
HTML parsing plays a crucial role in the world of web development, enabling us to extract meaningful information from web pages and manipulate their content. As a fundamental process in understanding and working with HTML documents, parsing allows us to interpret the structure and elements within a webpage accurately. In this in-depth blog, we will explore the intricacies of HTML parsing, step-by-step explanations of the process, and delve into different HTML and XHTML parsers.
HTML, short for HyperText Markup Language, serves as the backbone of the web, providing structure and semantics to web pages. Understanding the inner workings of HTML parsing is essential for developers and designers who want to create, analyze, or modify web content programmatically.
At its core, HTML parsing involves breaking down an HTML document into its constituent parts and constructing a representation known as the Document Object Model (DOM). This process allows us to traverse and manipulate the various elements and attributes within an HTML document accurately. By comprehending the nuances of HTML parsing, developers can create powerful tools, automate tasks, extract data, and even build web crawlers or scrapers.
In this blog, we will explore the HTML parsing process in detail. We will start by gaining a solid understanding of HTML itself, examining its structure, elements, and attributes. From there, we will dive into the step-by-step explanation of the HTML parsing process, covering tokenization, tree construction, and error handling.
Understanding HTML
HTML, the acronym for HyperText Markup Language, is the standard markup language used for creating web pages. It provides the structural foundation and defines the elements that make up the content on the World Wide Web. HTML uses a set of tags and attributes to structure and describe the different parts of a web page.
Basic structure of an HTML document:
An HTML document is structured using a set of elements that define the various components of a web page. Here is an overview of the basic structure of an HTML document:
- Document Type Declaration (DOCTYPE):
The DOCTYPE declaration specifies the version of HTML being used. It is placed at the beginning of an HTML document and helps browsers interpret the markup correctly. - HTML:
The HTML element serves as the root element of an HTML document. It encompasses the entire structure of the web page. - Head:
The head element contains metadata about the HTML document, such as the page title, character encoding, linked stylesheets, and JavaScript files. It does not directly contribute to the visible content of the page. - Body:
The body element encapsulates the visible content of the web page, including text, images, links, headings, paragraphs, and other elements that make up the actual content.
Elements, tags, and attributes in HTML:
HTML consists of a wide range of elements that define the structure and content of a web page. Each element is represented by an opening tag () and a closing tag (), with the content placed between them. Some elements are self-closing and do not require a closing tag.
Tags are the building blocks of HTML and are used to enclose elements. They are written inside angle brackets (< and >) and come in pairs: opening tags and closing tags.
Attributes provide additional information about elements and are specified within the opening tag. They are composed of a name-value pair and are used to modify the behavior or appearance of an element.
Example:
<p class="intro">This is a paragraph element with a class attribute.</p>In this example, the <p> tag represents a paragraph element. The class attribute, denoted by class="intro", provides a CSS class name for styling or targeting the element.
HTML Parsing Process:
To fully grasp the concept of HTML parsing, let’s explore its definition and then dive into a step-by-step explanation of the entire process. We’ll cover tokenization, the tokenization algorithm, tree construction, and error handling strategies.
HTML parsing refers to the process of analyzing an HTML document and extracting its structural components, such as tags, attributes, and content, to create a structured representation of the document. It involves breaking down the raw HTML code into manageable units and constructing a tree-like structure known as the Document Object Model (DOM) tree.
HTML parsing is essential for various tasks, including web scraping, data extraction, search engine indexing, and dynamically manipulating web content. By parsing HTML, developers can access and manipulate specific elements within a document, extract relevant data, or apply styling and interactivity to web pages programmatically.
Step-by-step explanation of the HTML parsing process:
In this section, we will dive into a detailed explanation of the HTML parsing process, which consists of several crucial steps. These steps include tokenization, tokenization algorithm, tree construction, and error handling. Let’s explore each step in depth.

Tokenization:
Tokenization is a fundamental step in the HTML parsing process, responsible for breaking down the raw HTML code into smaller units called tokens. Tokens represent distinct components of the HTML document, such as tags, text content, attributes, comments, and DOCTYPE declarations. By tokenizing the HTML code, the parser gains a structured understanding of the document’s structure and content, enabling further processing and analysis.
- Breaking HTML code into tokens:
During tokenization, the parser scans the HTML code character by character, identifying patterns and recognizing different types of tokens. The parsing algorithm analyzes the code, looking for specific characters and sequences that indicate the presence of tokens. For example, when encountering the<character, it marks the beginning of a tag, which signifies the presence of a token.
