
File compression is a process of encoding data using fewer bits. The data is encoded using a specific algorithm that reduces the size of the file. The smaller file size makes it easier to store and transmit the data. The compressed file can be decompressed using the same algorithm. In this blog, we’ll be talking about file compression and the algorithm behind it.
File compression can be achieved using software or hardware. Software compression is typically done using an algorithm, while hardware compression uses a dedicated chip to compress the data. Hardware compression is more efficient, but it is also more expensive.
What is File compression?
File compression is a process of encoding data using fewer bits. The data is encoded using a specific algorithm designed to utilize fewer bits. The most common form of file compression is known as lossless compression. This type of compression maintains the original data without any loss.
Lossless compression is typically used for text files, such as source code or documentation. It is also used for images, such as TIFF files.
Lossy compression is a type of file compression that uses irreversible methods to compress data. This means that some of the data is lost during the compression process.
Lossy compression is typically used for audio and video files. It is also used for images, such as JPEG files.
File compression can be used to reduce the size of a file or to compress multiple files into a single archive. File compression is often used when transferring files over the internet or when storing files on a storage device.
There are many different file formats that can be used for file compression. The most common file formats are ZIP, RAR, and 7z.
File compression can be performed using a variety of software programs. The most common software programs are WinRAR, 7-Zip, and WinZip.
Can File Compression cause data loss?
File compression is a process of encoding data using fewer bits. This is done by identifying and eliminating statistical redundancy in the data. When this is done, the resulting compressed file is usually smaller in size than the original file.
However, file compression can sometimes result in data loss. This is because when data is compressed, some of the information in the original file is lost. This can happen if the compression algorithm is not able to accurately identify and eliminate all of the redundancies in the data. As a result, the compressed file may be larger than the original file, or it may not be able to be decompressed correctly.
Does file compression reduce quality?
When you compress a file, it reduces the quality of the file. The amount by which it is reduced depends on the type of compression that is used. For example, when you use JPEG compression, it reduces the quality of the image. When you use ZIP compression, it reduces the quality of the file.
Different Methods of Data compression
Data compression is a form of coding that reduces the amount of data needed to represent a given piece of information. There are many different types of coding schemes, each with its own advantages and disadvantages. The most common type of coding used for data compression is Huffman coding.
Huffman coding is a lossless coding scheme that assigns variable-length codes to data symbols. The codes are assigned such that the shorter codes are used more frequently than the longer codes. This makes the overall code length shorter, on average than a fixed-length code. Huffman coding can be used to compress any type of data, including text, images, and audio.
There are two main types of data compression: lossless and lossy. Lossless compression ensures that the original data can be reconstructed exactly from the compressed data. Lossy compression sacrifices some accuracy in order to achieve greater compression ratios.
Lossless compression is typically used for text and images, where even a small loss of data can be noticeable. Lossy compression is often used for audio and video, where a slight loss of quality is less noticeable.
Data compression can be used to reduce the storage requirements of a file or to reduce the amount of data that needs to be transmitted over a network. When data is compressed, it can be decompressed using the same or a similar algorithm. This allows the data to be restored to its original form if desired.
There are many different algorithms that can be used for data compression. The most common are Lempel-Ziv (LZ) algorithms, which are used in many different file formats, including ZIP and gzip.
The LZ family of algorithms work by finding patterns in the data and replacing them with shorter codes. The most common LZ algorithm is LZW, which is used in the GIF image format.
Huffman coding is another common algorithm, which is used in the JPEG image format.
What is Huffman coding?
Huffman coding is a data compression technique that is used in a variety of applications, such as file compression and image compression. It is named after the inventor, David A. Huffman, who developed the algorithm in 1952.
Huffman coding works by taking advantage of the fact that some symbols occur more frequently than others. For example, in English text, the letter ‘e’ is the most common, followed by ‘t’, ‘a’, and so on. By assigning shorter codes to the more common symbols and longer codes to the less common symbols, we can compress a message.
To generate the Huffman code, we first need to calculate the frequencies of all the symbols in the message. We can then build a Huffman tree, which is a representation of the code that assigns shorter codes to the more common symbols and longer codes to the less common symbols.
