Follow Us:
How to Utilize Advanced Query Techniques in Spring Data JPA?

Spring Data JPA simplifies data access in Java applications, but complex scenarios often require advanced query techniques. This blog explores how to enhance your data retrieval and manipulation capabilities using JPQL, native SQL, and dynamic queries with Spring Data JPA. We will focus on practical examples that demonstrate how to write and optimize these advanced queries effectively. By mastering these techniques, you will be able to handle more complex data operations efficiently, making your applications more robust and responsive. Whether you are dealing with large datasets, complex relationships, or performance-critical applications, the skills you learn today will significantly improve your ability to develop and maintain powerful data access layers in your Spring applications.
Setting Up the Environment
To effectively use advanced query techniques in Spring Data JPA, you need a properly configured development environment. This section will guide you through setting up a Spring Boot project with Spring Data JPA and the necessary dependencies for our advanced querying examples.
Prerequisites
Before you begin, ensure you have the following installed:
- Java JDK: Java 8 or later.
- Maven or Gradle: These tools manage project dependencies and build configurations. Choose one based on your project’s needs or personal preference.
- An IDE: IntelliJ IDEA or Eclipse are recommended for their support of Spring applications and developer-friendly features. But you can use normal VS Code for the development as well.
Creating a New Spring Boot Project
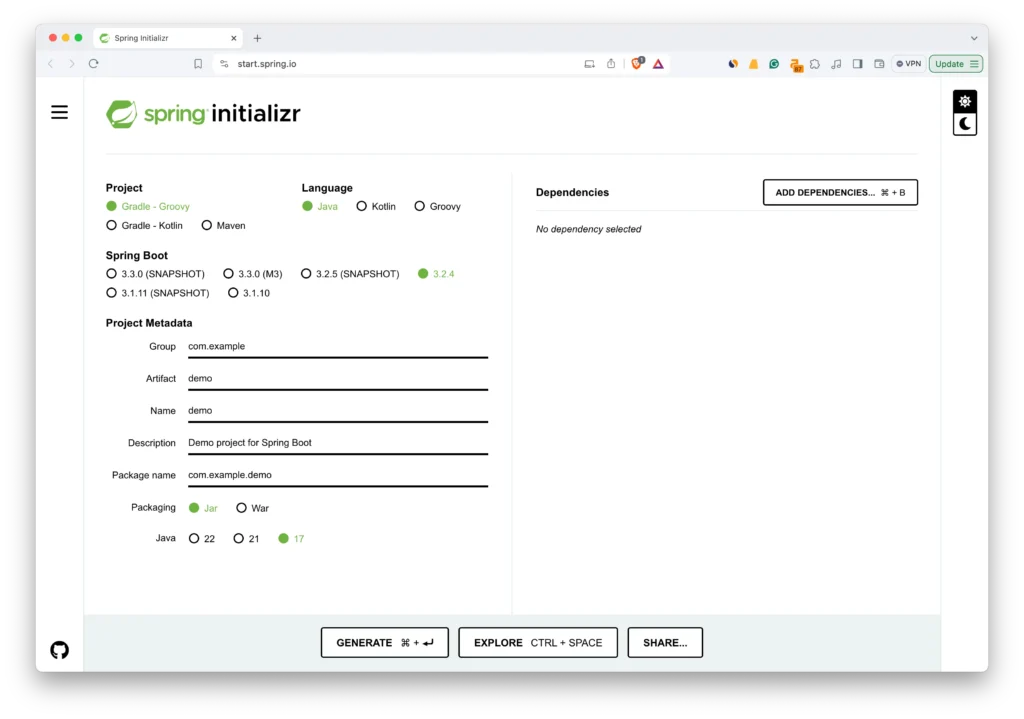
Follow these steps to create a new project using Spring Initializr:
- Navigate to Spring Initializr: This online tool helps you bootstrap a new Spring Boot project.
- Configure Your Project:
- Project Metadata: Fill in the Group and Artifact fields to define your project’s base package and name.
- Dependencies: Select the following:
- Spring Web: For building web applications.
