AWS Lambda, a cornerstone of serverless computing, offers developers the flexibility to run code in response to triggers without the need to manage servers. This capability, when combined with the power of machine learning, opens up a myriad of possibilities for creating applications that are not only scalable but also intelligent, and capable of making decisions in real-time based on incoming data.
This guide is designed to walk you through the essential steps of preparing your machine learning model, setting it up within AWS Lambda, deploying it effectively, and ensuring it can seamlessly integrate with data sources to provide real-time insights. Whether you’re looking to enhance user experiences, streamline operations, or unlock new analytical capabilities, the integration of AWS Lambda with machine learning models is a powerful strategy.
Suppose your deployment strategy involves using AWS Batch and Amazon SageMaker for training and deploying machine learning models. In that case, you might find additional insights and guidance in our blog: “How to use AWS Batch and Amazon SageMaker to train and deploy machine learning models?”. This resource is tailored for those looking to leverage the batch processing capabilities of AWS Batch along with the comprehensive machine learning environment provided by Amazon SageMaker.
By the end of this article, you will have a clear understanding of how to bring your machine-learning models into the AWS Lambda environment, enabling you to deploy applications that are not only responsive in real time but also imbued with the predictive power of machine learning.
Step 1: Preparing Your Machine Learning Model
To ensure the successful integration of your machine learning model with AWS Lambda, it’s essential to prepare it meticulously. This preparation involves optimizing the model for performance and size and then serializing it for deployment. Here’s how to do it:
1.1 Optimize Model Performance
- Choose the Right Algorithm: Select an algorithm that offers a good balance between prediction accuracy and computational efficiency. For instance, if you’re working with large datasets, consider using a more efficient variant of your current algorithm.
- Hyperparameter Tuning: Use techniques like grid search or random search to find the optimal set of hyperparameters that improve your model’s performance without significantly increasing its computational needs.
- Feature Selection: Reduce the number of input features to the essential ones. This not only improves model efficiency but also reduces the complexity of data processing in Lambda.
1.2 Reduce Model Size
- Model Pruning: This involves removing parts of the model that have little or no impact on its output, such as weights close to zero in neural networks.
- Quantization: Convert the model’s floating-point numbers to integers, which reduces the model size and speeds up inference without a substantial loss in accuracy.
- Model Distillation: Train a smaller, more efficient model (the “student”) to replicate the performance of a larger, pre-trained model (the “teacher”).
1.3 Serialize the Model
- Choose Serialization Format: For Python models,
pickleis a common choice. For models that require cross-platform compatibility, consider using ONNX. - Serialize and Save the Model: Use the appropriate library functions to serialize your model. For example, with
pickle, you would usepickle.dump(model, file). - Compress the Serialized File: If the serialized file is still too large, compress it using formats like ZIP to reduce its size further.
1.4 Test the Model Locally
- Simulate AWS Lambda Environment: Use tools like AWS SAM CLI or Docker to mimic the Lambda environment on your local machine.
- Run the Model: Load the serialized model in this simulated environment and test it with sample inputs to ensure it performs as expected.
- Monitor Performance Metrics: Pay attention to execution time and memory usage, as these are critical for the smooth functioning of your model in Lambda.
By following these detailed steps, you prepare your machine learning model not just for successful deployment, but also for optimal performance within AWS Lambda’s unique environment. This preparation is key to leveraging the full potential of real-time predictions in serverless architectures.
