
Large Language Models (LLMs) like ChatGPT, Google’s Bard/SGE, Perplexity, and Claude have completely changed how people discover information online. And with that shift, the SEO world is scrambling for ways to “show up” inside these AI answers.
One idea that’s been making noise lately is the llms.txt file — pitched as a kind of “robots.txt for AI.” The theory sounds tempting: drop a file at your site’s root, list out your best content in a neat format, and AI systems will magically pick it up and cite you.
But here’s the thing: I’ve dug into this, checked what’s being said, looked at server logs, and the reality doesn’t match the hype. No major AI system is actually using llms.txt to rank or cite content right now. To me, chasing this trend feels like a distraction from the things that actually move the needle in Answer Engine Optimization (AEO).
In this post, I’ll share why llms.txt isn’t the silver bullet some people want it to be, what Google’s John Mueller had to say about it, and where I think SEOs and content creators should really be focusing if they want to get noticed in AI-driven answers.
What Is LLMs.txt and Where Did the Idea Come From?
LLMs.txt is a proposed new standard (emphasis on proposed) for making web content more accessible to LLM-based AI assistants. The concept was introduced in late 2024 by Jeremy Howard (fast.ai) as a simple Markdown file at your website’s root (yourdomain.com/llms.txt) that provides an LLM-friendly guide to your content. Think of it as a hand-crafted sitemap for AI: it would highlight key pages or sections of your site in plain text, minus all the HTML navigation clutter, to help an AI “understand” the structure and find the main content.
You can read the full proposal on llmstext.org.
Despite the name similarity, LLMs.txt is not a crawler control file like robots.txt. It doesn’t block or allow bots from anything. Instead, it’s more like a menu or map of your high-value content that you want AIs to ingest and possibly cite. For example, you might list your most in-depth guides, product FAQs, or API docs in llms.txt with links to simplified (maybe Markdown) versions. The hope is that an AI agent reading your site during inference (answer generation) would see that file, go “Oh, here’s the important stuff,” and use it to provide better answers or attribute you as a source.
The idea gained traction among some technologists and SEOs in early 2025. Proponents likened it to giving AI a treasure map: “Here be gold – cite this content from my site.” Enthusiasts pointed out that the Agents to Agents (A2A) protocol from Google’s experimental projects even included an llms.txt example, hinting at future support. Some startups (like Mintlify and Profound) began advocating “Generative Engine Optimization (GEO)” and claimed that early data showed benefits to providing simplified content files (even an llms-full.txt containing full site text) for LLM consumption. On the surface, it sounds exciting – a new way to optimize for AI and get ahead of the curve.
However, it’s critical to note that LLMs.txt remains a voluntary proposal, not an official web standard. Unlike sitemaps or robots directives (which have RFCs and broad agreement), llms.txt is an idea still in flux. It was never about telling AI bots what not to do (as robots.txt does), but about giving them a helping hand to find content. And that leads to the big question: are any AI systems actually looking for that helping hand?
LLMs.txt vs Robots.txt vs Sitemap.xml
It’s easy to hear “LLMs.txt” and assume it functions like a robots.txt for chatbots. In reality, the analogy doesn’t hold. Robots.txt is an established standard used for decades by search engines (Google, Bing, etc.) to know which URLs they are allowed or disallowed to crawl. Major crawlers automatically request robots.txt from a site and obey its rules. To put a contrast on it, LLMs.txt has no such enforcement or widespread adoption. It’s not about controlling anything – it’s essentially a suggestion file with no guarantee any bot will ever read it.
