
Retrieval-Augmented Generation (RAG) allows you to supercharge an AI model with your own data. Instead of a chatbot relying only on pre-trained knowledge, a RAG-based assistant can ingest custom documents, index them in a vector database, and answer user questions by retrieving relevant information from those documents. This yields far more accurate, up-to-date, and context-specific answers with minimal hallucinations.
In this implementation-focused guide, we’ll walk through the entire process from input to output: ingesting documents (input), transforming them into embeddings and building a vector index (transformation), and finally using that index to answer questions with an LLM (output). We’ll minimize theory and focus on actionable steps, complete with code snippets you can copy-paste. By the end, you will have a working AI agent that can answer questions from your documents using Python code.
Project Setup and Requirements
Before diving into code, let’s set up our environment.
1. Create a Python environment
Ensure you have Python 3.9+ installed. We recommend isolating the environment:
python -m venv venv
source venv/bin/activate # On Windows: venv\Scripts\activate2. Add the following files to your project directory
Create a new project folder and include the following files:
📄 requirements.txt
# Core LangChain packages (latest compatible versions)
langchain>=0.1.0
langchain-community>=0.0.20
langchain-openai>=0.0.8
langchain-text-splitters>=0.0.1
langchain-core>=0.1.0
# Vector store and embeddings
faiss-cpu>=1.7.4
# Alternative: Use faiss-gpu if you have CUDA support
# faiss-gpu>=1.7.4
# Document processing
PyPDF2>=3.0.1
pypdf>=4.0.0
# OpenAI API
openai>=1.0.0
# Text processing and tokenization
tiktoken>=0.5.0
# Utilities
python-dotenv>=1.0.0
typing-extensions>=4.5.0
# Optional: Enhanced PDF processing
# pymupdf>=1.23.0
# unstructured>=0.10.0
# Optional: Web scraping capabilities
# beautifulsoup4>=4.12.0
# requests>=2.31.0
# Optional: Development tools
# pytest>=7.0.0
# black>=23.0.0
# flake8>=6.0.0Install dependencies using:
pip install -r requirements.txtThis installs the exact versions used in this guide.
If you prefer installing manually:
pip install langchain langchain-community langchain-openai langchain-text-splitters faiss-cpu python-dotenv PyPDF2 openai tiktoken📄 rag_agent.py
This is your main script. It contains everything from document ingestion to query-answering. The full code is shared later in this blog — you can copy-paste it directly or split it into modules if needed.
📁 docs/
This folder should contain the documents you want the assistant to learn from. For testing, create a few .txt or .pdf files like:
docs/
├── example.pdf
├── example.txt
...You can also use the example files provided in this blog or bring your own.
(Optional) If you prefer step-by-step interaction, you can create a rag_agent.ipynb notebook and paste the code blocks into separate cells.
The file structure will look like this:
your_project/
├── rag_agent.py # Your updated RAG system code
├── requirements.txt # Dependencies
├── docs/ # Document folder
│ ├── artificial_intelligence.txt
│ ├── quantum_computing.txt
│ ├── climate_science.txt
│ ├── biotechnology.txt
│ ├── space_exploration.txt
│ └── renewable_energy.txt
└── vector_index/ # Will be created automatically3. Set up your OpenAI API key
This project uses OpenAI’s models for both embedding and response generation. Set your API key as an environment variable:
export OPENAI_API_KEY="sk-YourAPIKeyHere"On Windows (CMD):
set OPENAI_API_KEY=sk-YourAPIKeyHereTip: For local development, you can also create a
.envfile and usepython-dotenvto load it.
With these files and setup complete, you’re ready to begin implementing your RAG-based knowledge assistant. Let’s now move to document ingestion.
How the RAG Pipeline Works?
Before coding, let’s briefly outline the RAG pipeline we are implementing:
A high-level RAG workflow: documents are ingested and indexed (left, offline), and at query time (right, online) relevant context is retrieved from the vector index to augment the LLM’s answer.
