
In computer science, the union-find algorithm is an algorithm that tracks the disjoint sets (union-find data structure) of a collection of elements. It is also known as the merge–find algorithm, Kruskal’s algorithm, or Disjoint Set Union (DSU) algorithm.
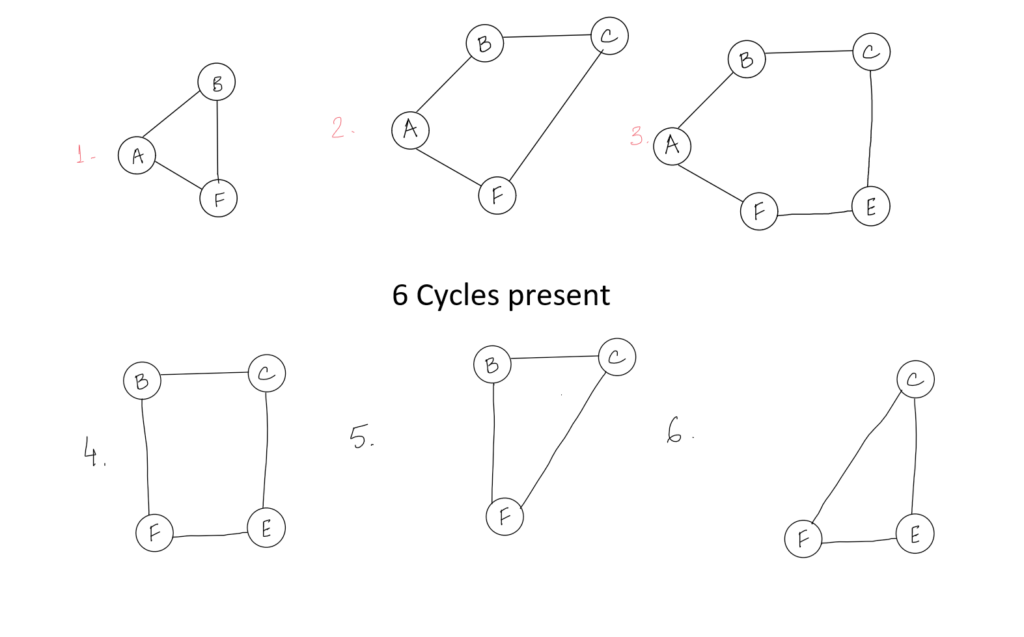
The algorithm is used in many practical applications, particularly in graph algorithms such as Kruskal’s algorithm and Borůvka’s algorithm for computing the minimum spanning forest and computational geometry. It can also be used for finding cycles in a graph.
The union-find algorithm has two main operations, union and find.
- Find: Find operation returns the representative (or root) of the set that an element x is a member of.
- Union: Union operation amalgamates two disjoint sets into a single set. It connects two sets by a path from one root to the other.
The union-find algorithm is also used in a number of other applications, such as percolation, Huffman coding, and numerous scheduling algorithms.
The union operation is also known as merge, and the find operation is also known as find set, find the root, or set representative.
The union-find algorithm is a classic example of a disjoint-set data structure, which maintains a collection of disjoint sets. The algorithm is also an example of an associative array, which is a data structure that can be used to implement a set.
The union-find algorithm can be used to solve a number of problems, such as the connectivity problem, the cycle detection problem, and the percolation problem.
The connectivity problem is to determine whether two elements are in the same set. The cycle detection problem is to determine whether a graph contains a cycle. The percolation problem is to determine whether a material will percolate (or flow) through a network of pores.
How does the Union-Find Algorithm work?
In computer science, the union-find algorithm is an algorithm that is used to track the disjoint sets. This algorithm is used in many applications, such as detecting cycles in a graph or finding connected components in a graph. The algorithm works by keeping track of the elements in each set and the relationships between the sets. When an element is added to a set, the algorithm checks to see if the element is already in another set. If the element is not in another set, then the algorithm creates a new set for the element. If the element is in another set, then the algorithm union finds the two sets by making the element the root of the set. The root of the set is the element that is in the set with the smallest element. The algorithm keeps track of the sizes of the sets so that it can quickly find the root of the set. If two sets are unconfined, then the sizes of the sets are added together.
The union-find algorithm is a very efficient algorithm that can be used in many applications. The algorithm is easy to implement and can be used to solve many problems.
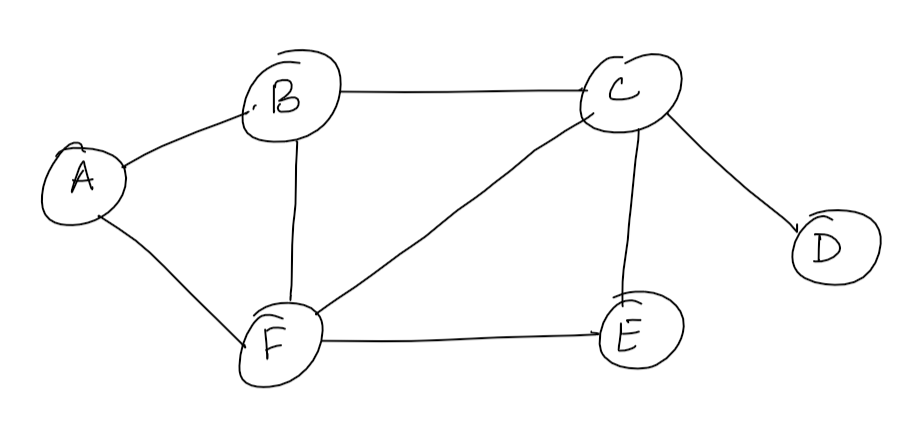
We will be using the Union Find algorithm to keep track of the connected components in an undirected graph. The algorithm works as follows:
- Initialise an array of size V, where V is the number of vertices in the graph. Let us call this array parent[ ]. Each entry parent[i] stores the name of the vertex that is the parent of vertex i. Initially, all entries of a parent[ ] are set to -1.
- Consider every edge in the graph, and check if the vertices connected by the edge have different parents. If they have different parents, then it means that they are not in the same connected component, and so we need to unite them. To do so, just set the parent of one of them (say vertex j) as the other one (say vertex i).
- After considering all edges, all vertices that have the same parent are in the same connected component.
The running time of the union-find algorithm is O(log n), where n is the number of elements in the disjoint set. This is because the union and find operations can be implemented with a path compression and union by rank heuristic, which reduces the time complexity to O(log n).
So, that’s all for this blog, hope you understood the union-find algorithm and did not get bored.
See you in my next blog.