The HTML code is analyzed sequentially, and as the parser identifies tokens, it separates them from the surrounding code. This process continues until the entire HTML code has been tokenized, producing a sequence of tokens that represent the document’s structure and content. - Types of tokens:
The tokens generated during the tokenization process can be categorized into various types, each representing a distinct element or component of the HTML document. Some common types of tokens include:- Start tags: Start tags represent the opening of HTML elements and are denoted by the
<tag>syntax. For example,<p>represents a paragraph start tag. Start tags provide information about the element type and can include attributes. - End tags: End tags indicate the closing of HTML elements and are denoted by the
</tag>syntax. For instance,</p>represents the end tag for a paragraph element. End tags mirror the structure defined by start tags and contribute to the hierarchical organization of the document. - Self-closing tags: Certain HTML elements can be self-closing, meaning they do not require a separate closing tag. Self-closing tags are denoted by the
<tag/>syntax. For example,<br/>represents a line break tag. Self-closing tags are typically used for elements that don’t have content or require special handling. - Text: Text tokens represent the textual content within HTML elements. They include plain text, strings, or any character sequence that is not part of a tag or other special tokens. Text tokens contribute to the visible content of the HTML document.
- Comments: HTML comments are tokens used to add notes or annotations within the code. They are denoted by the
<!-- comment -->syntax. Comments serve as a way to provide additional information or instructions for developers and are not rendered as visible content. - DOCTYPE declaration: The DOCTYPE token represents the document type declaration and provides information about the version of HTML being used. It is denoted by a specific syntax at the beginning of the HTML document, such as
<!DOCTYPE html>. The DOCTYPE token ensures that the document is interpreted correctly by the browser or parser.
- Start tags: Start tags represent the opening of HTML elements and are denoted by the
By breaking the HTML code into tokens, the parser gains a granular understanding of the document’s structure and content. These tokens serve as the building blocks for further processing and analysis during the HTML parsing process. They form the basis for constructing the Document Object Model (DOM) tree, which represents the structured representation of the HTML document and allows for easy manipulation and traversal of its elements.
Tokenization Algorithm:
The tokenization algorithm is a crucial component of the HTML parsing process. It defines the rules and logic for identifying and handling different types of tokens during parsing. The algorithm follows a series of steps to analyze the HTML code character by character and determine the appropriate tokens. Let’s explore the tokenization algorithm in more detail:
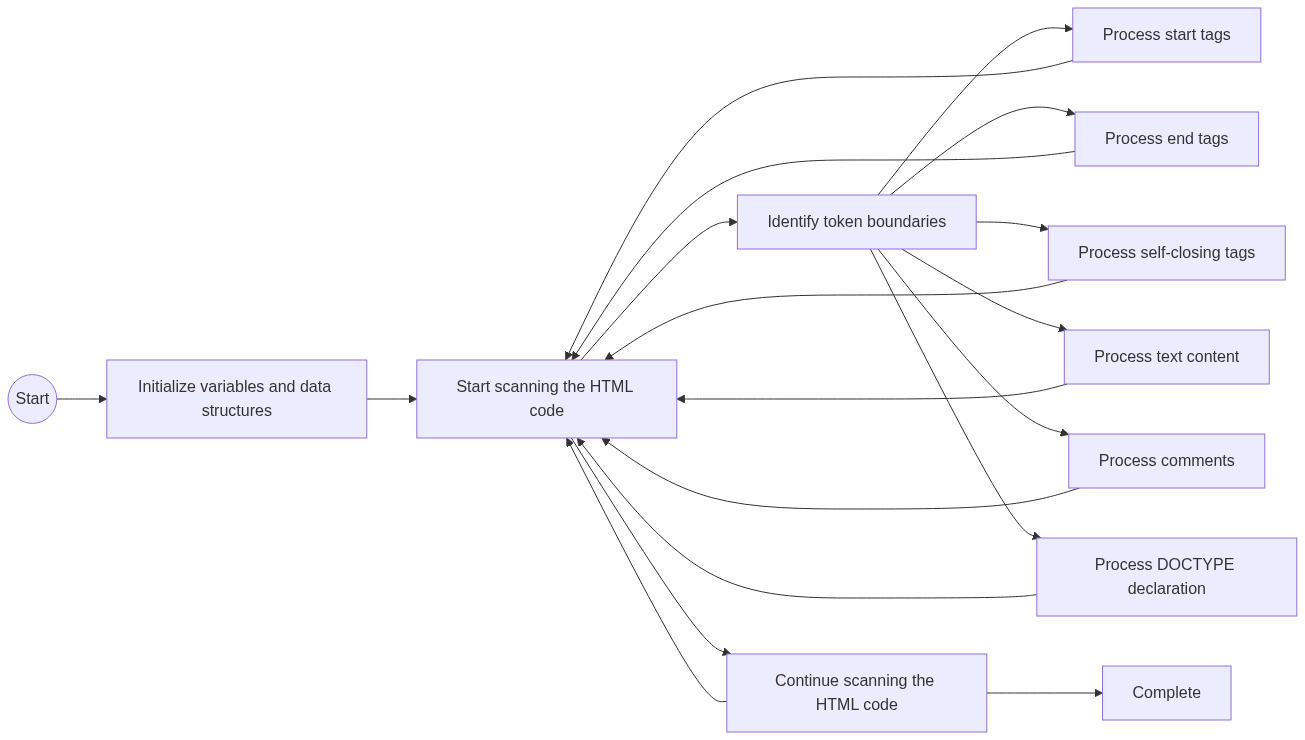
Detailed explanation of the algorithm:
- Initialize variables and data structures:
- In this step, the parser sets up the necessary variables and data structures to store the tokens generated during tokenization. This may involve initializing an array, linked list, or any other suitable data structure.