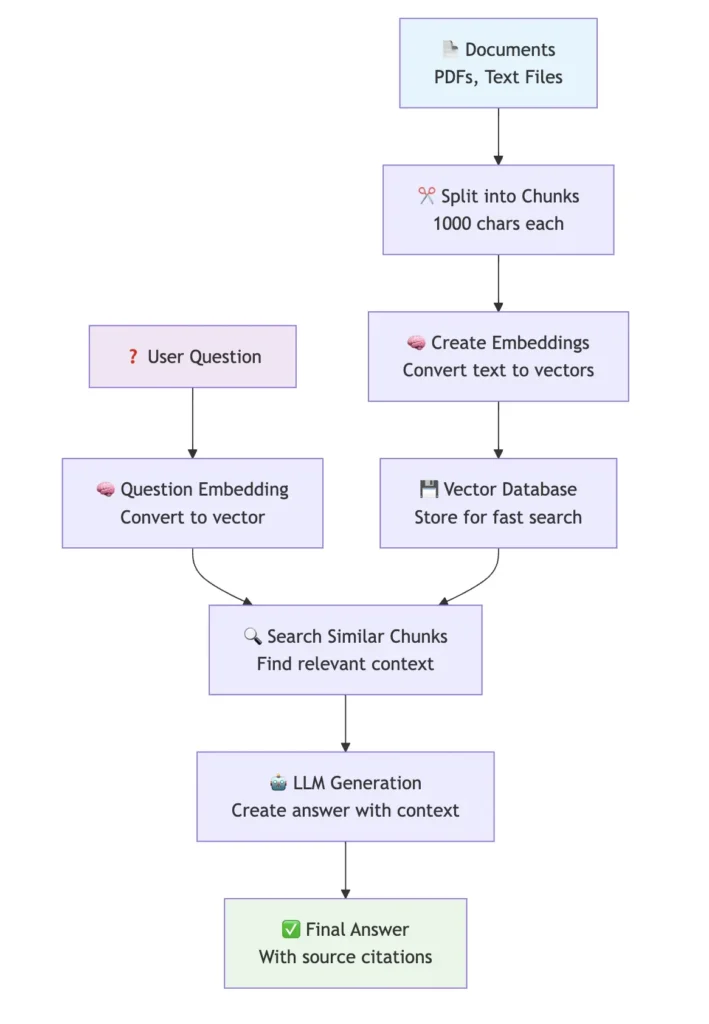
- Input (Document Ingestion): We take a collection of documents (PDFs, texts, etc.) as the knowledge source. These documents are loaded and pre-processed (e.g., split into smaller chunks).
- Transformation (Vectorization & Indexing): Each document chunk is passed through an embedding model to get a high-dimensional vector representation. We store these vectors in a vector index (FAISS, in our case). This index enables similarity search: given a query vector, we can quickly find the most relevant document chunks.
- Output (Query → Answer Generation): When a user question comes in, we embed the query with the same model and use the vector index to retrieve the top relevant chunks. These chunks (context) are then fed into a Large Language Model (LLM), such as GPT-3.5 or GPT-4, which generates a final answer grounded in the retrieved context.
In summary, the RAG agent will search your documents for relevant info and use an LLM to answer questions based on that info. Now, let’s implement this step by step.
Step 1: Ingesting Documents (Input)
The goal here is to load your source documents into the program and split them into manageable chunks for embedding.
First, organize your files. By default, our script expects a folder named docs/ in the working directory containing the documents (you can change this path in the code if needed). The starter kit’s docs/ folder has example files, but you can add your own TXT, PDF, etc.
1. Loading documents
LangChain provides convenient loaders for various formats. For text files, we can use TextLoader. For PDFs, we’ll use PyPDFLoader (which relies on the pypdf library). We can also use a DirectoryLoader to automatically load all files in the folder.
Below is a code snippet to load all documents from the docs directory:
from langchain_community.document_loaders import DirectoryLoader, TextLoader, PyPDFLoader
# Load all .txt files
text_loader = DirectoryLoader("./docs", glob="**/*.txt", loader_cls=TextLoader)
text_docs = text_loader.load()
# Load all .pdf files
pdf_loader = DirectoryLoader("./docs", glob="**/*.pdf", loader_cls=PyPDFLoader)
pdf_docs = pdf_loader.load()
# Combine loaded documents
documents = text_docs + pdf_docs
print(f"Loaded {len(documents)} documents from 'docs/'")
This code will recursively read all .txt and .pdf files in docs/ and return a list of Document objects. Each Document contains the file’s text content and metadata (like file path). If your data is in other formats (CSV, Notion, HTML, etc.), LangChain has loaders for those as well, but for simplicity we stick to text and PDF here.
