Large Language Models (LLMs) stand at the forefront of artificial intelligence (AI) advancements, transforming how machines understand and generate human language. These models, built upon vast datasets and complex algorithms, have the remarkable ability to mimic human writing styles, answer questions, and even create content that feels authentically human. This article aims to demystify the inner workings of LLMs. We will start by exploring the structural and algorithmic foundations that enable these models to process and produce language. Following that, we will delve into how these models function post-creation, including their application in various tasks. Our goal is to provide a clear, concise explanation of Large Language Models, making this cutting-edge technology accessible to all.
What is a Language Model?
A language model is a type of machine learning model trained to conduct a probability distribution over words. It predicts the next most appropriate word to fill in a blank space in a sentence or phrase, based on the context of the given text. Language models are used in natural language processing (NLP) tasks, such as speech recognition, text generation, chatbots, machine translation, and parts-of-speech tagging.
By analyzing vast amounts of text, language models learn the patterns of human language, enabling machines to understand and generate text that is coherent and contextually relevant.
There are several types of language models:
- Large Language Models (LLMs): Large Language Models are characterized by their extensive training datasets and a high number of parameters, often ranging in the billions. These models can comprehend and produce text with a high degree of sophistication, capturing nuances in language that smaller models may miss. LLMs are versatile and capable of performing a wide array of NLP tasks without needing task-specific training.
- Very Large Language Models (VLLMs): Expanding upon LLMs, Very Large Language Models take the scale to another level, with parameters reaching into the trillions. These models achieve even greater understanding and fluency in language processing, setting new benchmarks for AI’s capability in understanding context and generating human-like text. VLLMs require significant computational resources for training and operation, which limits their accessibility to organizations with substantial infrastructure.
- Small Language Models: Small Language Models, in contrast, have fewer parameters and require less computational power to train and run. While they may not match the depth of understanding of their larger counterparts, they are efficient and sufficiently effective for specific applications where resources are limited or real-time performance is crucial.
- Fine-Tuned Language Models: Fine-tuned Language Models start with a pre-trained model, which is then further trained on a smaller, specialized dataset. This process allows the model to retain its broad linguistic capabilities while honing its expertise in a specific domain, such as legal language or medical terminology. Fine-tuning enables a balance between the general applicability of large models and the specialized knowledge required for particular tasks.
- Edge Language Models: Edge Language Models are designed to run on devices at the edge of the network, such as smartphones and IoT devices, rather than centralized servers. These models are optimized for low latency, reduced power consumption, and minimal computational requirements. Edge Language Models enable real-time processing and responses in applications like virtual assistants and language translation services on mobile devices.
Each type of language model serves different needs and applications, from the broad and powerful capabilities of VLLMs to the specialized and efficient nature of edge models. Understanding these distinctions is crucial for selecting the right model for a given application, and balancing the trade-offs between computational resources, performance, and task specificity.
Also Read: How to create Local AI platform with Ollama and Open WebUI?
Structure of Large Language Models:
Now that we’ve got the basic idea of Large Language Models (LLMs), let’s see the structure of an LLM model. Understanding the architecture of these models is crucial as it lays the groundwork for their ability to understand and generate human language with remarkable accuracy.
The architecture of LLMs:
The architecture of Large Language Models (LLMs) like Google’s GEMINI, GPT (Generative Pre-trained Transformer) and BERT (Bidirectional Encoder Representations from Transformers) is grounded in the Transformer architecture, which represents a departure from earlier sequence modelling approaches such as RNNs (Recurrent Neural Networks) and CNNs (Convolutional Neural Networks). The Transformer architecture’s efficacy and efficiency stem from its unique components and the way they interconnect to process language at scale. Here, we’ll dissect this architecture, focusing on the sequential development of its components and their interconnected roles.
- Input Embedding Layer:
The architecture begins with the Input Embedding Layer, where raw text inputs are converted into fixed-size vectors. This layer maps each word or subword token to a high-dimensional space, facilitating numerical manipulation. The embedding vectors carry semantic information, where similar words have similar embeddings. - Positional Encoding:
Since Transformers do not process data sequentially like RNNs, they require a method to incorporate the order of words into their model. Positional Encoding is added to the embedding layer outputs, providing the model with information about the position of each word in the sequence. This enables the model to maintain word order awareness, crucial for understanding language structure. - Self-Attention Mechanism:
At the heart of the Transformer architecture lies the Self-Attention Mechanism. This component allows the model to weigh the importance of different words in the sentence, regardless of their positional distance. For each word, the model calculates a set of queries, keys, and values through linear transformations of the embeddings. The attention mechanism then uses these queries, keys, and values to produce a weighted representation of the input, focusing on how each word relates to every other word in the sequence.