Step 2: Setting Up AWS Lambda
After preparing your machine learning model, the next step is to set up AWS Lambda for its deployment. This involves creating a new Lambda function, configuring the runtime environment, and setting the necessary permissions. Here’s how to proceed:
2.1 Create a New Lambda Function
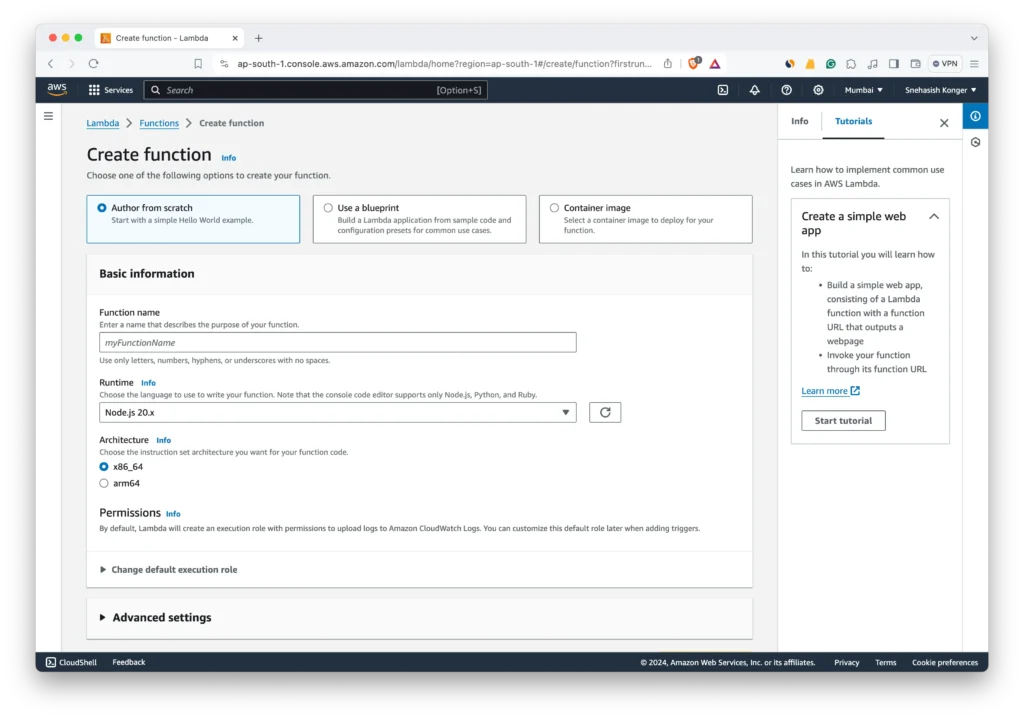
- Access AWS Management Console: Log in to your AWS account and navigate to the Lambda service.
- Create Function: Click on the “Create function” button. Choose “Author from scratch” to start setting up your new function.
- Function Configuration:
- Name: Give your function a descriptive name.
- Runtime: Select the runtime that matches your model’s programming language, like Python or Node.js.
- Choose or Create an Execution Role:
- If you already have an execution role with the necessary permissions, select it.
- If not, create a new role from AWS policy templates and assign it the necessary permissions, such as access to Amazon S3 for model retrieval.
2.2 Configure Environment and Resources
- Memory and Timeout Settings:
- Set the memory based on your model’s requirements. AWS Lambda allows up to 10,240 MB.
- Configure the timeout setting, keeping in mind the maximum execution duration is 15 minutes.
- Environment Variables:
- Set environment variables if your Lambda function requires them, like paths to model files or other configuration settings.
- VPC Settings (Optional):
- If your Lambda function needs to access resources within a VPC, configure the VPC settings accordingly.
2.3 Upload Code and Dependencies
- Prepare Deployment Package:
- If your function is simple and written directly in the AWS Lambda console, you can write the code in the inline editor.
- For more complex functions, prepare a deployment package containing your code and any dependencies. This might be a .zip file or a container image, depending on your setup.
- Upload Deployment Package:
- For a .zip file, upload it directly through the Lambda console.
- For a container image, upload it to Amazon Elastic Container Registry (ECR), and then specify the image URI in your Lambda function configuration.
- Set Handler Name:
- Specify the handler name, which is the entry point for your Lambda function (e.g.,
main.handlerwheremainis the file name andhandleris the function name).
- Specify the handler name, which is the entry point for your Lambda function (e.g.,
2.4 Test the Function
- Configure a Test Event:
- In the AWS Lambda console, create a new test event with sample input data.
- Invoke the Function:
- Run the test event to ensure your Lambda function is set up correctly and can execute without errors.
By following these steps, you set up an AWS Lambda function tailored to run your machine learning model. This setup is crucial for ensuring that your model runs efficiently and reliably in the cloud, enabling real-time predictions for your applications.
Step 3: Deploying the ML Model to AWS Lambda
With your AWS Lambda function set up, the next crucial step is deploying your machine learning model to it. This process involves uploading the model to a suitable storage service, linking it to your Lambda function, and ensuring the function can load and use the model correctly. Here’s how to accomplish this:
3.1 Upload the Model to Amazon S3
- Prepare the Model File: Ensure your model is serialized and compressed if necessary, as discussed in Step 1.