2. Splitting into chunks
Large documents need to be split into smaller pieces to fit into the embedding model’s token limit and to improve search granularity. We’ll use LangChain’s text splitter to break documents into chunks of a few hundred words each. We also allow some overlap between chunks to avoid cutting important context. For example:
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Split documents into chunks of ~1000 characters, with 200 characters overlap
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
docs = text_splitter.split_documents(documents)
print(f"Split into {len(docs)} chunks")
Now docs is a list of chunks (each a Document with a subset of text). We chose a chunk size of 1000 characters (roughly 200-250 words) and 200 characters overlap. You can adjust these parameters based on your documents and the embedding model’s token limit (for instance, OpenAI’s text-embedding-3-small can handle ~8000 tokens, so 1000 characters is safe). The overlap helps preserve context between chunks.
Logging
It’s good practice to log progress. For example, we printed the number of documents loaded and chunks created. In a real application, you might use Python’s logging library for more control:
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
logger.info(f"Loaded {len(documents)} documents and split into {len(docs)} chunks.")
This ensures you know the ingestion step succeeded and how many chunks will be indexed next.
Step 2: Embedding and Indexing (Transformation)
The main goal is to convert each document chunk into a vector embedding and store all embeddings in a vector index for fast similarity search.
We’ll use OpenAI’s embedding model to vectorize our text. By default, LangChain’s OpenAIEmbeddings uses the text-embedding-3-small model, which is suitable for semantic search and cost-effective.
1. Initialize the embedding model
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings() # uses text-embedding-3-small by defaultMake sure your OpenAI API key is set (via env var as above). If needed, you can specify the model or pass the API key like OpenAIEmbeddings(model="text-embedding-3-small", openai_api_key="..."), but defaults are fine here.
2. Build the vector store
We’ll use FAISS (Facebook AI Similarity Search) as our in-memory vector store. FAISS is a lightweight library to index and query vectors efficiently on CPU. LangChain provides a FAISS wrapper for convenience.
We can create the FAISS index directly from our documents and embeddings:
from langchain_community.vectorstores import FAISS
# Create vector index from chunks
vector_store = FAISS.from_documents(docs, embeddings)
print("Vector store built with {} vectors".format(len(docs)))
Under the hood, this will embed each chunk’s text using the OpenAI model and store the resulting vectors in a FAISS index structure. This step may take some time if you have many chunks, as it’s calling the embedding API for each (LangChain may batch requests to speed it up, but you might still process dozens of chunks per second). For example, embedding 1000 chunks could take around a minute, depending on API speed and rate limits.
3. Persist the index (important!)
By default, FAISS lives in memory – if you restart the script, you’d have to re-embed everything. To avoid rebuilding the index each time, we can save it to disk. For instance:
# Save the FAISS index to disk for future use
vector_store.save_local("vector_index")
This will create files (e.g., vector_index.index and vector_index.pkl) in the working directory. Later, if you want to load the saved index without re-processing documents, you can do:
from langchain_community.vectorstores import FAISS
# Reload vector store from disk (use the same embeddings instance)
vector_store = FAISS.load_local(
"vector_index",
embeddings,
allow_dangerous_deserialization=True
)Now we have a persistent vector database of our knowledge. Keep in mind that FAISS indices are not automatically updated if you add new documents – you would need to load, then add vectors for new data or rebuild and save again. Also, FAISS is in-memory; if your data is very large (millions of vectors), you might need an external database or a solution like Pinecone or Chroma. But for moderate sizes, FAISS is fast and convenient.
Step 3: Querying and Generating Answers
Goal: Accept a user’s question, retrieve relevant document chunks from the vector store, and generate an answer using an LLM.