- Spring Data JPA: To integrate Spring Data JPA.
- Database Driver: Choose H2, MySQL, or PostgreSQL. H2 is ideal for development due to its ease of use and setup as an in-memory database.
- Generate the Project: Click the “Generate” button to download your project setup as a zip file.
Setting Up the Project in Your IDE
After downloading, set up your project in Visual Studio Code to start coding:
- Extract the Zip File: Locate the downloaded zip file and extract it to a convenient location.
- Import the Project in Visual Studio Code:
- Open Visual Studio Code.
- Select
File > Open Folderand choose the extracted project directory.
Verify Your Setup
Before moving forward, make sure everything is configured correctly:
- Open the
DemoApplication.javafile: This is your main class, marked with@SpringBootApplication. - Run the Application: Use the built-in terminal in Visual Studio Code to execute the command
./mvnw spring-boot:run(for Maven) or./gradlew bootRun(for Gradle). Your application should start without any errors, confirming that your environment is set up properly. - Check the Console: Ensure there are no errors related to missing dependencies or configuration issues. If the setup is correct, you will see a message indicating that the application has started successfully.
This setup ensures that you have a robust development environment ready for exploring advanced query techniques in Spring Data JPA. Next, we will dive into understanding and implementing JPQL and native SQL queries.
Understanding JPQL and Native Queries
When working with Spring Data JPA, you often encounter two types of queries: JPQL (Java Persistence Query Language) and native SQL queries. Understanding the distinction and appropriate use cases for each can greatly enhance your database operations.
JPQL Queries
Java Persistence Query Language (JPQL) is a powerful abstraction above SQL that enables developers to write database queries based on entity model rather than database tables. This abstraction is crucial for maintaining the decoupling of application code from database-specific details, allowing applications to be more portable across different database systems.
Key Characteristics of JPQL:
- Object-Oriented: JPQL is designed to operate on the entity objects in your model. It understands entity relationships, inheritance, and polymorphism, mirroring Java’s object-oriented nature.
- Database Independent: JPQL queries are translated by the JPA provider into native SQL queries suitable for the active database, thus providing database independence. This means you can switch databases without rewriting your queries.
Example of Writing a JPQL Query:
Consider you have an entity Employee defined as follows:
@Entity
public class Employee {
@Id
private Long id;
private String name;
private Double salary;
private String department;
// Constructors, getters, and setters
}To retrieve all employees in a specific department whose salaries exceed a certain threshold, you might write a JPQL query as follows:
@Query("SELECT e FROM Employee e WHERE e.department = :department AND e.salary > :salary")
List<Employee> findEmployeesByDepartmentAndSalary(@Param("department") String department, @Param("salary") Double salary);This query demonstrates how JPQL allows the specification of conditions on entity fields directly, avoiding the need to translate these into database column names and SQL syntax.
Advantages of Using JPQL:
- Simplification: JPQL simplifies query construction, especially when dealing with complex joins and relationships between entities.
- Maintainability: Queries are easier to read and maintain because they are expressed in the domain model’s terms, which are usually more familiar to application developers than database schema details.
- Avoiding SQL Injection: By using parameterized queries, JPQL inherently protects against SQL injection attacks, improving the security of your application.
Considerations When Using JPQL:
While JPQL provides many benefits, there are scenarios where it might not be the best choice:
- Performance: For certain database-specific optimizations, direct SQL might be more efficient. JPQL may not always translate into the most optimized SQL, depending on the complexity of the query and the performance characteristics of the underlying database.
- Features Limitation: JPQL does not support every feature of SQL, such as certain types of joins or database-specific functions and operations. In such cases, falling back to native SQL might be necessary.
By understanding and leveraging the capabilities of JPQL, you can write more effective, efficient, and secure data access code in your Spring Data JPA applications. This knowledge forms the backbone of effective data handling strategies in enterprise applications, allowing for scalability and ease of maintenance.
Native SQL Queries
Native SQL queries offer direct access to the database using the specific syntax and features of the underlying database management system. This approach is useful when you need to leverage particular capabilities of the database that are not accessible or efficiently handled through JPQL.