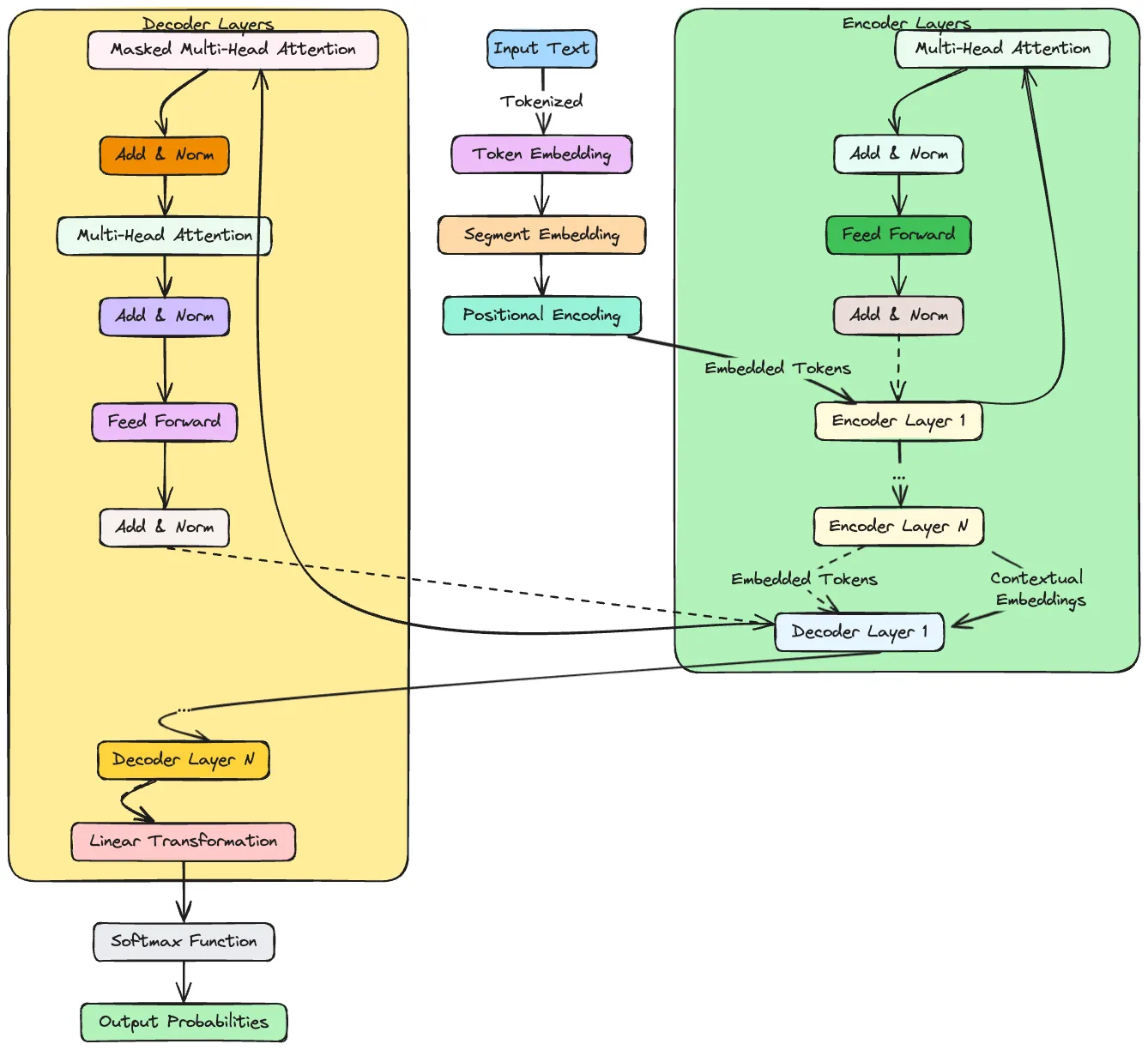
- Attention Outputs to Feed-Forward Neural Networks:
The output from the self-attention mechanism is passed to a Feed-Forward Neural Network (FFNN) within each layer. Despite the name, the FFNN is applied separately and identically to each position, ensuring that the model can still parallelize processing. The FFNN consists of two linear transformations with a ReLU activation in between, allowing for further complexity and depth in processing the relationships identified by the self-attention mechanism. - Residual Connections and Layer Normalization:
To facilitate the training of deep models, each sublayer (self-attention, FFNN) in the architecture includes a residual connection around it, followed by layer normalization. The residual connections help mitigate the vanishing gradient problem by allowing gradients to flow through the network directly. Layer normalization stabilizes the learning process by normalizing the inputs across the features. - Encoder-Decoder Structure:
In models like GPT, which are primarily used for generative tasks, the focus is on the decoder side of the Transformer, which predicts the next word in a sequence given the previous words. BERT, aimed at understanding tasks, utilizes the encoder part to process input tokens altogether. The encoder maps the input sequence to a sequence of continuous representations, which the decoder then transforms into an output sequence. The connection between the encoder and decoder in models that use both is facilitated by additional attention layers where the decoder attends to the encoder’s output. - Output Layer:
Finally, the decoder’s output passes through a final linear layer, often followed by a softmax layer to predict the probability distribution of the next word in the sequence. This output layer maps the decoder output to a word in the vocabulary, completing the process of generating text.