Now comes the interactive part – turning the indexed knowledge into an actual Q&A agent.
1. Set up the LLM and create the QA chain
We’ll use OpenAI’s GPT model via LangChain’s interface. Since we want a conversational answer, we’ll use the chat model (e.g., GPT-4o-mini) with a deterministic tone (low temperature for factual answers).
from langchain_openai import ChatOpenAI
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
# Initialize the ChatGPT model
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.1)
# Create the prompt template
system_prompt = (
"You are a helpful assistant for question-answering tasks. "
"Use the following pieces of retrieved context to answer the question. "
"If you don't know the answer based on the context, just say that you don't know. "
"Use three sentences maximum and keep the answer concise.\n\n"
"Context: {context}"
)
prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
("human", "{input}"),
])
# Create the document processing chain
question_answer_chain = create_stuff_documents_chain(llm, prompt)
# Create the retrieval chain
retriever = vector_store.as_retriever(search_kwargs={"k": 4})
rag_chain = create_retrieval_chain(retriever, question_answer_chain)
A few notes on this setup:
ChatOpenAIwill use the environment’sOPENAI_API_KEY. We settemperature=0.1to minimize randomness for factual answers.create_retrieval_chainconstructs a question-answering chain that retrieves documents and passes them to the LLM. We passretriever=vector_store.as_retriever()– this exposes our FAISS index as a retriever. We setsearch_kwargs={"k": 4}to retrieve the top 4 most similar chunks for each query (you can adjust k as needed; a higher k gives the LLM more context at the cost of possibly including irrelevant data if too high).- LangChain will handle composing the prompt for the LLM that includes the question and the retrieved context. Essentially, it might look like: “Given the following context from documents, answer the question: [insert 4 chunks] Question: [user query]”. This helps ground the LLM’s answer in our data.
2. Ask questions
Now we can query our assistant. For example:
# Example query
question = "What does our company policy say about remote work?"
response = rag_chain.invoke({"input": question})
print("Q:", question)
print("A:", response['answer'])
The invoke method will: embed the question, perform similarity search in the vector store, feed the results into the LLM, and return a response dictionary. You should see an answer printed out, for example:
Q: What does our company policy say about remote work?
A: According to the company policy (Employee Handbook, p. 12), employees are allowed to work remotely up to 3 days per week with manager approval. Full-time remote arrangements require a written agreement.
(The actual answer will depend on the content of your documents.)
You can now ask any question about the content in your docs/. The assistant will retrieve the relevant info and use it to answer. If the answer seems incomplete or the agent says it doesn’t know, you might try increasing k (number of chunks) or ensure your query is specific enough.
3. Source citations (built-in)
The modern retrieval chain automatically returns the source documents that were used for the answer. You can access them from the response:
response = rag_chain.invoke({"input": question})
answer_text = response["answer"]
sources = response["context"]
print("Answer:", answer_text)
print(f"Based on {len(sources)} source documents:")
for i, doc in enumerate(sources, 1):
source_file = doc.metadata.get("source", "Unknown")
preview = doc.page_content[:100] + "..." if len(doc.page_content) > 100 else doc.page_content
print(f" {i}. {source_file}: {preview}")
The context key contains a list of Document chunks that were retrieved. You can extract doc.metadata["source"] (if the loader stored file names there) to identify which files the info came from. This is useful for building a more trustworthy assistant that cites evidence and allows users to verify the information.