- Access Amazon S3: Log into the AWS Management Console and navigate to the Amazon S3 service.
- Create a New Bucket or Use an Existing One:
- If you don’t have a suitable S3 bucket, create a new one by clicking “Create bucket”. Follow the prompts to configure it.
- If you already have a bucket, you can use it to store your model.
- Upload the Model:
- Click “Upload” in your chosen bucket and select your model file for upload.
- After uploading, note the file path and bucket name, as you’ll need them for your Lambda function.
3.2 Update Lambda Function to Load the Model
- Modify Lambda Handler Code:
- In your Lambda function code, add logic to download the model file from S3 when the function is invoked.
- Use AWS SDKs (e.g., Boto3 for Python) to interact with S3.
- Load the Model in the Function:
- After downloading, deserialize the model within the Lambda function so it’s ready for making predictions.
- Ensure the code handles model loading efficiently to minimize the cold start time.
3.3 Set Permissions for Lambda to Access S3
- Update the Execution Role:
- Go to the IAM role associated with your Lambda function.
- Attach policies that grant read access to the specific S3 bucket where your model is stored.
3.4 Test the End-to-End Functionality
- Create a Test Event in Lambda Console:
- Use a sample input that your model expects for making predictions.
- Invoke the Function with the Test Event:
- Ensure the function executes correctly, accesses the model from S3, loads it, and returns the expected prediction.
- Monitor Logs and Outputs:
- Check CloudWatch logs for any errors or issues and validate the output is as expected.
By completing these steps, your machine-learning model is now successfully deployed to AWS Lambda. It’s ready to provide real-time predictions, leveraging the scalability and efficiency of serverless computing. This deployment is a significant stride in creating responsive, data-driven applications.
Step 4: Integrating with Data Sources for Real-time Predictions
Once your machine learning model is deployed on AWS Lambda, the next step is to integrate it with data sources for real-time predictions. This involves setting up triggers and data processing mechanisms to feed data into your Lambda function and utilize the model for on-the-fly predictions. Here’s how to set up this integration:
4.1 Set Up Triggers for Data Input
- Choose a Trigger Source:
- Depending on your application, select an appropriate trigger for your Lambda function. Common options include Amazon API Gateway for HTTP requests, Amazon Kinesis for streaming data, or AWS IoT for sensor data.
- Configure the Trigger:
- In the AWS Lambda console, link your function to the chosen trigger.
- For API Gateway, create an API endpoint that your application can call with data.
- For Kinesis or IoT, configure the stream or device to invoke your Lambda function with incoming data.
4.2 Process Incoming Data
- Handle Data in Lambda Function:
- Modify your Lambda function code to parse and preprocess the incoming data. This might involve data cleaning, normalization, or transformation to match the input format expected by your model.
- Error Handling:
- Implement robust error handling in your Lambda function to manage malformed data or other issues gracefully.
4.3 Generate Real-time Predictions
- Invoke the ML Model:
- With the processed data, invoke your machine learning model within the Lambda function to generate predictions.
- Format the Output:
- Structure the prediction output in a format suitable for your application’s needs, whether it’s a direct response to an API call or a message to another AWS service.
4.4 Test the Integration
- Simulate Real-time Data:
- Create test events or use tools to simulate the data input from your chosen trigger source.
- Monitor the Function Execution:
- Use AWS CloudWatch to monitor the execution of your Lambda function, ensuring it triggers correctly and processes data as expected.
- Validate Predictions:
- Check the accuracy and timeliness of predictions made by your model in response to the incoming data.
By following these steps, you integrate your AWS Lambda function with real-time data sources, enabling your machine-learning model to deliver immediate insights. This integration is key to leveraging the full potential of serverless architectures for responsive, data-driven decision-making.
Step 5: Monitoring and Optimization
After deploying your machine learning model to AWS Lambda and integrating it with data sources for real-time predictions, the final step is to monitor and optimize its performance. Effective monitoring helps ensure that your Lambda function operates efficiently, while optimization can reduce costs and improve response times. Here’s how to approach this:
5.1 Monitoring AWS Lambda Performance
- Use AWS CloudWatch:
- AWS CloudWatch is a powerful tool for monitoring AWS services. Set it up to track various metrics of your Lambda function, such as invocation count, error rates, execution duration, and memory usage.