- Additionally, the algorithm initializes any flags or state variables required to keep track of the parsing process. These flags may be used to indicate specific conditions or control the flow of the algorithm.
- Start scanning the HTML code:
- The HTML code is scanned from the first character onward, starting the process of tokenization. The parser examines each character in the code, analyzing its role in the HTML structure.
- Identify token boundaries:
- In this step, the tokenization algorithm recognizes and differentiates between different types of tokens based on specific character patterns and sequences. The algorithm identifies token boundaries and determines the type of token to be generated.
- Process start tags:
- When the algorithm detects a
<character, it examines the following characters to determine if it represents a start tag. The tag name and any associated attributes are extracted from the HTML code. - A start tag token is generated, including the tag name and attributes, and stored in the token data structure.
- When the algorithm detects a
- Process end tags:
- When a
</sequence is encountered, the algorithm interprets the following characters as an end tag. The tag name is extracted from the code. - An end tag token is created, containing the tag name, and added to the token data structure.
- When a
- Process self-closing tags:
- When the algorithm encounters a self-closing tag, such as
<br/>, it generates a self-closing tag token. Any attributes associated with the self-closing tag are included in the token. - The self-closing tag token is added to the token data structure.
- When the algorithm encounters a self-closing tag, such as
- Process text content:
- Characters that are not part of a tag or special sequence are considered text content. The algorithm collects consecutive characters as a text token and stores it in the token data structure.
- The algorithm handles whitespace, line breaks, and other textual formatting within the text content as needed.
- Process comments:
- When the algorithm detects the
<!--sequence, it recognizes the following characters as a comment. The content of the comment is extracted. - A comment token is generated, containing the comment content, and added to the token data structure.
- When the algorithm detects the
- Process DOCTYPE declaration:
- The algorithm identifies and extracts the DOCTYPE declaration at the beginning of the HTML document. The DOCTYPE token provides information about the HTML version being used.
- A DOCTYPE token is created, including the relevant information, and stored in the token data structure.
- Continue scanning the HTML code:
- After processing each token, the algorithm continues scanning the HTML code, moving to the next character and evaluating it based on the tokenization rules.
- This process loops until the entire HTML code has been scanned and tokenized.
Once all the HTML code has been tokenized, the token data structure contains a sequence of tokens representing the structure and content of the HTML document. These tokens serve as the foundation for further steps in the HTML parsing process, such as tree construction and error handling.
Handling different types of tokens:
- As each token is identified and created, the algorithm can perform specific actions based on the token type.
- For example, start tag tokens may involve creating DOM elements, handling attributes, and establishing parent-child relationships.
- End tag tokens can trigger closing actions for corresponding elements in the DOM tree.
- Text tokens contribute to the visible content of the HTML document.
- Other tokens, such as self-closing tags, comments, and DOCTYPE declarations, can be processed or stored for later use.
By following the tokenization algorithm, the HTML parser systematically scans the HTML code, identifies tokens, and creates a sequence of tokens representing the document’s structure and content. These tokens serve as the foundation for the subsequent steps in the HTML parsing process, such as tree construction and error handling.
Tree Construction:
Tree construction is a vital step in the HTML parsing process. Once the HTML code has been tokenized and the tokens are available, the tree construction algorithm takes these tokens and builds a structured representation of the document known as the Document Object Model (DOM) tree. The DOM tree organizes the HTML elements in a hierarchical structure, allowing for easy manipulation, traversal, and rendering of the document.
Building the Document Object Model (DOM) tree:
The tree construction algorithm begins by creating the root of the DOM tree, which represents the entire HTML document. The root node serves as the starting point for constructing the tree structure. As the algorithm progresses, it adds child nodes to the tree to represent the nested HTML elements.