To clarify the differences:
| Feature / Purpose | Robots.txt | LLMs.txt | Sitemap.xml |
|---|---|---|---|
| Primary Role | Crawler exclusion protocol – controls which parts of a site bots can or cannot access | Curated content list – highlights “important” pages in a simplified format | URL index – provides a complete list of site URLs for search engines |
| Adoption & Standards | Long-standing web standard, universally supported by Google, Bing, etc. | Experimental proposal, no adoption by major LLMs (as of 2025) | Widely accepted standard; actively used by Google, Bing, and others |
| Enforcement | Mandatory: bots are expected to check and obey Disallow/Allow rules | Optional: no AI or LLM is required to read or follow it | Strongly encouraged: search engines routinely fetch and use it |
| Controls Access? | Yes – can block or allow crawling of specific paths | No – cannot block or allow access; does not prevent scraping | No – simply provides URLs for indexing; doesn’t block crawling |
| Format | Plain text file with rules | Markdown/text file with links to preferred content | XML file structured for search engine parsing |
| Current Use Cases | Managing crawl budget, preventing sensitive/irrelevant pages from being crawled | Theoretical shortcut for AI agents to “find” key content | Helping search engines discover and index all site pages |
| Real-World Impact | Direct and proven: determines what gets crawled or ignored | None: major AI systems don’t check or use it | High: improves indexing speed and coverage in search engines |
| Industry Analogy | Gatekeeper: “Don’t enter these rooms” | Pamphlet: “Here’s what I think matters” (AI can ignore it) | Directory: “Here’s the full map of the building” |
In short, `llms.txt is not a magic switch for AI crawling or ranking. It doesn’t override how LLMs work internally. LLM answer engines don’t blindly follow webmaster directives the way search crawlers do – they pull information based on their training data and real-time search results, focusing on content quality and relevance. A file you host on your site telling them “here’s my best stuff” has no binding power. It’s more like leaving a pamphlet on your doorstep hoping a passing AI postman will pick it up – but no one’s sure the postman even walks that route.
Who Is Using llms.txt?
Let’s break it down—some organizations are rolling with llms.txt, but major AI platforms are staying on the sidelines.
Who are the early adopters?
- Documentation platforms like Mintlify helped kick off adoption when they enabled
llms.txtacross their hosted docs (think Anthropic, Cursor), adoption jumped massively. - Developer-centric brands are showcasing real implementations:
- Anthropic – full, structured files covering API docs and prompt libraries
- Cloudflare – organizes heavy service documentation by product/service areas
- Zapier – lists API endpoint docs cleanly and hierarchically
- Stripe, Youform, Coinbase, Tiptap – all practical
llms.txtusers with distinct approaches (product pages, blog focus, SDKs, description pages)
- Smaller names:
Pinecone, Windsurf, Svelte.dev, Rainbowkit, Wordlift, Hugging Face have rolled outllms.txt—often pushed via Mintlify integrations or custom setup. - Many others: A directory like [directory.llmstxt.cloud] lists hundreds of sites tapping into the standard—indicative of grassroots momentum rather than AI-driven demand.
Here’s where the hype hits the wall:
- OpenAI (GPTBot) – still honors
robots.txt, but does not support or fetchllms.txt - Anthropic (Claude) – publishes its own
llms.txt, but has not confirmed that its crawlers actually use it - Google (Gemini/Bard) – manages AI crawl behavior via
robots.txt(e.g. Google-Extended), and does not referencellms.txt - Meta (LLaMA) – no public crawler guidance, and no sign of
llms.txtusage
But What About the Big AI Providers?
The short answer as of August 2025 is no. Despite the buzz, no major LLM provider or AI search platform has confirmed using llms.txt in their algorithms or crawlers. Google’s John Mueller stated this bluntly in June:
FWIW no AI system currently uses llms.txt.— John Mueller
(@johnmu.com) June 17, 2025 at 5:40 PM
He went on to explain that none of the consumer-facing LLMs or chatbots even bother to request the llms.txt file when they visit sites – something easily verified in server logs. If you put up an llms.txt today, you’ll likely find that GPTBot, Claude’s crawler, Perplexity’s bot – none of them ever download it. (They do routinely fetch your robots.txt, because that’s standard procedure, but they ignore llms.txt.)
It’s telling that Mueller compared llms.txt To the long-defunct keywords meta tag – a hint that it provides no real ranking value. Similarly, an SEO who hosted 20,000 domains reported that “no AI agents or bots are downloading the LLMs.txt files, apart from some niche user agents”. In other words, the only things hitting llms.txt might be curious SEO tools or web scanners, not the AI heavyweights themselves.
