
Even the most advanced large language model can fumble if it lacks the right information. Modern LLM applications have evolved beyond simple text generation – they now drive actions, use tools, and carry on long conversations. Developers are building agentic systems where an LLM might be asked not just to answer a question, but to execute tasks or reason over multiple steps. This evolution brings a new challenge: how do we feed the model all the information it needs to perform accurately, without confusing it or exceeding its limits? The answer is emerging in a practice called context engineering.
Context engineering is the art and science of assembling all the pieces of information an LLM needs at runtime to do its job well. That includes the user’s instructions, relevant data or knowledge, and any persistent memory from prior interactions. All these pieces are like puzzle fragments that must be combined into a prompt so the model can focus on the task at hand. In essence, context engineering is about giving an LLM “just the right information, at the right time” within its input. It’s a direct response to the fact that an LLM’s world knowledge alone often isn’t enough – we need to continuously provide context to ground its responses.
Hallucinations and the Need for Relevant Context
One of the biggest reasons context engineering matters is to prevent hallucinations. Hallucinations occur when an LLM produces outputs that sound confident but include incorrect or fabricated information. This often happens when the model hasn’t been given the facts it needs – it falls back on its training data or makes something up. If you’ve ever seen an AI assistant give a very wrong answer with a straight face, you’ve witnessed a hallucination. By ensuring the model’s input includes the relevant context (such as up-to-date facts from a knowledge base or the specifics of the user’s request), we can dramatically reduce these failures.
In complex “agent” applications, the risk of hallucination and confusion grows. An agentic LLM might be juggling multiple tool outputs, system directives, and user messages all at once. Without careful management, these competing pieces of information can blur together and overwhelm the model’s focus. The model has a fixed attention span defined by its context window, which is the maximum input size (in tokens) it can handle. Everything we provide – instructions, user query, retrieved data, etc. – has to fit into this finite window. For example, OpenAI’s GPT-4 model typically supports a context window of around 8,192 tokens (with an extended version up to 32,768 tokens), and other models have their own limits. A token is roughly 3-4 characters of text; it’s the unit of text the model counts and attends to. If we try to stuff more tokens than the limit, the model will simply truncate or ignore the extra content. This makes it crucial to prioritize and filter what goes into context.
Context engineering gives us a framework of techniques to manage all the information an LLM needs within those limits. It encompasses strategies for choosing, compressing, and formatting context. To paint a clearer picture, here are the typical components of context that an LLM-driven application may need to handle:
- User Instructions and Prompts: This includes the user’s query or command, as well as any system or developer-provided instructions that guide the LLM’s behavior (often called prompt engineering). For instance, a system message might set the role (“You are a helpful customer support agent”) and rules.
- Retrieved Knowledge: External data relevant to the task, such as documents, knowledge base articles, code snippets, or database records. This is usually fetched via a retrieval step from a vector database or search index when the user’s query needs outside information.
- Tool Outputs and Actions: Results from tools the LLM can use. In an agent scenario, the LLM might query an API, do a calculation, or call another service. The outcome of those actions is additional context the model must remember and integrate in subsequent steps.
- Conversation and Memory: Any historical context from the ongoing conversation or previous interactions. This could be the chat history with the user or long-term facts the user provided earlier (like their name or preferences). Managing this short-term and long-term memory is critical so the model doesn’t repeat questions or forget key details over multiple turns.
- Intermediate Reasoning or Scratchpads: Sometimes the LLM generates intermediate notes, plans, or reasoning steps (a scratchpad) that shouldn’t be shown to the user but help it work through a complex problem. These too form part of context, especially in chain-of-thought prompting or multi-step workflows. They may be stored outside the immediate prompt and pulled in as needed.
All of these elements must be selected, organized, and fit into the model’s input context window for the application to succeed. If we naively throw everything at the model, we’ll overflow its capacity or drown the important facts in noise. Context engineering is about being intentional with these pieces: retrieving the right data at the right time, filtering out irrelevant or low-value information, and compressing longer context into more succinct forms when necessary. In other words, having a lot of context available isn’t enough – we have to engineer that context into a usable form for the model.