Complete Example
Here’s a full working script that puts it all together:
import os
import logging
from getpass import getpass
from langchain_community.document_loaders import DirectoryLoader, TextLoader, PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_community.vectorstores import FAISS
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
# Setup logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def setup_openai_key():
"""Setup OpenAI API key from environment or user input"""
if "OPENAI_API_KEY" not in os.environ:
api_key = getpass("Enter your OpenAI API key: ")
os.environ["OPENAI_API_KEY"] = api_key
return os.environ["OPENAI_API_KEY"]
def load_documents(folder_path="docs"):
"""Load and preprocess documents from folder"""
try:
# Load text files
text_loader = DirectoryLoader(
folder_path,
glob="**/*.txt",
loader_cls=TextLoader,
loader_kwargs={'encoding': 'utf-8'}
)
# Load PDF files
pdf_loader = DirectoryLoader(
folder_path,
glob="**/*.pdf",
loader_cls=PyPDFLoader
)
text_documents = text_loader.load()
pdf_documents = pdf_loader.load()
documents = text_documents + pdf_documents
logger.info(f"Loaded {len(documents)} documents from '{folder_path}'")
logger.info(f"Text files: {len(text_documents)}, PDF files: {len(pdf_documents)}")
return documents
except Exception as e:
logger.error(f"Error loading documents: {e}")
return []
def split_documents(documents):
"""Split documents into chunks"""
if not documents:
logger.warning("No documents to split")
return []
splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
separators=["\n\n", "\n", " ", ""]
)
chunks = splitter.split_documents(documents)
logger.info(f"Split into {len(chunks)} chunks")
return chunks
def build_vector_store(chunks, persist_dir="vector_index"):
"""Embed and create FAISS vector store"""
if not chunks:
logger.error("No chunks to process")
return None
try:
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
if os.path.exists(persist_dir):
# Load existing index
store = FAISS.load_local(
persist_dir,
embeddings,
allow_dangerous_deserialization=True
)
logger.info(f"Loaded existing FAISS index from '{persist_dir}'")
else:
# Create new index
store = FAISS.from_documents(chunks, embeddings)
store.save_local(persist_dir)
logger.info(f"Created and saved new FAISS index to '{persist_dir}'")
return store
except Exception as e:
logger.error(f"Error building vector store: {e}")
return None
def create_qa_chain(vector_store):
"""Create modern retrieval chain using new LangChain approach"""
if not vector_store:
logger.error("Vector store is required")
return None
try:
# Initialize the language model
llm = ChatOpenAI(
model="gpt-4o-mini",
temperature=0.1,
max_tokens=500
)
# Create the prompt template
system_prompt = (
"You are a helpful assistant for question-answering tasks related to scientificworld.org. "
"Use the following pieces of retrieved context to answer the question. "
"If you don't know the answer based on the context, just say that you don't know. "
"Use three sentences maximum and keep the answer concise.\n\n"
"Context: {context}"
)
prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
("human", "{input}"),
])
# Create the document processing chain
question_answer_chain = create_stuff_documents_chain(llm, prompt)
# Create the retrieval chain
retriever = vector_store.as_retriever(
search_type="similarity",
search_kwargs={"k": 4}
)
rag_chain = create_retrieval_chain(retriever, question_answer_chain)
logger.info("Successfully created RAG chain")
return rag_chain
except Exception as e:
logger.error(f"Error creating QA chain: {e}")
return None
def main():
"""Main execution function"""
print("🔬 Scientific World RAG System")
print("=" * 50)
# Setup OpenAI API key
try:
setup_openai_key()
print("✅ OpenAI API key configured")
except Exception as e:
print(f"❌ Error setting up OpenAI key: {e}")
return
# Load documents
print("\n📄 Loading documents...")
docs = load_documents("docs")
if not docs:
print("❌ No documents found. Please add documents to the 'docs' folder.")
return
# Split documents
print("✂️ Splitting documents into chunks...")
chunks = split_documents(docs)
if not chunks:
print("❌ No chunks created from documents.")
return
# Build vector store
print("🧮 Building vector store...")
vector_store = build_vector_store(chunks)
if not vector_store:
print("❌ Failed to build vector store.")
return
# Create QA chain
print("🔗 Creating QA chain...")
qa_chain = create_qa_chain(vector_store)
if not qa_chain:
print("❌ Failed to create QA chain.")
return
print("✅ System ready!")
print("\n" + "=" * 50)
print("Ask questions about your documents. Type 'exit' to quit.")
print("=" * 50)
# Interactive Q&A loop
while True:
try:
question = input("\n🤔 Your question: ").strip()
if question.lower() in {"exit", "quit", "q"}:
print("👋 Goodbye!")
break
if not question:
print("Please enter a question.")
continue
print("🔍 Searching for answer...")