The architecture of LLMs, rooted in the Transformer model, represents a complex but elegantly designed system where each component serves a specific purpose, from understanding the semantics and syntax of the input language to generating coherent and contextually relevant language outputs. This intricate structure, through its self-attention mechanisms, positional encoding, and layer-wise processing, equips LLMs with their powerful language processing capabilities. The modular nature of this architecture allows for flexibility and adaptability in various NLP tasks, making it a cornerstone of modern AI language models.
Also Read: How does Sora work?
Parameters of Large Language Models
In the context of Large Language Models (LLMs), parameters are the fundamental components that the model uses to make predictions and generate text. These are the learned aspects of the model that define its behaviour. Understanding the scale and function of parameters is crucial to comprehending how LLMs operate.
- Parameters in Context:
- Parameters are the elements of the model that are optimized during the training process. They are akin to the synapses in the human brain, storing learned information.
- Each parameter represents a weight that the model uses to make decisions about which words or phrases are likely to follow a given input.
- Parameters as Knowledge Storage:
- The parameters of an LLM effectively encode knowledge about language patterns, grammar rules, common phrases, and the context in which words are used.
- Through training, the model adjusts these parameters to minimize the difference between its predictions and the actual outcomes (i.e., the ground truth).
- Scale of Parameters:
- The size of an LLM is often defined by the number of its parameters, which can range from millions in smaller models to hundreds of billions or even trillions in the most advanced models today.
- More parameters allow the model to capture more nuanced patterns in data, but they also require more computational resources to train and operate.
- Parameters and Model Capability:
- A model with a larger number of parameters generally has a higher capacity to understand and generate complex text.
- However, there is a point of diminishing returns where adding more parameters does not significantly improve performance and can even lead to issues like overfitting, where the model performs well on training data but poorly on new, unseen data.
- Training and Tuning of Parameters:
- During training, models use algorithms like stochastic gradient descent and backpropagation to adjust parameters and reduce prediction error.
- Parameters are tuned based on the model’s performance on a validation dataset, which helps to ensure that the model generalizes well to new data.
- Finalization of Parameters:
- Once training is complete, the final set of parameters defines the trained model.
- These parameters are then fixed when the model is deployed, although some models may undergo additional fine-tuning for specific tasks or domains.
Parameters are the essence of an LLM’s learning capability, serving as the repository for all the linguistic information the model needs to function. Their optimization is a delicate balance between capacity and generalizability, requiring careful tuning to ensure the model can perform a wide array of language tasks effectively. Understanding the role and scale of parameters is key to grasping the potential and limitations of LLMs in various applications.
The Algorithm Behind Large Language Models:
Now that we’ve gained insight into the architecture of an LLM model, let’s explore the main algorithm behind its creation. The process is complex, involving a series of stages where the model learns from vast amounts of data. Next, we will dissect the training process, where the initial parameters are honed into a sophisticated set of weights, enabling the model to understand and generate human language. This is where the architecture comes to life, informed by the algorithm that drives learning and prediction.