Proponents might argue that “support is coming, just wait.” Indeed, early articles in 2025 painted an optimistic picture that OpenAI, Anthropic, and others had “started referencing llms.txt when crawling sites”. Some companies even implemented it on their docs (Anthropic asked a vendor to set up llms.txt for their API documentation, for example) as experiments. But no public commitments have been made by OpenAI, Anthropic, Google, Meta, or Microsoft that their models will honor or use llms.txt in any official way. To date:
- OpenAI – No indication that ChatGPT or GPT-4’s browsing looks for
llms.txt. OpenAI’s own crawler (GPTBot) only adheres torobots.txtand similar standard tags for opt-outs. - Anthropic (Claude) – Aside from the one-off doc site test, no evidence that Claude’s retrieval system generally uses
llms.txt. No public documentation on it. - Google – Google’s Search Generative Experience (SGE) uses Google’s index; it doesn’t send a bot to crawl at answer time but uses indexed content. Google has experimented conceptually (A2A protocol on GitHub includes an example file), yet Google’s official stance via Mueller is that nobody uses it and it’s not needed if you already have good sitemaps.
- Bing/Microsoft – No mention of
llms.txtsupport. Bing Chat and copilots draw from Bing’s indexed search results and trusted sources, not ad-hoc crawling of your site structure. - Perplexity – As an AI search engine, Perplexity uses Bing results and its crawling for specific queries. It does have a user-agent (PerplexityAI) that might hit sites, but there’s no indication it checks for llms.txt. Some findings suggest Perplexity’s bot doesn’t even strictly respect robots.txt in all cases, which implies it’s not looking for new, non-standard files either.
Even SEO plugin makers acknowledge the lack of uptake. Yoast and RankMath, the popular WordPress SEO plugin, added a feature to generate llms.txt for users (“to guide LLMs like ChatGPT to your most important content”), seroundtable.com – jumping on the trend. But right in the announcement of that feature, it’s noted that “no one is using it yet.” This “build it and they will come” approach might be future-proofing, or it might be putting the cart before the horse.
In short, despite the noise, none of the major LLM providers officially adopt or rely on llms.txt. Even when files exist on high-profile domains, they’re not being consumed in any meaningful way by AI systems—just servers or community trackers.
Creating a llms.txt can feel like future-proofing—but remember: there’s a world of difference between publishing a file and having an AI crawl or follow it. Today, use cases are mostly internal or documentation-driven, not AI visibility-driven. The standard is alive in code, not in practice.
So, is llms.txt actually useful?
I think, even if LLMs started reading it, llms.txt still wouldn’t be a game changer.
John Mueller said this pretty bluntly on Reddit:
“AFAIK none of the AI services have said they’re using LLMs.TXT (and you can tell when you look at your server logs that they don’t even check for it). To me, it’s comparable to the keywords meta tag – this is what a site-owner claims their site is about … (Is the site really like that? well, you can check it. At that point, why not just check the site directly?).”
And honestly, I agree with him. If none of the major AI services—OpenAI, Anthropic, Google—are even checking the file, then what’s the point? To me, llms.txt feels redundant. Why would an AI rely on a Markdown list of links when it can already crawl the actual content (and verify it’s not spam)?
Here’s my hypothesis on why it won’t deliver much even if adoption grows:
- Content quality beats text files. AI assistants rank based on relevance and authority, not just because you hand them a curated list.
- No enforcement. Unlike
robots.txt, it’s optional. Bots can ignore it without consequence. - Easy to misuse. Anyone could stuff it with landing pages and call them “high quality.” AIs would still need to fact-check the actual site.
- Not real-time. Most AI answers come from pre-indexed search data, not live crawling. A file sitting on your server won’t even be seen.
- Training confusion. It doesn’t stop or allow model training—that’s still handled via
robots.txtand opt-out policies.
So, in my view, llms.txt is less of a breakthrough and more of a comfort blanket for SEOs who want to feel they have some control over AI visibility. But visibility in answer engines will always come back to the same fundamentals: good content, crawlable sites, and authority.
Then, Why Is Everyone in SEO Talking About llms.txt?
Honestly, I think it comes down to hype and FOMO. Generative AI is shaking up search, and SEOs are desperate for anything that might get their content cited in ChatGPT, Gemini, Perplexity, or other Answer engines. So when llms.txt it showed up, people jumped on it “just in case” — the same way folks once scrambled for voice search or meta keywords.
It also gives a false sense of control. Traditional SEO had levers like keywords and links; AI feels random and opaque. Dropping a file at your root directory feels like doing something to influence AI, even if the bots aren’t listening.
Add in vendors hyping “LLM visibility scores” and tools like Yoast rushing to add llms.txt support, and you’ve got a perfect recipe for buzz. It sounds techy, it’s easy to set up, and it scratches that itch of wanting control.