Core Techniques in Context Engineering (Lessons from RAG)
The good news is that many developers have already been practicing aspects of context engineering, especially if you’ve built Retrieval-Augmented Generation (RAG) systems. RAG is a design pattern where an LLM is augmented with an external knowledge source: you retrieve relevant information for each query and feed it into the prompt. If you’ve implemented a semantic search or Q&A chatbot that looks up documents to answer user questions, you’re familiar with the basics: chunking data, embedding it, searching, and injecting results into a prompt. Context engineering builds on these fundamentals and generalizes them to more complex applications.
Let’s start with a simple example. Imagine you’re building a customer support assistant that answers user questions using your company’s documentation. The high-level flow might look like this:
- Question Ingestion: Accept the user’s question or issue (e.g. “How do I reset my account password?”).
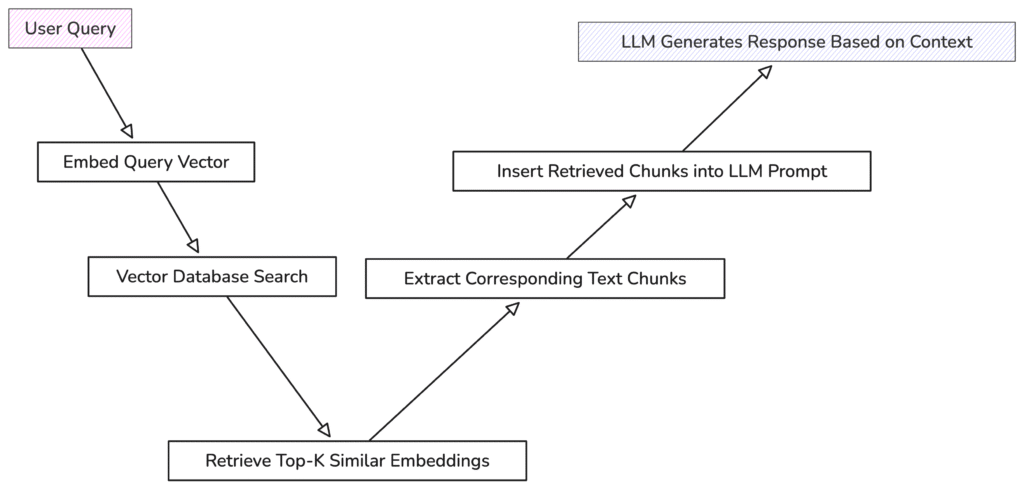
- Retrieval: Convert that query into a vector embedding using an encoder model (for instance, OpenAI’s text-embedding-ada-002 or another embedding model). Use this embedding to query a vector database (like Pinecone or an open-source alternative) that holds embeddings of your knowledge base documents. Retrieve the top relevant documents or snippets that might contain the answer.
- Compose Prompt with Context: Take the retrieved snippets and assemble them into the prompt alongside an instruction. For example, you might prepare a prompt that says: “You are a support agent. Use the following documentation snippets to answer the question. \n\n \n\n Question: ”. This prompt explicitly provides the context and asks the LLM to base its answer on it.
- LLM Response: Send this prompt to the LLM (say via the OpenAI GPT-4 API) and get the answer. The model will read the provided context and hopefully respond with an accurate solution (e.g. “To reset your password, go to the settings page, click ‘Forgot Password’, then follow the emailed link…”).
This basic pipeline already demonstrates context engineering in action. We augment the LLM’s context with relevant data fetched just-in-time. Several key techniques are involved here:
- Chunking and Tokenization: Large documents are split into chunks that fit within the model’s token limit (for example, breaking a long FAQ article into sections of a few hundred tokens). Each chunk is encoded into an embedding vector. Chunking ensures we can retrieve and send only the portion of a document that relates to the query, rather than the whole text, thus budgeting our context window wisely.
- Vector Embeddings & Similarity Search: By embedding both queries and documents into the same vector space, we can use cosine similarity or dot products to find which pieces of knowledge are semantically related to the user’s question. This semantic search is robust to keyword mismatches – for instance, a query about “resetting password” might retrieve a snippet about “credential recovery” even if it uses different wording, thanks to the embedding’s understanding.