# Get response from the chain
response = qa_chain.invoke({"input": question})
print(f"\n💡 Answer: {response['answer']}")
# Optionally show sources
if "context" in response and response["context"]:
print(f"\n📚 Sources found: {len(response['context'])} documents")
except KeyboardInterrupt:
print("\n👋 Goodbye!")
break
except Exception as e:
logger.error(f"Error during QA: {e}")
print(f"❌ Error: {e}")
if __name__ == "__main__":
main()This complete example demonstrates how to build a modern RAG system using the latest LangChain patterns, providing both answers and source attribution for maximum transparency and trustworthiness.
Testing the System
After setting everything up, it’s important to test your RAG assistant to verify it works as expected:
- Basic functionality test: Run the script and ask a straightforward question that you know is answered in your documents. For example, if one of the example docs is an Employee Handbook, try: “How many vacation days do employees get per year?” The assistant should return the policy from the handbook.
- Edge cases: Ask something unrelated to the documents to see how it responds. Ideally, the assistant should admit it doesn’t know or return a fallback response, since no relevant info will be found. If it instead tries to hallucinate an answer, you might want to adjust the prompt or chain settings to enforce a refusal when no documents are relevant. (LangChain’s default prompt for RetrievalQA usually instructs the LLM to say “I don’t know” if it’s not in the context.)
- Multiple queries: Try a series of questions to ensure the system can handle consecutive queries. Our simple implementation does not maintain conversational memory between questions – each query is independent. You can add memory or a chat history if needed, but that’s beyond our current scope (the focus here is on retrieval from static knowledge).
- Performance check: Measure how long a query takes. Typically:
- Vector search in FAISS is very fast (milliseconds).
- The OpenAI API call for answering is the slowest step (GPT-3.5 might take ~1-2 seconds for a short answer; GPT-4 could take 5-10 seconds or more, depending on complexity).
If responses are too slow for your use case, you might use a smaller LLM or optimize by reducing the number of retrieved chunks (trading off some answer completeness).
Monitor your console logs for any errors or warnings during tests. If you encounter issues, use the troubleshooting tips below.
Performance and Cost Considerations
Speed: For a few documents or queries, this Python RAG pipeline will feel instantaneous. Document ingestion and embedding happens once up front. Each question then incurs one vector search (nearly instant) and one LLM call. If using GPT-3.5, expect answers in a couple of seconds. With GPT-4, responses are slower (and more expensive), so use GPT-4 only if you need its higher accuracy or larger context window.
If you need to scale to many concurrent queries or very large document sets, consider:
- Running the embedding and vector search on a server with more memory or using a hosted vector DB service.
- Using asynchronous calls or batching if integrating into a web app.
- Caching frequent queries (if certain questions repeat).
Cost: The main costs in this RAG system are OpenAI API calls:
- Embeddings: The initial embedding of your documents. For OpenAI’s ada-002 embedding model, the cost is around $0.0001 per 1K tokens (as of this writing, prices may change). That’s $0.10 per million tokens. If your documents total 100,000 tokens (~75k words), that’s about $0.01 for indexing – virtually negligible. Even a larger corpus of 1 million tokens is about $0.10. So embedding is very affordable.
- LLM queries: Using GPT-3.5-turbo, the cost is about $0.002 per 1K tokens. If each answer exchange is ~1500 tokens (including prompt and response), that’s ~$0.003 per question (one third of a cent). GPT-4 is more costly (roughly 15× GPT-3.5’s price per token), so an answer might cost a few cents. For example, a 2000-token GPT-4 response could cost around $0.06. If you plan to answer thousands of questions, these costs can accumulate, so it’s wise to estimate usage.
To put it in perspective: suppose you have 50 pages of documentation (maybe 20k tokens total). Indexing them might cost $0.002. Answering 100 questions with GPT-3.5 might cost around $0.30 in total. This is a tiny price for the capability gained, but you should still monitor your API usage via OpenAI’s dashboard to avoid surprises (especially if using GPT-4 or if the system is open to many users).
Tip: During development, you can reduce costs by using OpenAI’s cheaper models (or even dummy local models for testing integration). Also, load only a subset of documents while prototyping. Once confident, index the full dataset.