But to me, this feels like déjà vu. John Mueller even joked that relying on it is like “maybe they’ll use it tomorrow? Maybe I’ll win the lottery tomorrow?” And he’s right. Whenever the SEO industry latches onto a supposed secret weapon without platform support, it usually turns out to be nothing more than a shiny distraction.
What do I think can help you rank in AI answers?
I don’t think chasing llms.txt is worth your time. If you really want visibility in ChatGPT, Bard, Bing Chat, Claude, or Perplexity, the playbook looks a lot like good SEO. The difference is you need to think less about “ranking in Google” and more about “being the source an AI trusts enough to quote.”
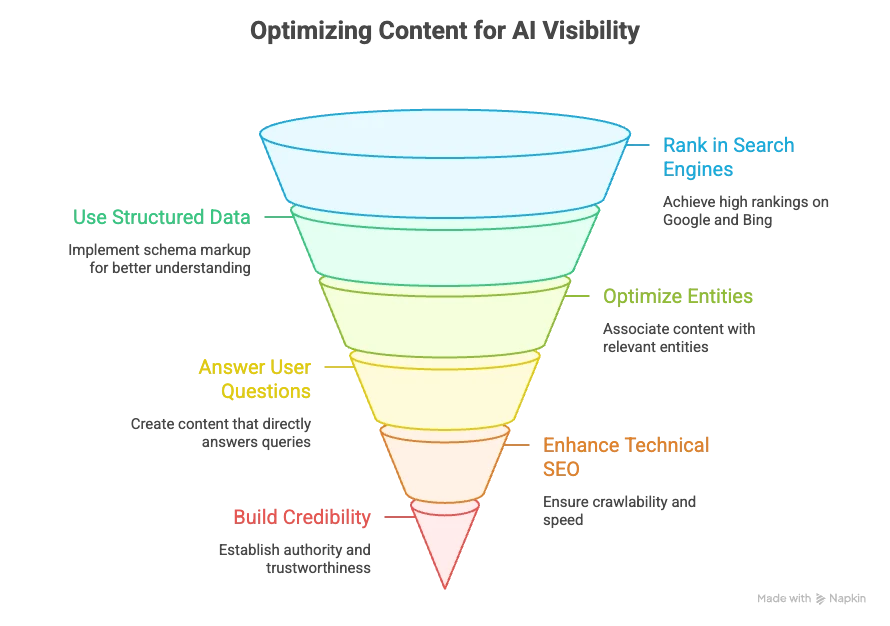
Here’s what I’d focus on instead:
- Rank well in search. Most AI assistants still pull directly from Google or Bing’s top results. If you’re not ranking there, you’re not likely to show up in AI answers either.
- Use structured data. Schema markup (FAQ, HowTo, Product, etc.) and clean semantic HTML help search engines (and by extension, AI systems that rely on them) understand your content faster and more accurately.
- Optimize for entities. AI cares about connections. Make sure your content and brand are linked to relevant entities in knowledge graphs, Wikipedia, and authoritative sources. It’s about proving authority, not just claiming it.
- Answer real questions. Users ask AIs in natural language. Write clear, direct answers to those questions on your site. Think FAQ-style, not fluff. If your content buries the answer, the AI will likely quote someone else.
- Fix technical SEO. Crawlability, speed, and accessibility matter. If an AI bot times out or can’t parse your page, it won’t use it. Keep your site fast, clean, and bot-friendly.
- Build credibility. AIs prefer citing trusted sources. Backlinks, mentions, expert bios, and updated content all send the right signals. Authority is everything here.
- Monitor and refine. Check which sites AI tools are citing for your target queries. If competitors are getting the mentions, study why and adjust your content. This is early days for AEO, so iteration matters.
In my view, this is what real Answer Engine Optimization looks like: doing the hard work of building content that’s clear, authoritative, and easy for machines to interpret. No shortcuts, no gimmicky text files — just solid fundamentals, adapted to the way AI systems fetch and cite information.
Is it going to be bad if I add llms.txt on my website?
I won’t say it’s “bad.” Adding an llms.txt file won’t hurt your site in any way. It’s just a simple Markdown or text file sitting at your root directory — search engines and AI crawlers will ignore it if they don’t care about it.