Training Process
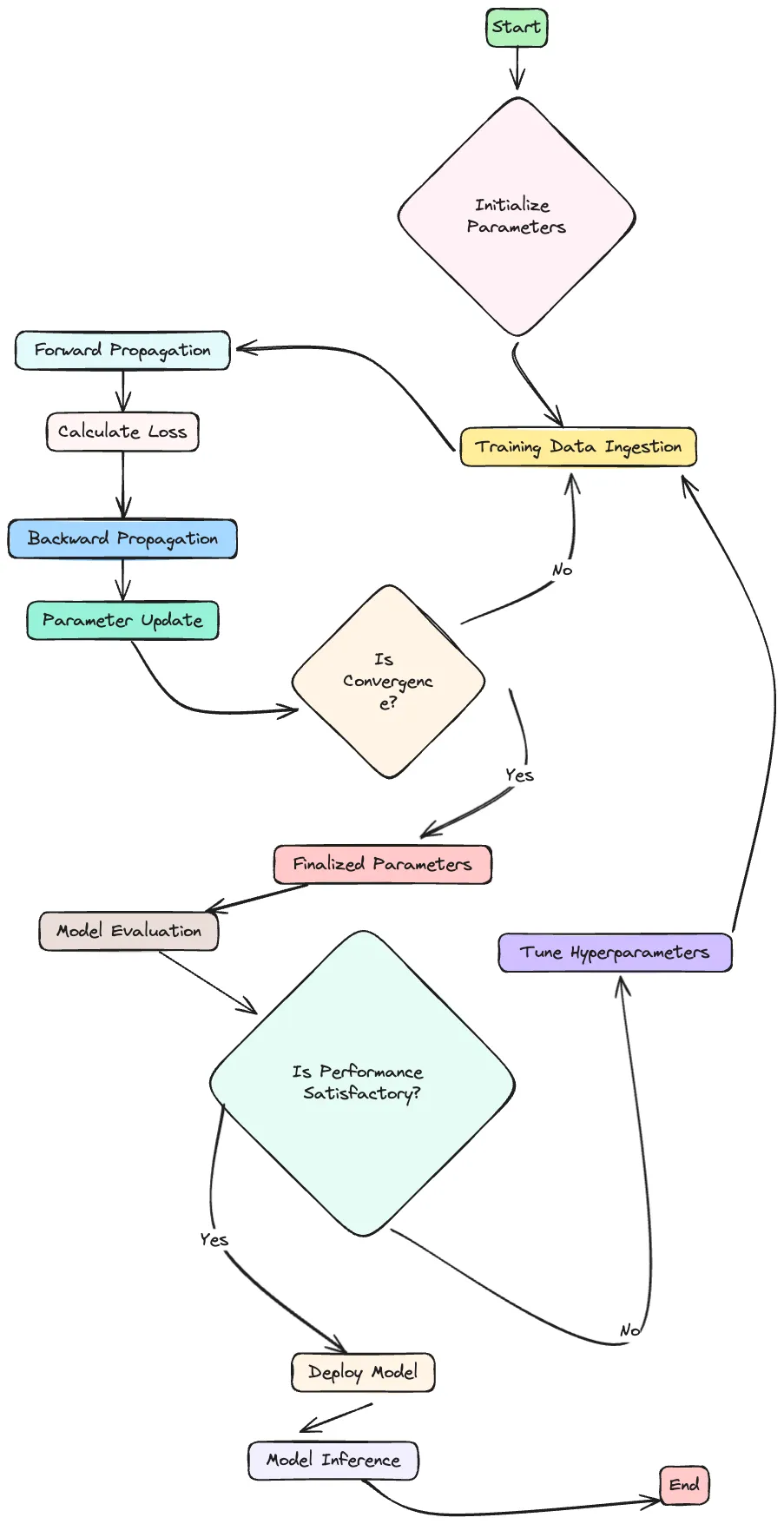
The training process is where raw data transforms into a sophisticated understanding of language, equipping the model with its predictive power. Let’s delve into this training process to see how it shapes an LLM model.