- Set Alarms and Notifications:
- Configure CloudWatch alarms to notify you when certain thresholds are crossed, like high error rates or long execution times, indicating potential issues with your Lambda function or the integrated model.
- Analyze Logs:
- Regularly review the logs generated by your Lambda function for errors or unusual activity. These logs can provide insights into the function’s performance and help identify areas for improvement.
5.2 Optimizing Lambda Function
- Adjust Memory and Timeout Settings:
- Based on the performance data, adjust the memory allocation for your Lambda function. Sometimes, increasing memory can reduce execution time, which might lower overall costs.
- Fine-tune the timeout setting to ensure that your function has enough time to process data and generate predictions without wasting resources.
- Optimize Code and Model Performance:
- Review your Lambda function’s code and the machine learning model for any inefficiencies. Optimizing code and using a more efficient model can reduce execution time and resource usage.
- Consider implementing caching mechanisms if your model frequently makes similar predictions.
- Review and Update IAM Policies:
- Ensure that the IAM role associated with your Lambda function has only the necessary permissions, following the principle of least privilege.
5.3 Cost Optimization
- Monitor and Analyze Costs:
- Use AWS Cost Explorer to understand the costs associated with your Lambda function and related services.
- Look for patterns or spikes in cost that might indicate inefficient usage.
- Implement Cost-Saving Strategies:
- If your Lambda function is invoked frequently, consider using Reserved Concurrency to save on costs.
- For functions with infrequent invocations, ensure you are not over-allocating resources.
5.4 Continuous Improvement
- Iterate Based on Feedback and Data:
- Use the insights gained from monitoring and optimization efforts to make continuous improvements to your Lambda function and machine learning model.
- Regularly update the model and function code to adapt to changing requirements or data patterns.
By diligently monitoring and optimizing your AWS Lambda function, you ensure that your real-time prediction system remains efficient, cost-effective, and reliable. This ongoing process is crucial for maintaining the high performance of your serverless machine-learning applications.
Conclusion
In this guide, we’ve detailed a comprehensive approach to integrating machine learning models with AWS Lambda to achieve efficient and scalable real-time predictions. This process encompasses several critical steps, from the initial preparation of your machine learning model to ensure it’s optimized for the serverless environment, to the deployment and operational monitoring within AWS Lambda.
Key Takeaways:
- Model Preparation: The foundation of a successful integration lies in effectively preparing and optimizing your machine learning model. This ensures it not only performs well but also fits within the constraints of AWS Lambda.
- AWS Lambda Setup: Setting up AWS Lambda correctly is crucial. This involves configuring the function, setting appropriate permissions, and ensuring the environment is primed for your model.
- Model Deployment: Deploying your model to AWS Lambda involves uploading it to an accessible storage solution like Amazon S3, and then linking it to your Lambda function. This step is vital for enabling your function to load and execute the model.
- Data Integration: For real-time predictions, integrating your Lambda function with data sources is key. This allows your model to receive and process data on the fly, providing valuable insights instantly.
- Monitoring and Optimization: Post-deployment, monitoring your Lambda function’s performance through tools like AWS CloudWatch is essential for identifying and addressing any operational issues. Regular optimization efforts ensure that your deployment remains cost-effective and efficient.
Moving Forward: As you implement these steps, remember that the landscape of technology and machine learning is ever-evolving. Continuous learning, testing, and adaptation are necessary to keep your real-time prediction systems at the forefront of efficiency and effectiveness. Regularly revisit your model’s performance, the configuration of your AWS Lambda function, and the integration with data sources to identify opportunities for improvement.
By adhering to these guidelines, you’re well-equipped to leverage AWS Lambda and machine learning models to their fullest potential, driving forward the capabilities of your applications with real-time analytics and insights. This journey doesn’t end with deployment; it evolves with each new dataset, user interaction, and technological advancement, ensuring your applications remain responsive and intelligent in an ever-changing digital landscape.
Happy Coding !!