The Huffman tree is constructed by starting with a forest of single nodes, one for each symbol. We then combine the two nodes with the lowest frequencies to create a new node, which is added back into the forest. This process is repeated until there is only one node left in the forest, which is the root node of the Huffman tree.
The code for each symbol is then generated by traversing the Huffman tree from the root to the leaf nodes. The code for each symbol is the sequence of 0s and 1s that are encountered along the path from the root to the leaf node. For example, the code for the letter ‘e’ might be ‘011’, ‘t’ might be ‘1000’, and so on.
Huffman coding is a very effective data compression technique and is used in a variety of applications. It is especially well-suited for files that contain a lot of repetition, such as text files.
If you’d like to read about code minification, I’d like to suggest you one of my articles
“Minification”.
Now, let’s focus on a program that will compress the file for us-
Converting to zip file:
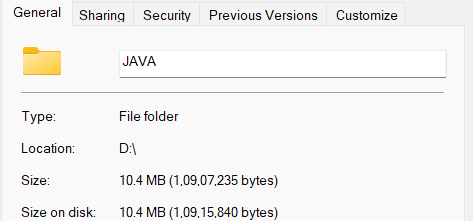
The first way we can compress a file is by converting it into a zip file. So let’s see if this code can compress our file “Java.pdf” which is 10.04 MB.
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.util.zip.ZipEntry;
import java.util.zip.ZipOutputStream;
import java.io.IOException;
public class FileCompression {
public static void main(String[] args)
{
try {
FileInputStream fis = new FileInputStream("Java.pdf");
FileOutputStream fos = new FileOutputStream("Java.zip");
ZipOutputStream zos = new ZipOutputStream(fos);
ZipEntry ze = new ZipEntry("Java.pdf");
zos.putNextEntry(ze);
byte[] buffer = new byte[1024];
int len;
while ((len = fis.read(buffer)) > 0)
{
zos.write(buffer, 0, len);
}
zos.closeEntry();
zos.close();
fis.close();
fos.close();
}
catch (IOException e)
{
e.printStackTrace();
}
}
}Meanwhile, let’s talk about how the zip file compresses the size of an actual file.
When you create a zip file, the files are compressed using a characters-based algorithm. This algorithm looks at each file and saves information about how often each character appears in that file. For example, if the letter “a” appears 100 times in a file, the zip file would just need to store the character “a” and the number “100”, instead of storing the character “a” 100 times. This compression method is very effective for files that have a lot of repetitive information, like text files.
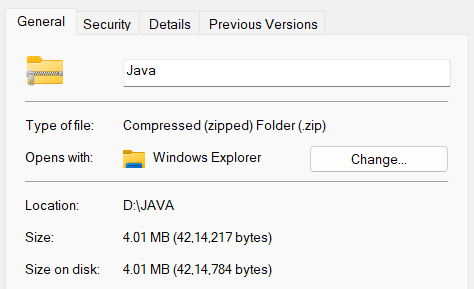
Yes, it does, now the size of the zip file is 4.01 MB.
So, this is one
Next, we’ll try to compress the file by actually converting it into another file with the same extension.
Let’s take the same file, i.e. “Java.pdf”. Its primary size was 10.4 MB.
import java.io.*;
public class FileCompressor {
public static void main(String[] args) {
try {
FileInputStream fis = new FileInputStream("Java.pdf");
FileOutputStream fos = new FileOutputStream("output.pdf");
int data;
while((data = fis.read()) != -1) {
fos.write(data);
}
fis.close();
fos.close();
}
catch(IOException e)
{
System.out.println("Error!");
}
}
}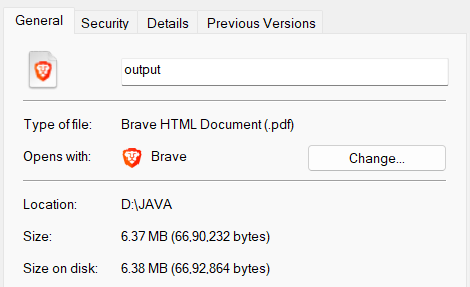
So, as you can see that the size of the output file is reduced to 6.37 MB. Although in zip file compression, we got the maximum compression this code can help you to compress the file size without changing its extension or type.
So this was all about File compression with two small examples. I hope this blog was helpful to you. If that is so, share it and follow us for more informative blogs like this.