Data Preparation and Preprocessing:
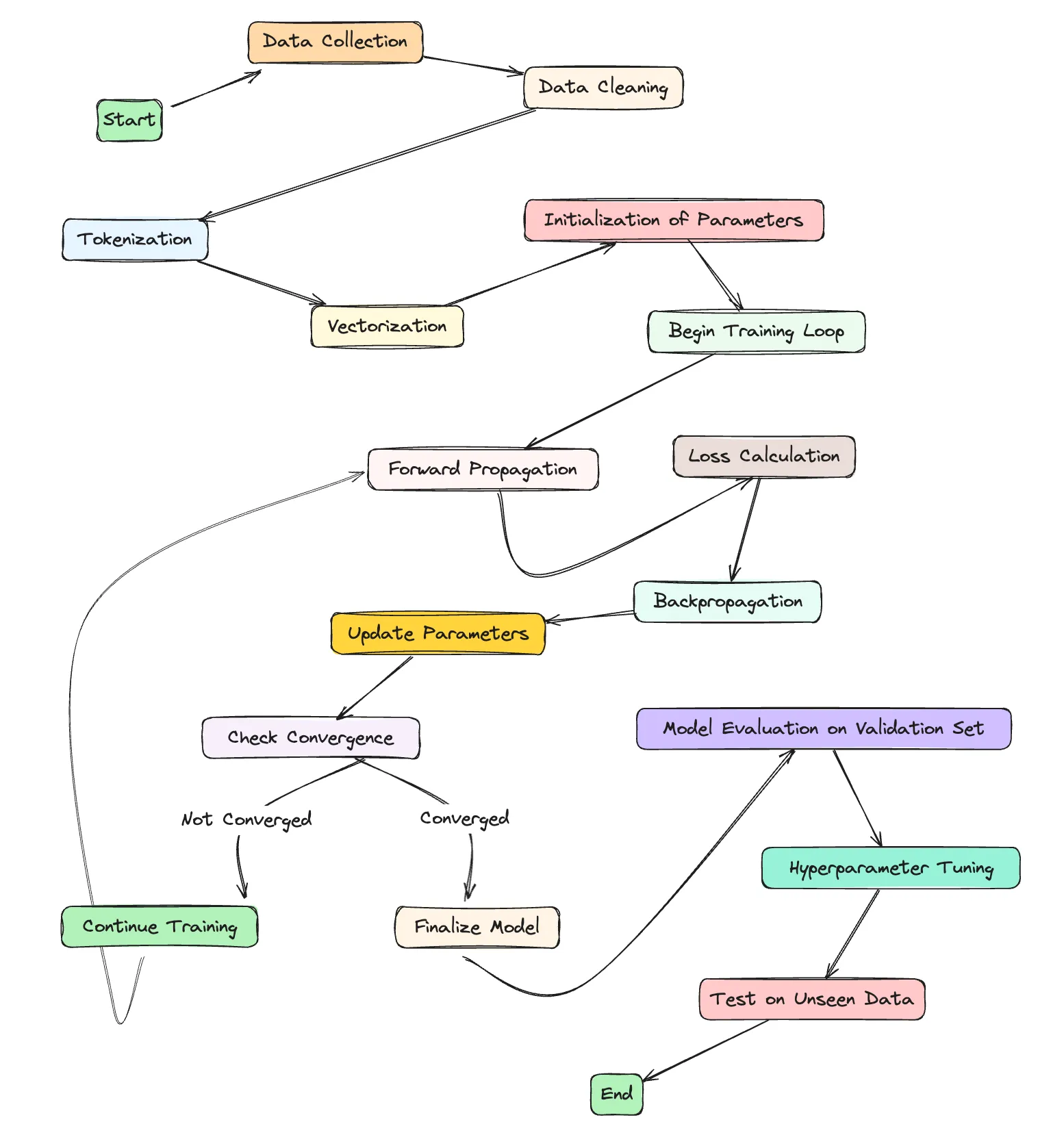
- Data Collection: The first step in the training process involves gathering a large and diverse dataset, which typically includes text from books, websites, and other media. This dataset must be vast to cover the intricacies of human language.
- Data Cleaning: Once collected, the data undergoes cleaning to remove errors, inconsistencies, and irrelevant information. This step ensures that the model learns from high-quality data.
- Tokenization: The clean data is then tokenized, breaking text into smaller pieces, such as words, subwords, or characters. This tokenization allows the model to process and learn from the data efficiently.
- Vectorization: The tokenized text is converted into numerical form, typically using embedding techniques. Each token is represented by a vector that captures its semantic and syntactic properties.
Model Learning:
- Initialization: The model’s parameters, which include weights and biases, are initialized. This could be random initialization or starting from the parameters of a pre-trained model.
- Forward Propagation: During forward propagation, the model uses its current parameters to make predictions. For example, in a language model, this would involve predicting the next word in a sentence.