Key Characteristics of Native SQL:
- Direct Database Access: Native SQL queries bypass the abstraction layer provided by JPQL, allowing you to write queries that are tailored to the specific features and optimizations of the database you are using.
- Flexibility and Control: This approach provides complete control over the SQL execution, enabling optimizations, complex joins, and usage of database-specific functions that may not be possible with JPQL.
Example of Writing a Native SQL Query:
Using the Employee entity from the previous example, suppose you need to perform a complex query that involves a window function—an SQL feature that JPQL does not support. You might write a native SQL query like this:
@Query(value = "SELECT e.*, SUM(e.salary) OVER (PARTITION BY e.department) AS department_salary FROM employees e WHERE e.salary > :salary", nativeQuery = true)
List<EmployeeProjection> findEmployeesAndDepartmentSalary(@Param("salary") Double salary);This query calculates the total salary per department for employees whose salary is above a certain threshold, using the SQL window function SUM() OVER(). Here, EmployeeProjection could be an interface or a DTO (Data Transfer Object) that includes additional fields like department_salary.
Advantages of Using Native SQL:
- Performance Optimization: Native queries can be fine-tuned to take advantage of database-specific optimizations, potentially offering better performance for certain operations than JPQL.
- Feature Utilization: Allows the use of advanced SQL features like custom functions, recursive queries, or complex joins that are not supported by JPQL.
Considerations When Using Native SQL:
While powerful, native SQL queries come with their own set of considerations:
- Portability Issues: These queries are tied to the specific syntax and features of the underlying database, which can make it harder to migrate your application to a different database platform.
- Increased Risk of SQL Injection: Unlike JPQL, which uses a more abstract and safer parameter handling mechanism, native SQL queries require careful handling of input 0arameters to avoid SQL injection vulnerabilities.
- Maintenance Challenges: Native SQL queries can be harder to maintain and understand, especially for developers who are not familiar with the specific SQL dialect being used.
By choosing native SQL judiciously, you can harness the full power of your database while managing the trade-offs related to portability and maintainability. This approach should be reserved for scenarios where the benefits clearly outweigh the potential downsides, such as in highly optimized or complex data manipulation operations.
Dynamic Queries with Querydsl
Querydsl is a framework that provides a flexible and type-safe way to write SQL-like queries in Java. It’s particularly useful when you need to construct dynamic queries based on conditions that are not known until runtime. This section explores how to integrate Querydsl into a Spring Data JPA project and leverage its capabilities to create flexible and maintainable queries.
Setting Up Querydsl
Before you can use Querydsl in your Spring Data JPA project, you need to add the necessary dependencies and configure your project to support it.
Add Querydsl Dependencies:
For Maven, add the following dependencies to your pom.xml:
<dependency>
<groupId>com.querydsl</groupId>
<artifactId>querydsl-apt</artifactId>
<version>${querydsl.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.querydsl</groupId>
<artifactId>querydsl-jpa</artifactId>
<version>${querydsl.version}</version>
</dependency>For Gradle, include these in your build.gradle:
implementation "com.querydsl:querydsl-jpa:${querydslVersion}"
annotationProcessor "com.querydsl:querydsl-apt:${querydslVersion}:jpa"Configure Querydsl Annotation Processor:
Ensure your build tool is configured to process annotations. This is required to generate Q-classes from your entity classes, which are used to construct type-safe queries.
Writing Dynamic Queries with Querydsl
Once Querydsl is set up, you can start writing dynamic queries. Here’s how you can create a query dynamically based on runtime conditions:
- Create Q-classes:
Q-classes are generated automatically during the build process for each JPA entity. For instance, if you have anEmployeeentity, aQEmployeeclass will be generated. - Use Querydsl Predicate and BooleanBuilder:
BooleanBuilderis a Querydsl class that allows you to construct complex conditional queries dynamically.