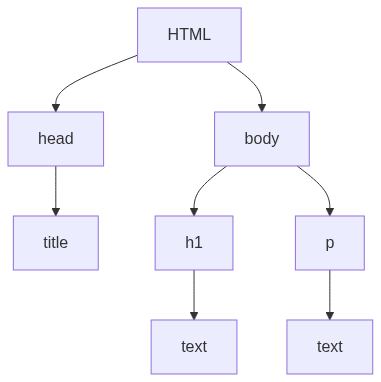
- Creating the root of the DOM tree:
At the beginning of the tree construction process, the algorithm creates the root node of the DOM tree. This root node represents the entire HTML document. It serves as the starting point for constructing the hierarchical structure of the DOM tree. - Creating element nodes:
As the algorithm iterates through the tokens generated during tokenization, it encounters start tags that represent HTML elements. For each start tag, the algorithm creates an element node in the DOM tree.
The element nodes capture the information about the HTML elements, including the element’s tag name, attributes, and any nested content. These element nodes become the building blocks of the DOM tree, forming the structure of the HTML document. - Establishing parent-child relationships:
To reflect the hierarchical structure of the HTML document, the algorithm establishes parent-child relationships between the element nodes. When a start tag is encountered, the corresponding element node becomes a child of the previously opened element. This creates a nested structure, where elements are organized hierarchically based on their containment.
For example, consider the HTML code <div><p>Hello, World!</p></div>. The algorithm creates an element node for the <div> element and another element node for the <p> element. The <p> element node becomes a child of the <div> element node, establishing a parent-child relationship.
- Handling sibling relationships:
In addition to parent-child relationships, the algorithm also handles sibling relationships between elements. When a new start tag is encountered that shares the same parent as the previously opened element, it becomes a sibling of the existing element.
For example, in the HTML code<div><p>Paragraph 1</p><p>Paragraph 2</p></div>, the algorithm creates two<p>element nodes. Both<p>elements have the same parent<div>and are siblings of each other.
By accurately establishing these parent-child and sibling relationships, the algorithm constructs the tree structure of the DOM. The resulting DOM tree reflects the nested organization of HTML elements, providing a hierarchical representation of the HTML document.
The DOM tree acts as a structured representation of the HTML document, enabling easy access, manipulation, and traversal of the HTML elements. It forms the foundation for various web technologies and JavaScript frameworks, allowing developers to interact with and modify the HTML content dynamically.
Creating the tree structure using tokens:
During tokenization, the HTML code is broken down into individual tokens, such as start tags, end tags, text content, comments, and more. These tokens capture different aspects of the HTML structure and content. The tree construction algorithm leverages these tokens to build the structure of the DOM tree.
The process of creating the tree structure using tokens involves iterating through the sequence of tokens and applying specific rules and logic to determine the placement of each token within the DOM tree. Here’s an overview of how this process unfolds:
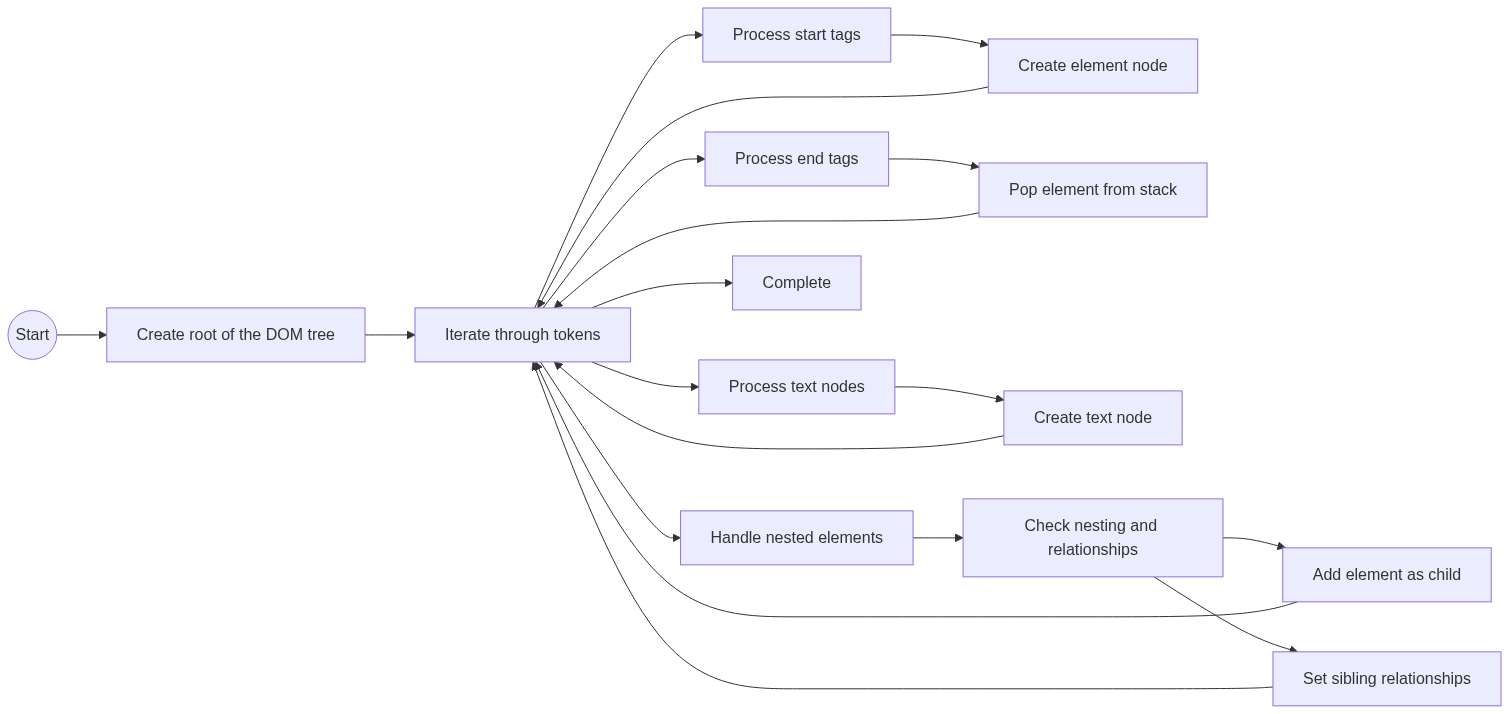
- Iterate through tokens:
- The algorithm starts by iterating through the tokens generated during tokenization. It examines each token in sequence, analyzing its type and content.
- Process start tags:
- When a start tag token is encountered, the algorithm creates a corresponding element node in the DOM tree.