- Relevance Ranking and Filtering: It’s common to retrieve the top K results (say 5 snippets), but not all of them will always be useful. Context engineering often employs a re-ranking step or heuristic filters to order the snippets by actual relevance. For example, you might use a secondary model (like a smaller language model or a cross-encoder) to score which snippet actually answers the question best, or remove any snippet that has very low similarity. This prevents “noisy” context from sneaking into the prompt. Including only the top 2-3 most relevant pieces can reduce confusion and cut token usage, which in turn lowers latency and cost.
- Prompt Design for Context Injection: How we insert retrieved context into the prompt matters. A clear separation (like a CONTEXT: section followed by the USER QUESTION:) helps the model understand what we’re giving it. Good prompt design might also involve instructions to use the provided context and not stray from it. In our support bot example, we explicitly told the model to use the documentation snippets and to say “I don’t know” if the answer isn’t in those snippets. These instructions guard against hallucination by telling the model what to do when context is insufficient.
Below is a simplified code example of what this retrieval-and-answer process could look like using Python. It assumes you have a vector database client (Pinecone in this case) and OpenAI’s API available. This snippet shows the core logic of embedding a query, searching for context, and constructing a prompt for GPT-4:
import openai
import pinecone
# Initialize Pinecone (assuming API key and environment are set)
pinecone.init(api_key="YOUR_API_KEY", environment="us-west1-gcp")
index = pinecone.Index("knowledge-base-index")
user_query = "How do I reset my account password?"
# Step 1: Embed the user query into a vector
embedding_model = openai.Embedding.create(model="text-embedding-ada-002", input=user_query)
query_vector = embedding_model['data'][0]['embedding']
# Step 2: Retrieve relevant context from Pinecone vector DB
results = index.query(vector=query_vector, top_k=3, include_metadata=True)
if not results.matches:
print("No relevant context found, proceeding without external info.")
context_snippets = [match.metadata["text"] for match in results.matches]
# Step 3: Construct the prompt with retrieved context
system_instructions = "You are a customer support AI that answers queries using the provided knowledge base context."
context_text = "\n\n".join(context_snippets) # join snippets with spacing
user_prompt = f"Context:\n{context_text}\n\nQuestion: {user_query}\nAnswer:"
messages = [
{"role": "system", "content": system_instructions},
{"role": "user", "content": user_prompt}
]
# Step 4: Query GPT-4 with the composed messages
response = openai.ChatCompletion.create(model="gpt-4", messages=messages)
answer = response["choices"][0]["message"]["content"]
print(answer)
In this code, we embedded the query, searched Pinecone for relevant text (assuming each result’s metadata has a "text" field containing the snippet), and then built a chat prompt for GPT-4. We also included a simple check: if no results are found, we note that no external context is available. In a real system, you might handle that case by either informing the user or letting the LLM answer from its training knowledge with a disclaimer.
This example covers the fundamental retrieval-augmented prompt approach. If your LLM application is a straightforward question-answering system, these steps might be sufficient. However, many real-world applications need to go further. What if the user asks a follow-up question? What if the task requires the AI to perform actions like creating a ticket or pulling data from another API? This is where context engineering truly shines – helping maintain effectiveness across multi-turn interactions and more complex task sequences.
Beyond Q&A: Memory and Context Over Time
Consider that our support bot example now needs to handle an entire conversation and perform actions, not just answer one question. Suppose we want the bot to manage support tickets end-to-end. The requirements might include: keeping a conversation with the user to gather all necessary info, creating or updating a ticket in an external system via an API call, referencing prior tickets if the user has an ongoing issue, and so on. In other words, the LLM is becoming an agent that must reason and act, maintaining state over multiple turns. How do we keep it grounded and focused as the conversation evolves?
