n${toonData}`;
const response = await callLLM(prompt);
// Work with results in JSON
const result = JSON.parse(response);
This pattern provides universal compatibility where needed and token efficiency where it delivers value.
How Can You Convert Your JSON Data to TOON?
Converting existing JSON data to TOON requires no complex setup or library installation. You can transform your data instantly using a web-based converter.
Step 1: Navigate to app.too1s.tech
Open your browser and visit app.too1s.tech. This provides immediate access to the conversion tool without registration requirements.
Step 2: Search for Data Converter Tool
Use the search functionality or navigate through the Data Conversion section in the sidebar. Click on “Data Converter” to access the conversion interface.
Step 3: Select JSON → TOON
Configure the conversion settings:
1. Input type: Select “JSON” from the dropdown
2. Output type: Select “TOON” from the dropdown
The interface automatically detects your format preferences and adjusts accordingly.
Step 4: Input Your JSON Data
You have three options for providing source data:
1. Write directly: Paste your JSON into the input text area. This works best for quick tests or small datasets.
2. Upload from local: Click the upload button to select JSON files from your computer. Handles files up to several megabytes efficiently.
3. Upload from Google Drive: Connect your Google Drive account to access and convert JSON files stored in the cloud.
Step 5: Convert
Click the “Convert” button. The system processes your JSON and generates the TOON equivalent instantly—typically completing in under a second even for datasets with thousands of records.
The output appears immediately in the results panel. You can:
1. Copy the TOON output to your clipboard
2. Download it as a .toon file
Compare token counts between formats using the built-in statistics
This web-based approach lets you validate token savings before implementing TOON in your production code. Test with real data, verify accuracy, and measure actual token reduction for your specific use cases.
Implementing TOON in Your Stack
TOON has matured into production-ready implementations across major programming languages.
TypeScript/JavaScript
npm install @toon-format/toonimport { encode, decode } from '@toon-format/toon';
const data = {
users: [
{ id: 1, name: 'Alice', role: 'admin' },
{ id: 2, name: 'Bob', role: 'user' }
]
};
// Encode to TOON
const toon = encode(data);
// Use with your LLM
const prompt = `Given this data:\n${toon}\n\nHow many admins?`;
// Decode responses
const result = decode(toonResponse);
Python
pip install toon-formatimport toon
data = {
"users": [
{"id": 1, "name": "Alice", "role": "admin"},
{"id": 2, "name": "Bob", "role": "user"}
]
}
# Encode to TOON
toon_data = toon.encode(data)
# Construct prompt
prompt = f"Analyze this data:\n{toon_data}\n\nList all roles."
# Decode results
result = toon.decode(response)
Alternative Delimiters
TOON supports comma (default), tab, and pipe delimiters. Tab delimiters often provide additional token savings:
encode(data, { delimiter: '\t' })employees[2 ]{id name role}:
1 Alice admin
2 Bob user
...Tab characters tokenize efficiently and rarely appear in natural text, reducing quote-escaping requirements.
Key Folding
For deeply nested data with single-key wrapper chains, enable key folding to collapse structure:
encode(data, { keyFolding: 'safe' })Standard nesting:
data:
metadata:
items[2]: a,b
With key folding:
data.metadata.items[2]: a,b
This reduces indentation levels and saves tokens without losing information.
Production Considerations
Encoding and decoding overhead remains minimal—typically microseconds for datasets under 1MB. The performance cost of format conversion usually disappears compared to network latency and LLM processing time.
For high-throughput systems processing thousands of requests per second, benchmark your specific workload. The token savings from reduced payload size typically outweigh any conversion overhead.
Error Handling
TOON’s strict mode (enabled by default) validates:
- Array length declarations match actual element counts
- Field counts match declared schema
- Delimiter consistency across rows
- Proper escape sequences in strings
This validation catches data corruption, truncation, or parsing errors before they reach your LLM. For scenarios requiring lenient parsing, disable strict mode:
decode(toonData, { strict: false })
Prompt Engineering
When using TOON with LLMs, explicit instructions improve results:
Data is in TOON format (2-space indent, arrays show length and fields).
users[3]{id,name,role}:
1,Alice,admin
2,Bob,user
3,Carol,viewer
Task: Return only admin users as TOON. Match the same header format.
The model understands the structure from examples. Explicit formatting instructions reduce generation errors.
Migration Strategy
Adopt TOON incrementally:
- Measure baseline: Use OpenAI’s tokenizer to count tokens in your current JSON payloads
- Convert and compare: Test TOON conversion with real data to validate savings
- A/B test: Run parallel experiments comparing response quality and cost
- Start with non-critical features: Deploy TOON in low-risk areas first
- Expand based on results: Scale usage as confidence and savings materialize
The Future of Data Formats for AI
TOON represents broader recognition that AI systems require different optimizations than traditional web APIs. Several trends point toward continued evolution:
- Model-specific tokenization: Future formats might optimize for specific tokenizer implementations rather than universal human readability.
- Streaming optimizations: Formats designed for token-by-token streaming rather than complete document transmission.
- Native LLM generation: Formats explicitly designed for models to generate efficiently, not just consume.
- Hybrid compression: Combining algorithmic compression with semantic structure preservation.
JSON won’t disappear—it remains the right choice for countless use cases. But as AI systems process increasing data volumes, specialized formats like TOON will become standard tools in the developer toolkit.
Recommendations
Based on extensive benchmarking and production deployment experience:
- Start measuring now: Calculate your current token costs. You can’t optimize what you don’t measure.
- Test with real data: Convert actual production payloads to TOON and compare token counts using your target model’s tokenizer.
- Focus on high-volume endpoints: Prioritize optimization where you process the most tokens—often batch analytics or high-frequency API endpoints.
- Validate response quality: Run A/B tests comparing model outputs from JSON vs TOON to ensure accuracy remains consistent.
- Consider hybrid deployment: Use JSON for public APIs and internal logic, TOON specifically for LLM interactions.
- Monitor continuously: Token pricing and model capabilities evolve rapidly. Reassess format choices quarterly.
- Enable caching strategically: Many LLM providers offer prompt caching—frequently reused TOON schemas benefit significantly from cache hits.
TOON delivers measurable value when applied to the right use cases. The 30-60% token reduction translates directly to cost savings and faster response times in token-sensitive AI applications. For production systems processing substantial data volumes through LLMs, TOON has matured into a reliable optimization worth evaluating.
The format specification remains open and actively maintained, with implementations across major programming languages continuously improving. Whether you’re optimizing costs, improving latency, or simply exploring better ways to structure data for AI systems, TOON deserves consideration in your technical decision-making process.
Resources and Further Reading
- Official TOON Specification: github.com/toon-format/spec
- TypeScript Implementation: github.com/toon-format/toon
- Python Implementation: github.com/toon-format/toon-python
- Interactive Playground: toontools.vercel.app
- Format Comparison Tool: curiouslychase.com/playground/format-tokenization-exploration
The AI development landscape continues evolving rapidly. Formats, pricing models, and optimization strategies shift regularly. Test thoroughly with your specific use cases, measure results objectively, and adapt based on data rather than assumptions.