The real issue isn’t risk, it’s false expectation. Don’t expect traffic boosts, citations, or better AI visibility just because you added it. Think of it as harmless busywork: it won’t break anything, but it also won’t move the needle for AEO.
Conclusion
The buzz around llms.txt is a good reminder that in SEO — and now AEO — there are no shortcuts. We’ve seen this before with meta keywords, quick-fix tags, and other fads that never delivered. A text file isn’t going to suddenly make ChatGPT or Perplexity cite you. Not today, and probably not tomorrow.
For now, the real play is the same as it’s always been: create high-quality content, make it easy for machines to parse, and build authority that AI systems can trust. If you’re doing that, you’ll naturally end up in the pool of sources LLMs pull from. If you’re not, no llms.txt file will save you.
So my advice? Don’t waste cycles on placebo tactics. Put your energy into becoming the best answer in your niche — because that’s what answer engines are looking for.
And hey, if llms.txt does magically become a standard a year from now, you can spin one up in five minutes. But at least by then, you’ll already have the real foundation that matters.
People Also Ask:
Does LLMs.txt actually work? Has anyone seen real results?
Short answer: Not in a measurable way. Multiple threads in r/TechSEO and r/SEO report no meaningful changes in traffic, citations, or AI answer visibility after adding LLMs.txt, with several practitioners calling it “smoke and mirrors” or a distraction until major AI platforms explicitly support it. Google’s representatives have also stated that AI Overviews and Google do not use LLMs.txt; “normal SEO” is still the path for inclusion and visibility in AI features. The consensus from field tests and practitioner posts is that adding the file yields no observable lift in rankings or answer engine mentions today.
Do AI crawlers (ChatGPT, Perplexity, Claude, Gemini) actually read or obey LLMs.txt?
As of mid-August 2025, most AI crawlers don’t check or use LLMs.txt for crawling, ranking, or answer generation, according to community reports and Google guidance. Practitioners routinely note server logs show no LLM bot requests for /llms.txt, and Reddit discussions highlight that even robots.txt is inconsistently respected by some AI crawlers in the wild, let alone a proposed, non-standard file like LLMs.txt. Bottom line: consider LLMs.txt informational, not an enforcement or ranking input today.
Is LLMs.txt like robots.txt? Can it control or block AI training and crawling?
No. This is one of the most common misconceptions. LLMs.txt is positioned as a “guide” or “map” to your important content, not an access-control mechanism. It does not block or enforce bot behavior and cannot stop training or scraping; access control still relies on robots.txt directives, HTTP headers, and legal policies, which are themselves unevenly honored by some AI crawlers. Think of LLMs.txt as a curated index or synopsis of key resources (often in markdown) intended to help models understand what matters — but only if they choose to look, which most don’t right now.
If it’s easy to add, should I add LLMs.txt anyway?
It’s optional. Many SEOs describe it as “low effort, low impact,” so if there’s bandwidth, adding a clean llms.txt won’t hurt — but it shouldn’t distract from proven AEO/GEO optimizations that actually influence AI answer visibility. Tools and workflows exist to generate LLM-ready summaries from crawls (e.g., Screaming Frog+automation), which can streamline maintenance if you choose to experiment; just don’t expect rankings to change because of the file alone. If you do add it, keep it accurate, concise, and regularly updated — and monitor server logs to see if any AI bots request it.
What should I do instead to rank in AI answer engines like ChatGPT and Perplexity?
Prioritize Answer Engine Optimization (AEO) and Generative Engine Optimization (GEO) fundamentals that practitioners, agencies, and search pros consistently recommend:
1. Provide direct, succinct answers near the top of pages, with question-based headings and scannable structure to aid AI extraction and summarization.
2. Strengthen E-E-A-T signals: showcase expertise, cite high-quality sources, keep content updated, and build topical authority across clusters of related pages.
3. Implement structured data (FAQPage, HowTo, Article) so answer engines can parse and contextualize content reliably.
4. Improve internal linking to surface definitive resources and reduce ambiguity about the best canonical answer on the site.
5. Track AI visibility: manually check and use tools to monitor mentions/citations in Perplexity, ChatGPT, Gemini, and AI Overviews; iterate content where it’s missing or misrepresented.
These practices consistently outperform speculative tactics in community reports and align with platform guidance that “normal SEO” and answer-ready content drive inclusion in AI experiences.