- The algorithm extracts information from the start tag token, such as the tag name, attributes, and any associated values.
- The newly created element node becomes part of the DOM tree, positioned based on its parent-child relationships.
- Process end tags:
- When an end tag token is encountered, the algorithm identifies the corresponding open element in the DOM tree and completes its construction.
- The algorithm ensures that the end tag matches the most recently opened start tag, allowing for proper nesting of elements.
- The completed element node is ready for further manipulation and becomes part of the DOM tree structure.
- Process text content:
- Text tokens represent the content within HTML elements. The algorithm creates text nodes in the DOM tree to capture this textual content.
- The algorithm ensures that the text nodes are placed within the appropriate parent element node, respecting the nesting structure of the HTML.
- Process other tokens:
- The algorithm handles other types of tokens, such as comments, DOCTYPE declarations, and self-closing tags, as necessary.
- Depending on the specific requirements and rules of the HTML specification, the algorithm performs the appropriate actions to incorporate these tokens into the DOM tree.
By following this process, the algorithm traverses through the tokens and constructs the tree structure of the DOM, ensuring that each token is accurately positioned within the hierarchy of the HTML elements. The resulting DOM tree represents the organized structure of the HTML document, ready for further manipulation, rendering, and interaction.
The creation of the tree structure using tokens bridges the gap between the flat representation of tokens and the hierarchical representation of the DOM tree. It plays a vital role in transforming the HTML code into a structured representation that facilitates easy access, manipulation, and rendering of the HTML elements.
Handling nested elements and their relationships:
One essential aspect of tree construction is managing the nested structure of HTML elements. The algorithm ensures that child elements are appropriately nested within their parent elements. It establishes parent-child relationships between the nodes in the DOM tree based on the start and end tags of HTML elements.
It involves these following steps:
- Open elements stack:
- To handle nested elements, the algorithm maintains a stack known as the “open elements stack” or “element stack.”
- This stack keeps track of the currently open elements as the algorithm progresses through the tokenized HTML code.
- Each element node that has been opened but not yet closed is pushed onto the stack.
- Start tags and creating element nodes:
- When the algorithm encounters a start tag token, it creates a new element node for the corresponding HTML element.
- The newly created element node is then added to the DOM tree.
- Before adding the element node, the algorithm checks the open elements stack to determine the appropriate parent for the current element.
- The parent element is the most recently opened element on the stack.
- Establishing parent-child relationships:
- The algorithm establishes parent-child relationships between elements based on their nesting in the HTML code.
- The parent-child relationship is reflected in the DOM tree, with the parent element serving as the immediate ancestor of the child element.
- The algorithm ensures that each child element node is correctly nested within its parent element node.