- Loss Calculation: The model’s predictions are compared to the actual outcomes, and a loss function is used to quantify the model’s errors.
- Backpropagation: The loss is then backpropagated through the model, which involves computing the gradient of the loss function for each parameter.
Optimization
- Gradient Descent: Using the gradients, the model’s parameters are updated with the goal of minimizing the loss. This is typically done using optimization algorithms like stochastic gradient descent (SGD) or variants like Adam.
- Epochs and Batching: The model iterates over the entire dataset multiple times, each iteration being an epoch. Data is often processed in batches to make computation more manageable and efficient.
- Regularization and Dropout: Techniques like regularization and dropout are used to prevent overfitting, ensuring the model generalizes well to new, unseen data.
- Hyperparameter Tuning: Throughout the training process, hyperparameters—such as the learning rate, batch size, and number of layers—are tuned to optimize performance.
Validation and Testing
- Validation: Alongside training, the model’s performance is regularly evaluated on a separate validation dataset. This helps monitor for overfitting and guide hyperparameter tuning.
- Testing: Once the model has been trained and validated, its performance is assessed on a testing dataset that it has never seen before, providing a final measure of how well it has learned to predict or generate language.
This process is iterative and requires careful calibration to balance the model’s complexity with its ability to learn from diverse linguistic patterns.
Learning and Predicting
Once a Large Language Model (LLM) has undergone the initial training process, it enters a phase of continuous learning and prediction, honing its capabilities to understand context and generate language. This stage is crucial, as it is where the model turns theoretical knowledge into practical application.
Understanding Language
- Pattern Recognition: LLMs learn by recognizing patterns in the data they were trained on. This includes syntactic patterns like grammar and sentence structure, as well as semantic patterns like word associations and context.
- Contextual Understanding: Through mechanisms like attention, LLMs can understand the context within which words are used. This means not just understanding a word in isolation but how its meaning can change with surrounding text.
- Generalization: A key aspect of learning is generalization, which allows LLMs to apply learned patterns to new, unseen data. This ability is what makes LLMs valuable for a wide range of tasks beyond just those they were explicitly trained on.
Making Predictions
- Probabilistic Modeling: LLMs predict the probability of a word or sequence of words following a given input. This is done using the parameters refined during training to model the language statistically.
- Sampling and Decoding: To generate text, the LLM uses sampling methods to choose the next word based on the probabilities it has predicted. Decoding strategies like greedy decoding or beam search can be used to select words in a way that balances randomness and accuracy.
- Refinement with Feedback: Predictions are continuously refined through feedback. When an LLM is used in the real world, it may receive user feedback or additional training to correct errors and improve over time.
Adaptation to Tasks
- Transfer Learning: LLMs are often designed to be adaptable through transfer learning. This means a model trained on a general dataset can be fine-tuned on a specific task, allowing for customization without starting from scratch.
- Fine-Tuning: Fine-tuning involves additional training on a smaller, task-specific dataset. This allows the LLM to become specialized in tasks such as translation, question answering, or even creative writing.
- Continuous Improvement: As LLMs are exposed to more data and use cases, they can continue to learn and improve. This continuous improvement cycle is what enables LLMs to stay relevant and effective over time.
The phases of learning and predicting form the crux of an LLM’s functionality. It’s where abstract algorithms are translated into concrete linguistic competence. LLMs not only learn from the vast datasets they’re trained on but also constantly refine their predictions, ensuring that the language they generate or interpret is as natural and accurate as possible. This ongoing process of learning and adaptation is what allows LLMs to perform a diverse array of complex language tasks with increasing precision.
From Creation to Application
Large Language Models (LLMs) have revolutionized the field of Natural Language Processing (NLP) by demonstrating remarkable capabilities in understanding and generating human-like text. This section will delve into the creation, fine-tuning, deployment, and interaction aspects of LLMs, focusing on the role of models like GPT-3 and BERT, the Transformer architecture, ethical considerations, and limitations.