FAQ and Troubleshooting
My script can’t find the langchain or faiss module.
Make sure you installed all requirements (pip install -r requirements.txt). If you’re on an unusual platform (like Apple M1/M2), ensure you install faiss-cpu (the CPU-only wheel). If problems persist, try upgrading pip or installing packages individually. Also verify that you’re using the correct Python environment (e.g., your virtualenv).
I get an authentication error or InvalidRequestError from OpenAI.
This usually means your API key is missing or incorrect. Double-check that OPENAI_API_KEY is set in the environment that’s running the code. You can test by doing in Python: import os; print(os.getenv("OPENAI_API_KEY")) to ensure the key is loaded. Also confirm you have an active OpenAI billing plan – a new key with no billing may hit a hard limit quickly
The assistant’s answer is incomplete or it says it doesn’t know.
This can happen if the relevant info wasn’t retrieved or the LLM wasn’t sure. Try increasing the number of chunks (k) to, say, 5 or 6, especially if the answer may be spread across documents. Ensure your chunk size isn’t too small such that context got fragmented. You can also double-check that the data actually contains the answer. If not, the model will justifiably say it doesn’t know (which is good to avoid hallucination).
The answers are irrelevant or hallucinated.
If you consistently get off-base answers, something might be wrong in retrieval. Verify that embedding and retrieval are working:
1. Try a manual similarity search: vector_store.similarity_search("test query") and inspect the content of the top results to see if they match the query intent.
2. Ensure you use the same embedding model for query and documents (when using RetrievalQA chain via LangChain, it handles it internally).
3. If the vector index is empty or the query is not similar to any content, the LLM might default to a generic answer. In such cases, you might want to explicitly handle the “no relevant documents found” case by checking if retrieval returns anything and, if not, have the agent respond with “I don’t have information on that.”
How do I update the index with new or changed documents?
You have to re-run the ingestion and indexing steps. For a few new documents, you could load them and use vector_store.add_documents() to add to the existing index (and then save). However, the simplest approach is often to rebuild the index periodically if your data changes (since embedding is cheap for reasonable volumes). If using a persistent vector DB (like Chroma or Pinecone), you can upsert new vectors on the fly, but with FAISS we typically recreate or merge indices manually.
I ran the script twice and got different answers for the same question.
Minor variations can happen if the LLM’s randomness (temperature) is not zero. We set temperature=0 to minimize this. If it’s 0, the model should be mostly deterministic given the same prompt. Another source of difference could be if the vector store returned chunks in different order or if there were ties. In general, you should get consistent answers on repeated runs. If you need absolute determinism, ensure all non-deterministic factors (like any random shuffling in retrieval or multi-threading in API calls) are controlled.
How can I integrate this into a chatbot interface or an API?
Once the core logic works, you can wrap it in a simple Flask or FastAPI server, or even a chatbot UI library. For a quick test, you can create a loop in the script to prompt for user input in the console:while True:
q = input("Ask a question (or 'quit'): ")
if q.lower() in ["quit", "exit"]:
break
print("Answer:", qa_chain.run(q))
Can I use a different LLM or embedding model?
Absolutely. We chose OpenAI for convenience. You could swap in Cohere or HuggingFace embeddings by using the corresponding LangChain classes (e.g., HuggingFaceEmbeddings). For the LLM, LangChain supports many models – just ensure you have access and the model can accept the amount of context you provide. Keep in mind running local models (like Llama 2) might require additional setup and hardware (GPU), but it removes API costs. The retrieval part stays the same regardless of the model.
The FAISS index didn’t save / can’t load properly.
Check that the directory path you provided to save_local is correct and that your program has write permissions. It should create a folder (e.g., vector_index) with some files. To load, you must provide the same folder name and the same embeddings object (since the index doesn’t store the embedding model). If you use a new OpenAIEmbeddings() instance, that’s fine as long as it’s the same model. Also, note the allow_dangerous_deserialization=True flag in LangChain’s FAISS.load_local – as of LangChain 0.2.0, you might need this flag to load pickled data. If issues persist, you can always rebuild the index from scratch (re-embedding) as a fallback.