- Closing elements and removing from the stack:
- When the algorithm encounters an end tag token, it indicates that the corresponding element has been closed.
- The algorithm checks the open elements stack to find the most recently opened element with a matching tag name.
- The algorithm removes elements from the stack until the element with the matching tag name is found and closed.
- Closing an element means it is considered complete and has been properly nested within its parent element.
- As elements are closed, they are removed from the stack, indicating that they have been fully processed.
By managing the open elements stack and establishing the correct parent-child relationships, the algorithm ensures that the nested structure of HTML elements is accurately represented in the DOM tree. This step is crucial for maintaining the integrity and hierarchy of the HTML document.
Once the tree construction phase is complete, the HTML parsing process moves on to handling errors, which involves dealing with malformed HTML and implementing error handling strategies. Let’s delve into the details of this crucial step.
Handling Errors:
HTML parsing is a complex process that involves interpreting and structuring HTML code according to specific rules and standards. However, HTML documents are often prone to errors due to various factors such as typos, missing tags, or incorrect nesting. Handling errors in HTML parsing is essential to ensure graceful recovery and provide developers with useful information about the encountered issues. Here’s a closer look at this aspect:
- Dealing with malformed HTML:
- Malformed HTML refers to code that does not adhere to the syntax and structure defined by the HTML specification.
- When encountering malformed HTML, the parsing algorithm employs error recovery strategies to continue parsing and recover from the error.
- The algorithm may attempt to infer missing elements, close mismatched tags, or adjust the DOM tree structure to accommodate the errors.
- The goal is to salvage as much of the valid content as possible and create a meaningful DOM tree representation.
- Error reporting and diagnostics:
- During the parsing process, the algorithm may collect information about encountered errors, warnings, or other issues.
- Error reporting mechanisms can include logging, console messages, or callbacks to notify developers about the encountered errors.
- These diagnostics help developers identify and rectify issues within the HTML code, ensuring better code quality and adherence to standards.
- Graceful degradation:
- HTML parsing algorithms often prioritize the recovery and rendering of content rather than terminating the process due to errors.
- By employing graceful degradation techniques, the algorithm aims to parse and render as much of the valid content as possible, even in the presence of errors.
- This approach ensures that users can still access and interact with the available content, even if some parts of the HTML document are problematic.
- Error-correcting parsers:
- Some parsing libraries or algorithms implement error-correcting techniques that can automatically fix minor errors or inconsistencies in the HTML code.
- Error-correcting parsers may adjust attribute values, close unclosed tags, or handle other common issues to improve the parseability of the code.
- These parsers strive to provide a more forgiving parsing experience and minimize the impact of errors on the resulting DOM tree.
Handling errors in HTML parsing plays a vital role in enabling developers to work with diverse HTML content and ensuring a robust user experience. It allows for graceful handling of malformed code, effective reporting of errors, and recovery strategies to salvage valid content. By addressing errors effectively, HTML parsers can parse and present HTML documents accurately, even in the presence of inconsistencies or issues within the code.
HTML Parsers:
After understanding of HTML parsing processes and its intricacies, let us now discuss the HTML parsers.
HTML parsers are essential tools that facilitate the interpretation and manipulation of HTML documents. They play a crucial role in tasks such as web scraping, data extraction, and document manipulation. HTML parsers analyze the structure of HTML code, identify elements and attributes, and create a structured representation, enabling developers to extract data and interact with the HTML content effectively.
Types:
HTML parsers come in various types, each catering to different needs and scenarios. In this section, we will explore the three main types of HTML parsers:
- HTML Parser Libraries:
HTML parser libraries are pre-built tools and APIs that simplify the process of parsing HTML code. These libraries offer a wide range of features and functionalities, making them popular choices among developers for HTML parsing tasks. Let’s explore HTML parser libraries in more detail:- Overview of popular HTML parsing libraries:
- HTML parser libraries such as BeautifulSoup, Jsoup, lxml, and HTML Agility Pack have gained popularity due to their ease of use, robustness, and community support.
- These libraries are available in various programming languages, including Python, Java, C#, and more. This makes them accessible to developers working with different technology stacks.
- The popularity of these libraries is also driven by their extensive documentation, tutorials, and active community forums, which provide support and resources for developers.
- Features and capabilities of each library:
- HTML parser libraries offer a range of features and capabilities that simplify the parsing process and enable efficient data extraction from HTML documents.
- Advanced selector querying: These libraries often provide powerful selector querying mechanisms, allowing developers to select and extract specific elements, attributes, or textual content based on CSS selectors, XPath expressions, or custom query syntax.
- HTML manipulation and traversal: HTML parser libraries offer methods and APIs for manipulating the structure and content of HTML documents. Developers can add, remove, modify, or rearrange elements, attributes, and text nodes in the parsed HTML.