Example of a Dynamic Query:
Suppose you want to find employees based on dynamically provided criteria such as department and salary. Here’s how you might write the query:

import com.querydsl.core.BooleanBuilder;
import com.querydsl.jpa.impl.JPAQuery;
public List<Employee> findEmployeesByDynamicFilter(String department, Double minSalary) {
QEmployee qEmployee = QEmployee.employee;
BooleanBuilder builder = new BooleanBuilder();
if (department != null) {
builder.and(qEmployee.department.eq(department));
}
if (minSalary != null) {
builder.and(qEmployee.salary.gt(minSalary));
}
JPAQuery<Employee> query = new JPAQuery<>(entityManager);
return query.select(qEmployee)
.from(qEmployee)
.where(builder)
.fetch();
}Benefits of Using Querydsl
- Type Safety: Querydsl reduces the risk of syntax errors in your queries, as they are checked at compile time.
- Dynamic Query Construction: Easily construct queries dynamically based on varying criteria without concatenating strings or worrying about SQL injection.
- Readability: Querydsl queries are close to plain SQL in their structure, making them easy to read and maintain.
Querydsl is a powerful tool for any developer needing to write complex, dynamic queries in a Java application using Spring Data JPA. It offers both the flexibility to handle any query requirement and the safety of static typing, enhancing the robustness and maintainability of your data access layer.
Query Optimization Techniques
Efficient query performance is crucial for the scalability and responsiveness of any application using Spring Data JPA. This section covers several techniques to optimize your queries and ensure that your application handles data retrieval and manipulation efficiently.
1. Use of Indexes
Indexes are critical for improving the performance of data retrieval operations on a database. An appropriately indexed column can drastically reduce the time it takes for your database to locate the data needed by your queries.
- Best Practices for Indexing:
- Index columns that are frequently used in
WHEREclauses. - Consider indexing columns used in
ORDER BY,GROUP BY, andJOINconditions. - Avoid over-indexing as it can degrade performance on inserts, updates, and deletes.
2. Selective Querying
Fetching only the necessary data that your application needs can reduce memory consumption and improve query response times.
- Projection Queries:
- Use DTOs (Data Transfer Objects) or interface-based projections to retrieve only the required fields rather than fetching entire entity objects.
Example of a Projection Query in Spring Data JPA:
public interface EmployeeSummary {
String getName();
Double getSalary();
}
@Query("SELECT e.name as name, e.salary as salary FROM Employee e WHERE e.department = :department")
List<EmployeeSummary> findEmployeeSummaryByDepartment(@Param("department") String department);3. Effective Joins
Understanding how to effectively use joins can significantly impact the performance of your queries, especially when dealing with large datasets.
- Control Fetching Strategy:
- Use
JOIN FETCHto eagerly load associated collections or entities when you know you will need them immediately. - Use
JOINorLEFT JOINwithoutFETCHto manage the lazy loading of associations, thus avoiding unnecessary data loading.
4. Batch Processing
For operations that need to handle large volumes of data, such as bulk inserts or updates, batch processing can be highly effective.
- Spring Data JPA Batch Techniques:
- Use
@Modifyingand@Transactionalannotations for bulk update and delete operations. - For large inserts, consider using a batch insert technique or a JDBC
BatchPreparedStatementSetterto optimize performance.
Example of Batch Insert Using JdbcTemplate:
jdbcTemplate.batchUpdate("INSERT INTO employees (name, salary) VALUES (?, ?)", new BatchPreparedStatementSetter() {
public void setValues(PreparedStatement ps, int i) throws SQLException {
Employee employee = employees.get(i);
ps.setString(1, employee.getName());
ps.setDouble(2, employee.getSalary());
}
public int getBatchSize() {
return employees.size();
}
});5. Query Caching
Caching is a powerful mechanism to reduce the load on your database by storing the results of frequently accessed queries.
- Configure Query Cache:
- Use the second-level cache and query cache features of your JPA provider (e.g., Hibernate) to cache the results of queries.
- Be strategic about what queries are cached and set appropriate time-to-live (TTL) values based on how often the underlying data changes.
6. Analyzing Query Performance
Regularly monitor and analyze the performance of your queries. Tools like the SQL execution log, JPA provider statistics, or integration with application performance management (APM) tools can provide insights into query performance and potential bottlenecks.