We’ll need to introduce additional context-handling techniques and components:
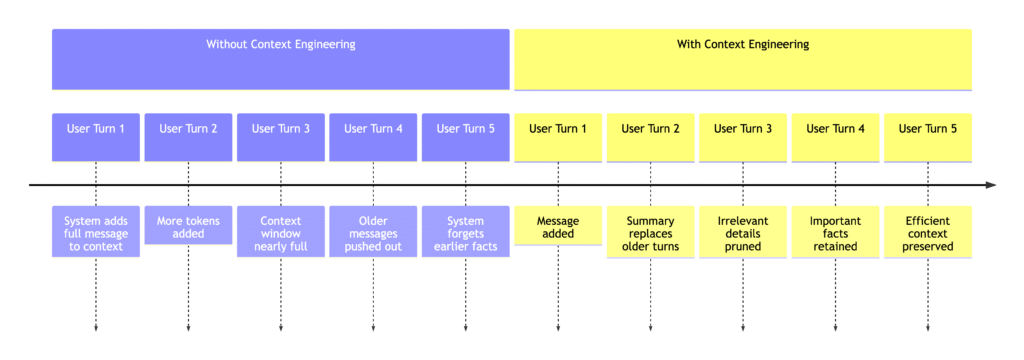
- Long-Term Memory and Summarization: As the dialogue progresses, the history grows. The bot might have exchanged dozens of messages. Simply resending the entire conversation as context will eventually exceed the token limit (and get slower and costlier). A common approach is to summarize older parts of the conversation. For example, after a long back-and-forth, the system can generate a concise summary of the important points and use that in place of the verbatim transcript. This context compression frees up space while preserving relevant information. The summary itself could be created by an LLM or some heuristic, and it can be stored externally (like in a database or memory module) for later retrieval. Think of it as the bot taking notes.
- Tool Integration (Action Results): If the bot uses tools – say it calls an API to create a support ticket or checks a status in a database – the results of those calls need to be fed back into the context. For instance, after creating a ticket, the API might return a ticket ID. The assistant should remember that ID and perhaps communicate it to the user. Context engineering involves deciding how to incorporate such tool outputs. Some frameworks allow the LLM to call a tool and automatically insert the result into the next prompt. If not, you may capture the result and explicitly add a line to the context like, “(System: Ticket #12345 has been created.)”. This way, the model’s subsequent responses can refer to it.
- Structured Outputs and Scratchpads: When tasks require structured information (like filling out a form or extracting specific fields), it’s useful to guide the LLM’s output format and possibly use intermediate scratchpads. For example, the support agent might internally keep a scratchpad listing “User name: ___, Email: ___, Issue: ___” as it gathers info. This scratchpad can be maintained outside the main conversation prompt (to avoid cluttering the user-visible context) and only the relevant parts injected when needed (e.g., once filled, it can be summarized back to the user or used in an API call). Managing these scratchpads is part of context engineering – deciding what intermediate data to remember and when to clear or update it.
- Context Deletion (Pruning): Not everything said or retrieved earlier remains relevant. Good context management means pruning out or forgetting pieces that are no longer needed. For instance, if the conversation branched and one line of inquiry is resolved, those details might be dropped from further prompts to make room for new information. Developers sometimes maintain a state object for the agent that explicitly drops confirmed or irrelevant facts. Another example: if the user has changed the topic or corrected themselves, retaining the outdated context could harm the answer quality, so it should be removed or marked as superseded.
- Agent-Initiated Retrieval: In a complex task, the agent (LLM) might need to retrieve new information in the middle of its reasoning process. We often design agents that can decide when to perform a search. For example, if part of the task requires data the agent doesn’t have yet, it could issue a command like “Search the knowledge base for X” which your system interprets and executes, then return the results into the context. Frameworks like LangChain facilitate this by letting you register a vector database as a tool the LLM can call. This adds dynamism: instead of retrieving only once per user query, the agent can retrieve whenever it realizes more info is needed. However, it also requires the agent to have some understanding of when to search and what to search for – which comes from careful prompt engineering and possibly some trial-and-error in design.
All these capabilities – memory, tool use, iterative retrieval, structured reasoning – consume space in the context window. Without planning, an agent will quickly overflow the model’s input limit or get bogged down by irrelevant details. This is why context engineering becomes critical. We must continuously budget the context window as the interaction progresses. That can mean summarizing earlier content, trimming the conversation, or even offloading some knowledge to long-term storage that the agent can query when needed instead of holding it all in the prompt. It’s a balancing act between giving the model enough information to be smart and not so much that it becomes slow, expensive, or confused.
It’s worth noting that these principles are already reflected in advanced RAG implementations. For example, when dealing with multi-turn conversations, some systems maintain a rolling summary of past dialogue (to preserve important context in a condensed form). When retrieving documents for a new user query, they might expand the query with recent conversation context so the search is more targeted. They might also use re-ranking at each turn to ensure only the most relevant chunks (possibly new ones discovered based on the refined query) are included going forward. Essentially, context engineering for long-running dialogues means treating context as a constantly evolving state, rather than something you fetch once and fix in place.