- Support for different HTML versions: Libraries typically support parsing and handling of various HTML versions, including HTML5, XHTML, and legacy HTML standards. This ensures compatibility with different types of HTML documents.
- Error handling and robustness: HTML parser libraries often include error handling mechanisms to handle malformed or invalid HTML gracefully. They provide ways to handle and recover from parsing errors, ensuring more robust parsing of HTML code.
- Convenience methods for data extraction: These libraries offer convenient methods for extracting data from HTML documents. This includes extracting specific elements, attributes, or text content with ease, saving developers from manually traversing and manipulating the DOM tree.
- Performance considerations: HTML parser libraries are designed to be efficient and optimize parsing speed and memory usage. They employ various techniques, such as optimized data structures and parsing algorithms, to achieve faster parsing performance.
- Overview of popular HTML parsing libraries:
- Browser-Based Parsers:
Browser-based parsers are HTML parsers that are built into web browsers and are responsible for parsing and rendering web pages. These parsers play a critical role in transforming HTML code into a visual representation that users can interact with. Let’s delve into the details of browser-based parsers:- How web browsers parse HTML:
- Web browsers follow a specific set of steps to parse HTML and construct the Document Object Model (DOM) tree, which represents the structure of the HTML document.
- The parsing process begins with tokenization, where the HTML code is broken down into tokens. Tokens can represent elements, attributes, text content, comments, and other parts of the HTML code.
- As tokens are generated, they are processed and used to construct the DOM tree, which represents the hierarchical relationship between HTML elements.
- The DOM tree serves as the foundation for rendering the web page and allows web browsers to manipulate and interact with the HTML content.
- Rendering engines and their parsing processes:
- Different web browsers utilize distinct rendering engines, each with its own parsing process. Some popular rendering engines include Gecko (used in Firefox), WebKit (used in Chrome and Safari), and Blink (used in recent versions of Chrome and Opera).
- Each rendering engine implements its own algorithms and optimizations to parse HTML efficiently and handle the complexities of modern web standards.
- The parsing process involves not only tokenization and DOM tree construction but also handling CSS stylesheets, JavaScript code, and performing style computation and layout calculations.
- Rendering engines aim to optimize parsing performance, maintain standards compliance, and provide a smooth user experience by efficiently rendering web pages.
- How web browsers parse HTML:
- Custom HTML Parsers:
Custom HTML parsers refer to parsers that developers build from scratch to meet specific parsing requirements and scenarios where existing HTML parser libraries or browser-based parsers do not suffice. Building a custom HTML parser provides flexibility and control over the parsing process. Let’s explore custom HTML parsers in more detail:- Building a basic HTML parser from scratch:
- Building a custom HTML parser involves implementing the core components and steps involved in the parsing process.
- The first step is tokenization, where the HTML code is broken down into tokens representing different parts of the HTML structure.
- Tokens can include start tags, end tags, attributes, text content, comments, and other HTML elements.
- Once the tokenization is complete, the tokens are processed to construct the Document Object Model (DOM) tree, which represents the hierarchical structure of the HTML document.
- Building a basic HTML parser requires understanding the HTML specification, parsing algorithms, and data structures.
- Understanding the core components of a parser:
- Lexing/Tokenization: This step involves breaking down the HTML code into tokens. Lexical analysis techniques are used to identify different elements and components within the HTML code.
- Parsing Algorithms: Various parsing algorithms can be used to process the tokens and construct the DOM tree. Common algorithms include recursive descent parsing, bottom-up parsing (e.g., LALR), or customized algorithms based on specific requirements.
- Data Structures: Custom HTML parsers rely on appropriate data structures to represent and organize the parsed HTML. These structures may include linked lists, trees, stacks, or other data structures that facilitate efficient parsing and manipulation of HTML elements.
- Error Handling: Custom parsers should include error handling mechanisms to handle malformed or invalid HTML gracefully. Error recovery strategies can be implemented to handle syntax errors or unexpected input in a robust manner.
- Building a basic HTML parser from scratch:
Building a custom HTML parser requires a good understanding of the HTML specification, parsing techniques, and programming skills. It provides developers with full control over the parsing process, allowing them to tailor the parser to their specific needs. Custom parsers can be optimized for performance, handle specific HTML features, or integrate with existing codebases seamlessly.
However, it’s important to note that building a custom HTML parser from scratch is a complex task and should be considered when existing solutions do not fulfill the requirements or if there is a need for specialized parsing capabilities.
HTML vs. XHTML Parsing:
When it comes to parsing web documents, understanding the differences between HTML and XHTML parsing is essential, as each approach has its own syntax, structure, error handling, and implications for interoperability and accessibility. First let’s understand what is XHTML.