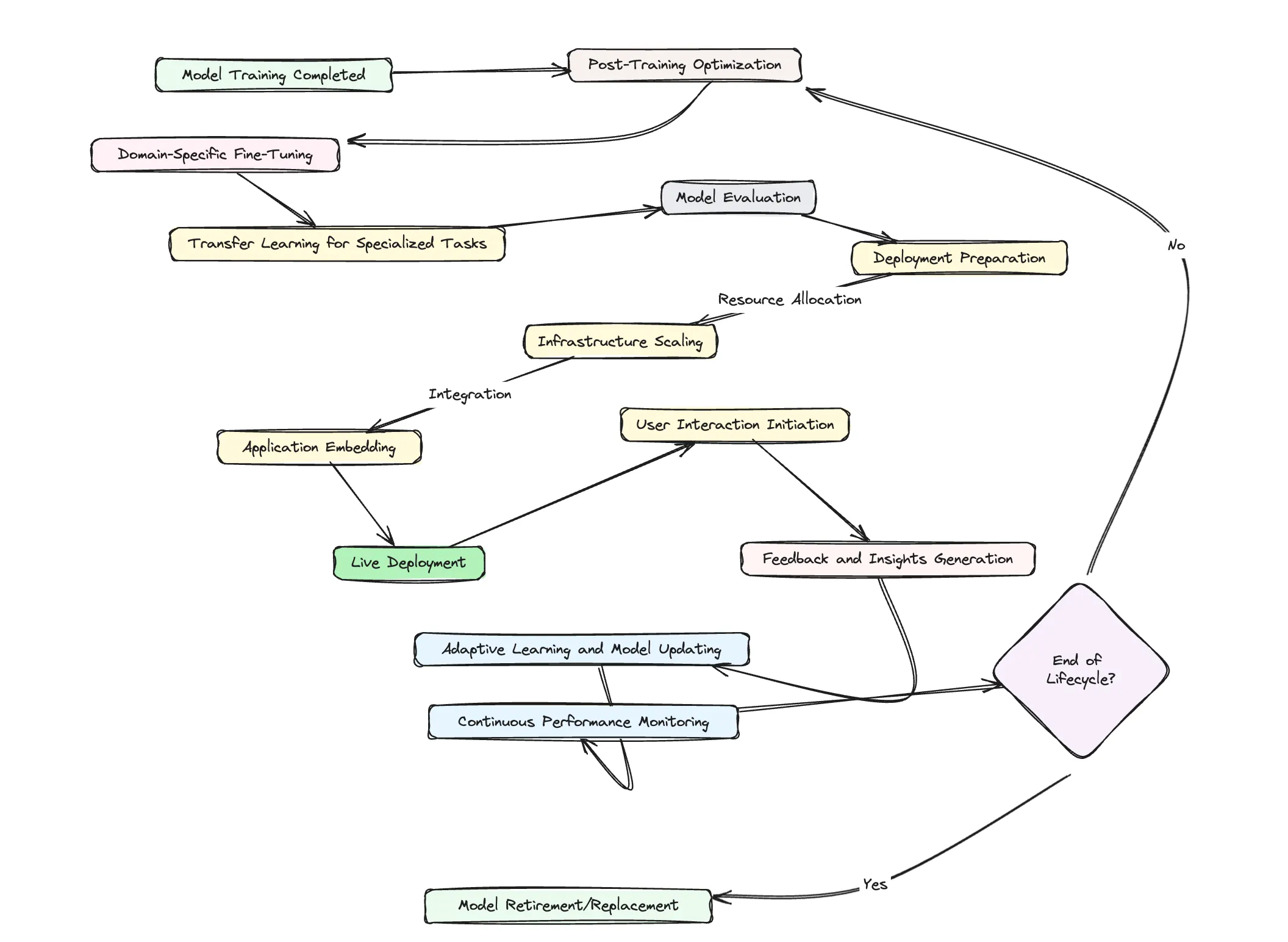
Post-Training
Upon completing their intensive training regimes, LLMs undergo a transition phase—post-training. This stage is tailored to refine the model’s grasp over specific subject areas or applications. It is where the broad knowledge base of an LLM is honed for particular functionalities, such as legal terminology comprehension or poetic verse generation. Post-training includes fine-tuning with datasets enriched in the relevant context, enhancing the model’s proficiency in the chosen domain. Moreover, this phase often employs transfer learning, enabling the LLM to pivot its generalized learning to tackle specialized tasks more effectively.
Deployment
The deployment of LLMs into real-world scenarios is a nuanced operation. It encompasses the strategic integration of these models into various digital platforms, from simple chat interfaces to complex predictive engines that can underpin customer service operations. During deployment, consideration of computational demands is paramount. Models like GPT-3 require substantial resources to generate billions of words daily. The infrastructure, therefore, must not only be robust but also scalable to accommodate growing data traffic and complex query resolutions. Efficiently deploying an LLM demands a seamless orchestration of hardware and software, ensuring that the AI’s prowess is delivered where and when it is needed without compromising performance.