Context Engineering in Agentic Architectures
As you design more complex LLM systems, you’ll face architectural choices that impact context management. One big question is whether to use a single monolithic agent (one LLM handling everything sequentially) or to break the problem into multiple specialized agents (or sub-agents) that work in parallel or sequence. Context engineering provides a lens to evaluate these options.
For example, imagine our support bot could be split into two agents: one handles the user conversation, and another (a background agent) handles creating and updating tickets behind the scenes. The conversation agent could offload the ticket creation to the background agent, allowing it to keep talking to the user without waiting. This sounds efficient – the user isn’t kept idle while the ticket gets created. However, consider the context implications: now we have two LLMs with separate contexts. The conversation agent needs to eventually know the result of the ticket creation (ticket number, status, etc.), which means the background agent must communicate that back, and the conversation agent must integrate it into its context. We’ve basically introduced a new challenge of maintaining shared context between agents.
In contrast, if one agent handles both conversation and ticket creation step by step, everything stays in one context thread. It might be slower (because it does things one at a time), but it’s easier to keep track of information – the ticket details remain in the single agent’s memory as it proceeds. There’s no risk of one agent not knowing what the other did, because there is no “other” in that scenario.
Researchers and practitioners have noted that multi-agent or parallel-agent setups can lead to context fragmentation. In some cases, simpler sequential architectures (one agent that does all steps in order) are actually easier to manage context with, especially for tasks that are knowledge-heavy or require consistent reasoning. On the flip side, multi-agent architectures might excel in speed or modularity for certain problems, but they demand careful context engineering to synchronize knowledge between agents. You might need a shared memory or a coordination mechanism where agents write important facts to a common store (like a shared database or scratchpad) that all agents read from. This adds complexity.
When deciding on your architecture, it’s valuable to think in terms of context engineering: How will each agent get the information it needs? How will you prevent context from getting lost or out-of-date across agents? If an agent is working in isolation, could it hallucinate something another agent actually knows, simply because that fact wasn’t shared? These questions highlight why context engineering is often said to be the “#1 job” of engineers building AI agents. In practice, many teams start with a single-agent approach and only add additional LLM agents when absolutely necessary, precisely because of these context challenges.
To be clear, using multiple agents can be made to work – it may just require additional design, such as periodic synchronization points or assigning each agent a well-scoped responsibility so their contexts overlap minimally. For instance, one agent could handle only database searches (and returns found facts), while another handles the conversation logic. In that case the search agent’s output is just treated as another form of retrieved context for the main agent. This is very similar to the tool-calling paradigm, where the “search agent” is essentially a tool. Many agent frameworks (like those built with LangChain or custom implementations) follow this pattern: the primary agent invokes tools or sub-agents and gets results that it then incorporates into its own context.
The key takeaway is that context engineering isn’t just about fiddling with prompts – it influences high-level system design. Decisions about how to structure your LLM application should be driven by how you will manage and preserve context throughout the system.
Tools and Frameworks for Context Engineering
Building a production-ready context-engineered system is much easier with the right tools. A number of libraries and services have emerged to support these patterns:
- Vector Databases (for Retrieval): Tools like Pinecone, Weaviate, Milvus, or Vespa are purpose-built to store embedding vectors and perform similarity search quickly. They handle the scaling challenges of storing millions of vectors and provide filtering, indexing, and horizontal scaling. Using a managed vector DB (like Pinecone) means you can focus on your application logic while the database efficiently finds relevant context for you. If you prefer to keep things in-house or have lighter needs, libraries like FAISS or Annoy can be used to build a local vector index. The role of the vector DB is essentially to serve as the “external memory” of your LLM – it’s where you offload knowledge so that you can retrieve it on demand rather than fitting it all into the model’s finite context at once.