XHTML (Extensible HyperText Markup Language) is a markup language that is derived from HTML and follows the syntax and rules of XML (eXtensible Markup Language). XHTML combines the flexibility and ease of use of HTML with the strictness and well-formedness of XML. It allows developers to create web pages that adhere to XML standards while maintaining compatibility with HTML.
XHTML has several key characteristics:
- XML Syntax: XHTML uses the syntax rules of XML, which requires well-formed markup. This means that all tags must be properly nested and closed, attribute values must be quoted, and empty elements should be self-closed with a slash (“/”) at the end.
- Strict Document Structure: XHTML enforces a strict document structure by requiring the use of specific elements, such as <!DOCTYPE> declaration, <html>, <head>, and <body> tags. It also mandates the presence of essential elements like <title> and <meta> tags for better accessibility and search engine optimization.
- Case Sensitivity: XHTML is case-sensitive, meaning that tags and attribute names must be written in lowercase. This ensures consistency and adherence to XML standards.
- Improved Accessibility: XHTML promotes accessibility by encouraging the use of semantic markup. Semantic tags like <header>, <nav>, <section>, and <article> help in structuring content and provide meaningful information to assistive technologies and search engines.
- Better Interoperability: XHTML follows the strict rules of XML, making it more interoperable across different platforms and devices. It ensures consistent rendering and behavior across various web browsers and allows for easier integration with other XML-based technologies.
- Compatibility with XML Tools: Since XHTML is an XML-based language, it can be parsed and processed by various XML tools and technologies. This enables developers to leverage XML parsers, validators, and transformation tools to work with XHTML documents.
XHTML parsing follows the same principles and processes as HTML parsing. The key difference lies in the stricter syntax and structure enforced by XHTML. XHTML parsers adhere to XML parsing rules, ensuring that the XHTML document is well-formed, properly nested, and follows XML naming conventions.
Now, let’s see the differences between HTML and XHTML parsing:
| Parameters | HTML Parsing | XHTML Parsing |
|---|---|---|
| Syntax | HTML syntax is forgiving and allows for flexibility. | XHTML syntax follows strict XML rules and requires well-formed markup. |
| Case Sensitivity | HTML is case-insensitive for tags and attribute names. | XHTML is case-sensitive and requires lowercase tags and attribute names. |
| Document Structure | HTML has a loose document structure. | XHTML enforces a strict document structure with specific required elements. |
| Tag Omission | HTML allows omission of certain tags and attributes. | XHTML does not allow tag or attribute omission. |
| Error Handling | HTML parsers are lenient and can handle malformed code. | XHTML parsers strictly enforce well-formedness and report parsing errors. |
| Interoperability | HTML parsing can be browser-specific and non-uniform. | XHTML parsing is more consistent across browsers and XML-compatible tools. |
| Accessibility | HTML may lack semantic structure and accessibility. | XHTML encourages semantic markup and aids accessibility. |
HTML and XHTML parsing differ in terms of syntax rules, document structure, error handling, and interoperability. HTML offers more forgiving syntax and allows certain tag and attribute omissions. It is widely supported but can lead to inconsistent parsing behavior across browsers. On the other hand, XHTML follows strict XML rules, requiring well-formed markup and adherence to a predefined document structure. XHTML parsing ensures consistency, interoperability, and better error reporting.
XHTML’s stricter syntax and structure make it suitable for developers seeking a more standardized and disciplined approach to web development. It promotes accessibility through semantic markup and offers better compatibility with XML tools. However, it requires stricter adherence to rules and may require additional effort to ensure compliance.
Conclusion:
HTML parsing plays a crucial role in rendering web pages and extracting meaningful information from HTML documents. Throughout this article, we have explored the intricacies of HTML parsing, delving into the step-by-step process, the significance of tokenization, tree construction, error handling, and the various types of HTML parsers available.
Understanding HTML parsing empowers developers to build robust web applications, analyze web content, and automate data extraction. It forms the foundation for web scraping, data mining, and content manipulation. By comprehending the inner workings of HTML parsing, developers gain greater control over their code and can optimize performance and user experience.
In conclusion, mastering HTML parsing opens up a world of possibilities in web development, data extraction, and content manipulation. By understanding the parsing process, leveraging appropriate HTML parsing tools, and staying up to date with evolving standards, developers can navigate the complexities of HTML with confidence and create compelling web experiences.
Remember, HTML parsing is not just a technical process but a gateway to unlocking the vast potential of the web. Embrace the power of parsing, harness its capabilities, and embark on a journey of innovation and creativity in the ever-evolving realm of HTML.