- Use of EXPLAIN PLAN:
- Most databases support an
EXPLAIN PLANfeature, which shows how a database executes a SQL query. Use this feature to understand and optimize query paths.
By implementing these query optimization techniques, you can significantly improve the performance and scalability of your Spring Data JPA application. These practices not only ensure faster response times but also contribute to a more efficient and robust application architecture.
Testing Your Queries
Testing is a crucial aspect of developing with Spring Data JPA, ensuring that your queries perform as expected and handle edge cases properly. This section outlines effective strategies for testing your queries within a Spring framework.
1. Unit Testing Repositories
Unit tests help verify the logic of your repository interfaces independently from the rest of your application. Spring Data JPA makes it straightforward to write unit tests with the support of the Spring Test Context Framework.
- Setup:
- Use
@DataJpaTestto provide a subset of components necessary for testing the data layer. - Configure an in-memory database like H2 to ensure that tests are not only isolated from your production database but also consistent and repeatable.
- Use
Example of a Unit Test:
@RunWith(SpringRunner.class)
@DataJpaTest
public class EmployeeRepositoryTests {
@Autowired
private TestEntityManager entityManager;
@Autowired
private EmployeeRepository employeeRepository;
@Test
public void whenFindByDepartment_thenReturnEmployees() {
// given
Employee john = new Employee("John Doe", "Sales");
entityManager.persist(john);
entityManager.flush();
// when
List<Employee> foundEmployees = employeeRepository.findByDepartment(john.getDepartment());
// then
assertThat(foundEmployees).hasSize(1).extracting(Employee::getName).containsOnly(john.getName());
}
}2. Integration Testing
Integration tests assess the interaction between components and typically involve the actual database and configuration.
- Setup:
- Use
@SpringBootTestto load the full application context. - Use
TestRestTemplateorMockMvcfor testing REST controllers if your JPA repositories are accessed through web controllers.
- Use
Example of an Integration Test:
@RunWith(SpringRunner.class)
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
public class EmployeeIntegrationTests {
@Autowired
private TestRestTemplate restTemplate;
@Test
public void testEmployeeEndpoints() {
ResponseEntity<Employee> response = restTemplate.postForEntity("/employees", new Employee("Alice", "IT"), Employee.class);
assertEquals(HttpStatus.CREATED, response.getStatusCode());
Employee employee = response.getBody();
assertNotNull(employee);
ResponseEntity<Employee[]> employees = restTemplate.getForEntity("/employees", Employee[].class);
assertTrue(employees.getBody().length > 0);
}
}3. Query Performance Testing
While functionality testing is essential, performance testing your queries can prevent future scalability issues.
- Tools and Approaches:
- Use logging frameworks to log slow queries.
- Integrate with tools like JMeter or Apache Bench for stress testing your database queries under load.
- Monitor query performance and optimize as necessary using database profiling tools.
4. Edge Case Testing
Edge cases, such as zero results, exceptionally large datasets, or potential SQL injections, should be tested to ensure the robustness of your application.
- Strategies:
- Include tests that pass unexpected inputs to your queries to see how they handle them.
- Check for SQL injection vulnerabilities especially if you use native queries.
Testing your queries comprehensively in Spring Data JPA ensures that your application behaves predictably under different scenarios and maintains high performance as it scales. This not only assures quality but also helps in maintaining and troubleshooting the application effectively.
Troubleshooting Common Issues
When working with Spring Data JPA, encountering various issues can impact your application’s performance and reliability. This section discusses common problems and provides strategies for effectively troubleshooting them.