Interaction
The interface between LLMs and users is where the culmination of training and deployment is truly tested. Users typically engage with these models via prompts, expecting coherent and contextually appropriate responses. In applications like customer feedback analysis, LLMs demonstrate their utility by sifting through vast datasets to extract sentiment, trends, and actionable insights. This interaction is not static; it is an ongoing dialogue where the LLM is often expected to learn and adapt to new patterns of speech and emerging topics. However, this adaptive learning is meticulously managed to prevent the assimilation of biased or incorrect information, maintaining the integrity of the model’s outputs.
In essence, the journey from the creation of LLMs to their application is marked by a continuous refinement of knowledge and adaptability. It is a testament to the transformative potential of AI in our digital landscape, where LLMs are not just tools but partners in progress. The interactivity with users does not signify the end of this journey; rather, it is a perpetual cycle of learning, application, and evolution.
Challenges and Ethical Considerations
Creating a detailed exploration of the challenges and ethical considerations associated with Large Language Models (LLMs) involves addressing several critical issues. Below is a structured approach to presenting these topics in a table format. This format allows for a concise yet comprehensive overview of each concern, its implications, and potential future directions for mitigation.
| Challenge/Ethical Consideration | Implications | Mitigation Strategies |
|---|---|---|
| Computational Costs | The training of LLMs requires significant computational resources, leading to high energy consumption and associated costs. | Optimizing algorithms for efficiency, using more energy-efficient hardware, and exploring methods to reduce the size of models without compromising their effectiveness. |
| Environmental Impact | The carbon footprint associated with the energy consumption of training and operating LLMs is a concern, contributing to global carbon emissions. | Leveraging renewable energy sources for data centers, improving data center energy efficiency, and considering the environmental impact in the model design phase. |
| Bias in Model Outputs | LLMs can perpetuate or even amplify biases present in their training data, leading to unfair or prejudiced outcomes. | Implementing more rigorous data curation practices, developing techniques for bias detection and mitigation in models, and diversifying the datasets. |
| Misinformation | The ability of LLMs to generate convincing text can be misused to create and spread misinformation or fake content. | Developing and incorporating fact-checking mechanisms into LLMs, establishing clear guidelines for responsible use, and creating detection tools for synthetic text. |
| Privacy Concerns | LLMs trained on vast datasets may inadvertently memorize and reproduce sensitive information, leading to privacy breaches. | Applying techniques such as differential privacy during training, regularly auditing models for privacy compliance, and anonymizing data sources. |
The ongoing development of LLMs brings with it a commitment to addressing these challenges. Research and innovation are key to finding effective solutions that can minimize the negative impacts while maximizing the benefits of these powerful models. For instance, advancements in AI efficiency and responsible AI practices are already showing promise in reducing the environmental footprint and ensuring fair and unbiased outcomes. Similarly, the AI community is actively exploring ethical frameworks and governance models to guide the development and use of LLMs in a way that respects privacy and prevents misuse.
Continued collaboration between technologists, ethicists, policymakers, and other stakeholders is crucial to navigating the complex landscape of ethical considerations. By fostering an open dialogue and prioritizing transparency, the field can move towards sustainable and ethical AI development that benefits all of society.
Conclusion
In wrapping up our analysis of Large Language Models (LLMs), it’s clear these technologies mark a significant advance in artificial intelligence, profoundly changing how we interact with digital information. LLMs have introduced capabilities that span from generating complex written content to understanding nuanced human queries, demonstrating immense potential across various domains. However, this exploration has also highlighted substantial challenges, including computational demands, environmental impacts, and ethical dilemmas like bias, misinformation, and privacy concerns.
Addressing the dual aspects of opportunity and responsibility is crucial. Optimizing LLMs for efficiency, ensuring fairness, and safeguarding privacy are immediate priorities. The future direction involves not only technological innovation but also ethical stewardship and collaborative regulation to balance the benefits against the potential harms.
As we continue to advance, the focus must remain on leveraging LLMs in a way that benefits society broadly, keeping in mind the importance of sustainability, fairness, and transparency. The journey of LLMs is a testament to human ingenuity and a reminder of our responsibility to guide this technology towards positive outcomes.