- LLM APIs and Models: At the core, you have the LLM itself (e.g. OpenAI’s GPT-4, Anthropic’s Claude, Cohere, or open-source models like LLaMA). Choosing a model with an adequate context window is important for your use case. If you know your application may need to handle long documents or lengthy conversations, you might opt for GPT-4 32k context version or Claude which historically supports up to 100k tokens in some versions. Keep in mind larger windows often mean higher costs and slower responses, so there’s still incentive to be efficient with context. OpenAI’s API (and others) allow passing system, user, and assistant messages which you can use to structure context (e.g., put instructions in system, user query and retrieved info in user message, etc.). The API doesn’t do context engineering for you – it just executes whatever prompt you send – so it’s up to your application to manage that prompt content.
- Orchestration Frameworks (LangChain, etc.): LangChain (for Python/TypeScript) and similar frameworks provide abstractions to simplify context management. For example, LangChain has concepts of Chains and Agents that can automatically handle retrieving from a vector store and formatting the prompt for you. It has a Memory component that can summarize or window the conversation history. It also provides a standard interface for tools, so you can easily add a Google search tool, a calculator, or a vector DB lookup as an action the LLM can use. Essentially, frameworks like LangChain package many context engineering best practices into ready-made components – you still need to configure them correctly, but you don’t always have to write them from scratch. That said, LangChain is not magic; it operates on top of the same principles we’ve discussed. Some developers prefer to implement lightweight, custom orchestration logic tailored to their needs once they understand the basics. For instance, you might not need the full generality of an agent framework for a focused use case – a few well-placed API calls as illustrated in the code snippet can do the job.
- Custom Embedding Pipelines: While you can use OpenAI’s embedding models to convert text to vectors, you might have cases where you need a custom solution. Perhaps your data is very domain-specific (legal, medical) and a domain-specific embedding model would retrieve better. Or you have privacy constraints that mean you need to run the embedding step on-prem or on a user’s device. Thankfully, there are many open-source models (SentenceTransformers, HuggingFace embeddings, etc.) that you can deploy to generate embeddings. You would then store those in your vector DB of choice. The rest of the pipeline stays the same. The key is that you have the flexibility to plug in different embedding generators depending on your requirements. Just ensure whatever you choose yields vector representations that work well for semantic search – some trial and evaluation might be needed here. Quality of embedding directly affects the quality of retrieval, and hence the quality of context your LLM gets.
In practice, building an LLM application with context engineering might involve all the above: using an LLM API to handle responses, a vector store to supply knowledge, and a framework like LangChain (or custom code) to orchestrate the retrieval, memory, and tool usage. For example, LangChain’s RetrievalQA chain can take a question and automatically do the embed-search-insert routine. Or its Agent classes can let an LLM decide to call the vector search as a tool on its own when needed. These tools handle a lot of boilerplate (like converting data formats, batching, etc.), but it’s still important to understand what’s happening under the hood – which is exactly what context engineering is about.
Challenges and Best Practices
While context engineering enables powerful LLM systems, it comes with its share of challenges and edge cases. Experienced developers pay special attention to the following issues when designing context:
- Noisy or Irrelevant Retrieval: Your system might fetch pieces of context that are only loosely related to the query or contain erroneous data. If this noise is inserted into the prompt, the model could get distracted or incorporate false info from it, leading to confusing answers. To combat this, always vet your retrieval process. Use similarity score thresholds (e.g., only include snippets with a cosine similarity above a certain cutoff). Consider manual curation or additional filters on the content (for example, remove snippets that don’t contain a keyword that appeared in the question, as a sanity check). Another strategy is “reader reranking”: have the LLM quickly read each candidate snippet and answer which ones seem most relevant before answering the user. This uses the LLM’s strength to filter context in a second pass.
- Overfitting or Rigid Prompts: It’s possible to craft a prompt that works brilliantly on your initial test queries but then fails unexpectedly on slightly different inputs. This can happen if the prompt or provided context is too tailored to a narrow scenario (an overfit prompt). For example, if all your test questions involved pricing and your prompt explicitly says “The user is asking about pricing,” it might misbehave if a question is about something else. Avoid hardcoding specifics in the prompt that aren’t generic. Instead, rely on dynamic context and instructions that adapt to the actual query. Testing your system on a wide range of queries (including out-of-scope or tricky ones) will reveal whether your context injection logic is robust. The goal is to have a prompt and context strategy that generalizes well, not just one that parrots back what you expect.