- Lazy Loading Issues:
One common challenge is theLazyInitializationExceptionor data not being loaded as expected. To resolve this, ensure that the Hibernate session is still open when lazy loading is triggered, typically by accessing the data within the scope of a transaction. Alternatively, consider usingfetch = FetchType.EAGERfor frequently accessed relationships or explicitly fetching related data in your queries usingJOIN FETCH. - Transaction Management:
Transactions not behaving as expected can lead to data inconsistency or performance bottlenecks. Review your transaction boundaries and use@Transactionalwisely to ensure that transactions are started and committed at appropriate times in your application flow. Monitor transaction times and rollback behaviors to identify and address any issues. - Query Performance:
Slow or resource-intensive queries can severely impact application performance. To address this, enable SQL logging to identify slow queries. Tools like Hibernate Statistics can help pinpoint inefficiencies. Optimize queries by adding indexes, adjusting join types, and reducing fetched data volumes. If JPQL queries are inefficient, consider rewriting them using native SQL. - Mapping Errors:
JPA mapping exceptions such asEntityNotFoundExceptionor issues related to column and table mappings can occur. Verify your entity mappings against the database schema to ensure all annotations are correctly configured and the database schema matches your entity definitions. Use a schema validation tool or enable schema validation in your JPA provider to catch discrepancies at startup. - Concurrency Issues:
Concurrency conflicts, such as lost updates in a multi-user environment, are another common issue. Implement optimistic locking with@Versionto use a version field in the entity to detect conflicting updates. Design your application to handleOptimisticLockExceptiongracefully, potentially by retrying the operation or notifying the user. - Configuration Problems:
Misconfigurations can lead to errors at application startup or runtime. Double-check yourapplication.propertiesorapplication.ymlfor correct database connection settings, JPA provider specifics, and Hibernate properties. Ensure that all necessary dependencies are correctly configured in your build file and that no conflicting versions are included.
Understanding these issues and knowing how to address them can significantly enhance your ability to maintain a robust and efficient application using Spring Data JPA. Troubleshooting effectively not only resolves current problems but also strengthens your application against potential future issues.
Conclusion
Throughout this guide, we’ve explored advanced querying techniques with Spring Data JPA, diving into the intricacies of JPQL, native SQL, and dynamic queries with Querydsl. We’ve also covered essential optimization strategies to enhance performance and provided tips for effectively testing and troubleshooting your queries.
Mastering these advanced techniques will enable you to handle complex data operations more efficiently, improve the performance of your applications, and ensure your queries are robust and secure. As you integrate these skills into your development practice, continue to experiment with the various tools and approaches discussed. This will not only broaden your expertise but also significantly contribute to your projects’ success.
Remember, the key to effective data management in Spring Data JPA lies in understanding the tools at your disposal and knowing when and how to apply them. Keep refining your approach, stay updated with the latest JPA features, and your efforts will lead to highly efficient and maintainable applications.
FAQs:
Can I use native SQL for updates and deletes in Spring Data JPA?
Yes, you can use native SQL for update and delete operations. You must annotate the repository method with @Modifying and @Query, specifying nativeQuery = true. It’s essential to also annotate the method with @Transactional to ensure the changes are committed.
How do I handle pagination and sorting with dynamic queries in Querydsl?
Querydsl supports pagination and sorting directly in the query construction. You can use the Pageable interface to pass pagination and sorting parameters to your Querydsl queries. Combine QSort with PageRequest to dynamically apply sorting and pagination to your results.
What is the best way to manage complex entity graphs in JPQL queries to avoid the N+1 select problem?
To manage complex entity graphs without triggering the N+1 selects issue, use entity graph annotations like @NamedEntityGraph to specify fetch graphs or load graphs. These annotations help you define which relationships should be eagerly fetched or loaded on a per-query basis.
Is it possible to use SQL window functions in Spring Data JPA?
While JPQL does not support window functions, you can use them in native SQL queries within Spring Data JPA. Define your query using the @Query annotation and set nativeQuery = true to execute it as native SQL, allowing the use of database-specific features like window functions.
How can I improve the performance of batch insert operations in Spring Data JPA?
To optimize batch insert operations, configure batch processing settings in your JPA provider (e.g., Hibernate). Adjust properties such as hibernate.jdbc.batch_size and ensure that hibernate.order_inserts and hibernate.order_updates are enabled to allow efficient reordering of insertion and update statements. Additionally, consider using a JDBC BatchPreparedStatementSetter or Spring’s JdbcTemplate for executing batch operations directly.