- Hallucinations from Irrelevant Context: A particularly sneaky problem is when the context provided is related but not actually correct for the query. The model might see those details and assume they are relevant, weaving them into its answer incorrectly. For instance, suppose the user asks about updating billing information, and one of the retrieved documents is about updating a mailing address – the model might mistakenly blend the two and give steps for the wrong thing. To reduce this risk, you can implement relevance feedback loops: after the model answers, you could have another check where the model or another process verifies if the answer truly addresses the question using the given context (and doesn’t cite things that weren’t in context). Some developers also format context with clear markers (like citing source numbers) to prompt the model to explicitly indicate which source supports each fact. If it can’t find a source in context for part of its answer, that might indicate a hallucination. This is more of an advanced technique and can complicate prompt design, but it’s worth considering for high-stakes applications.
- Cost and Latency Trade-offs: Context engineering often involves making multiple calls – embedding the query, searching the vector DB, maybe summarizing, then calling the big LLM. Each of those steps has a performance cost. If not optimized, the user might end up waiting unacceptably long for a response, or the API usage costs might stack up. Best practices here include caching results when possible (e.g., cache embeddings for frequent queries or cache document embeddings in memory to avoid recomputation), and tuning how much context you include. There’s a sweet spot: too little context and the model might be clueless; too much and you’re paying for tokens and time that don’t improve the answer. Continuous profiling and testing different configurations (like retrieving 3 vs 10 documents, or summarizing after 5 turns of dialogue vs 10) can help find a balance. Also, be mindful of context length limits – if you target a 8k-token model, design your system to comfortably stay under that in worst-case scenarios, perhaps by enforcing a hard limit on how many tokens of retrieved text are inserted.
- Evolving Knowledge and Freshness: The contents of your context sources (documents in the vector DB, etc.) can become outdated or might need frequent updates. Make sure your pipeline has a way to keep the knowledge base fresh – otherwise you risk feeding stale information as context, which can cause the LLM to give outdated answers (a subtle kind of hallucination). This isn’t directly a prompt engineering issue, but it’s a part of maintaining reliable context. Automate re-embedding and updating your vector index when content changes. Also, consider versioning: if your docs have timestamps or versions, you might embed that metadata and prefer newer ones at query time. Context engineering is not static – it involves maintaining the quality of context sources over time too.
Finally, always test the system holistically. A context-engineered LLM application has many moving parts (embedding model, vector search, LLM prompts, etc.). Problems can arise from any part: maybe the embedding model fails on some edge-case query phrasing, or the LLM prompt sometimes gets ignored because the user’s last message was too long and pushed part of the instructions out of the window. By simulating real usage scenarios and edge cases (long conversations, tricky queries, irrelevant user input, etc.), you can observe where the context strategy breaks down. Use those observations to iterate on your design – perhaps you’ll discover you need a more aggressive summarization policy, or an adjustment to your retrieval scoring.
Conclusion
Context engineering is rapidly becoming a foundational skill in building AI systems with large language models. It extends the ideas of prompt engineering by recognizing that in practical applications, we aren’t dealing with a single prompt and response – we’re managing a flow of information that the LLM consumes over time. By thoughtfully selecting what an LLM “sees” at each step, we enable these models to perform complex tasks reliably, whether it’s answering questions with up-to-date knowledge, carrying on a long conversation without forgetting earlier details, or orchestrating multi-step tool interactions.
For developers, the takeaway is that using an LLM in production is far more than just calling an API with a string. One must design how to feed the model context from various sources and when to refresh or discard that context. The tools and techniques discussed – from vector databases and embeddings to prompt templates, summarization, and memory buffers – are all practical instruments in this design. As you build your next LLM-powered system, think about the journey of the information: where it comes from (data sources, user input, tools), how it’s transformed or filtered (embeddings, search, rank, summarize), and how it’s presented to the model (prompt formatting, ordering of content). Each of those steps is a point where careful engineering can make the difference between an AI that feels grounded and one that goes off the rails.
By mastering context engineering, you empower your AI applications to be more accurate, efficient, and resilient. It’s an ongoing process of refinement – as new types of tasks and larger context windows arrive, the strategies will continue to evolve. But the core principle remains the same: provide the right information to the model, and it will give you the right answer. Achieving that consistently is what context engineering is all about, and it’s what turns a clever LLM demo into a reliable, production-grade system.








