
Web scraping is a powerful technique used to extract data from websites. This method is widely used for various applications such as price monitoring, market research, and data analysis. Whether you’re tracking product prices, gathering competitor data, or extracting information for research, web scraping can be an invaluable tool.
Selenium is a popular tool for web scraping due to its ability to interact with web pages just like a human user. Unlike traditional scraping methods, Selenium can handle JavaScript-heavy sites and dynamic content, making it a versatile choice for developers.
In this guide, we’ll walk you through the process of setting up a web scraping environment using Selenium. We’ll provide step-by-step instructions and code examples to help you start scraping data efficiently and ethically. By the end of this tutorial, you’ll have a solid understanding of how to use Selenium for your web scraping projects.
What is Web Scraping?
Web scraping is the process of automatically extracting data from websites. This technique involves accessing web pages, retrieving their content, and processing that content to extract the desired information. Have you ever needed to gather data from multiple websites but found it too time-consuming to do manually? Web scraping can be the perfect solution.
The importance of web scraping cannot be overstated. Businesses use it for market research, price monitoring, and competitor analysis. Researchers use it to collect data for their studies. Journalists use it to gather information from multiple sources quickly. In essence, web scraping automates the repetitive task of data collection, making it faster and more efficient.
Imagine you need to monitor the prices of products across different e-commerce sites. Manually checking each site every day would be tedious and prone to errors. With web scraping, you can automate this task, ensuring you always have up-to-date information. This not only saves time but also provides accurate and reliable data.
How Web Scraping Works?
Web scraping involves three main steps: sending a request to a website, parsing the HTML content, and extracting the relevant data. Let’s explore each step in detail.
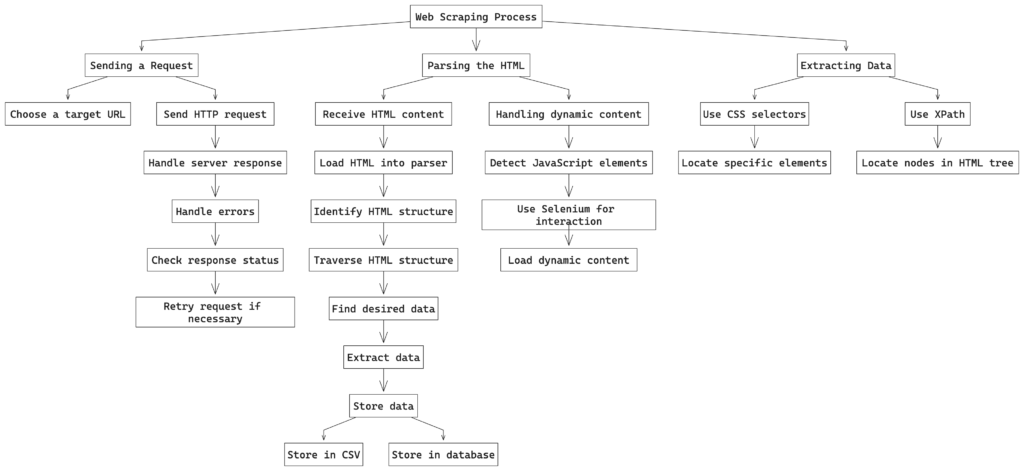
1. Sending a Request
The first step in web scraping is to send a request to the target website. This step is similar to typing a URL into your browser and hitting enter. The server responds by sending back the HTML content of the page. In Python, you can use libraries like requests to handle this step. However, when dealing with dynamic content generated by JavaScript, tools like Selenium become essential.
- Choose a Target URL: Identify the URL of the webpage you want to scrape.
- Send HTTP Request: Use an HTTP library like
requestsor Selenium to send a GET request to the server. - Handle Server Response: The server responds with the HTML content of the webpage. Ensure you handle any potential errors, such as server unavailability or incorrect URLs.
2. Parsing the HTML
Once you receive the HTML content, the next step is to parse it. HTML is structured in a tree-like format, with tags nested within other tags. To extract data, you need to navigate through this structure. Libraries like BeautifulSoup in Python make it easy to parse HTML and locate the elements you need.
- Receive HTML Content: Capture the HTML content returned by the server.
- Load HTML into Parser: Use BeautifulSoup to load the HTML content for parsing.
- Identify HTML Structure: Examine the HTML structure to understand where the required data resides.
- Traverse HTML Structure: Navigate through the HTML tree to find the desired data elements.
3. Extracting Data
After parsing the HTML, the final step is to extract the data. This involves identifying the specific elements that contain the information you want and pulling that data out. You can use CSS selectors or XPath to pinpoint the exact elements based on their attributes and hierarchy in the HTML structure.
- Use CSS Selectors: Identify elements using their CSS selectors. CSS selectors allow you to select elements based on their id, class, attributes, and hierarchy.
- Use XPath: XPath is another method to navigate through elements and attributes in an XML document. It provides a powerful way to locate nodes in the HTML tree.
- Locate Specific Elements: Use the selected method to locate the specific elements containing the data.
- Extract Data: Extract the text or attribute values from the located elements.
- Store Data: Save the extracted data into a structured format like a CSV file or a database.
But how does a web scraper know what to look for? This is where CSS selectors and XPath come into play. These tools allow you to specify exactly which elements to extract based on their attributes and hierarchy in the HTML structure.
Consider this: have you ever viewed the source code of a web page and felt overwhelmed by the sheer volume of HTML? Web scraping tools like BeautifulSoup simplify this by letting you pinpoint the exact elements you need, ignoring the rest.
Web scraping can also handle more complex tasks, like dealing with dynamic content and interacting with web pages. For example, many modern websites load data using JavaScript after the initial page load. Traditional scraping methods might miss this data, but Selenium can interact with the page just like a human would, ensuring you capture everything.
In summary, web scraping automates the process of data extraction from websites, turning what would be a time-consuming manual task into an efficient automated one. It opens up a world of possibilities for data collection, making it an invaluable tool for businesses, researchers, and developers alike. Have you thought about how much time you could save by automating your data collection tasks? Web scraping might just be the answer.
Why We Choose Selenium and BeautifulSoup for Our Project?
When embarking on a web scraping project, selecting the right tools is crucial for efficiency and effectiveness. For our project, we have chosen Selenium and BeautifulSoup. Let’s delve into why these tools stand out and how they compare to other popular web scraping tools.
Why Selenium?
Selenium is an open-source framework designed for automating web browsers. It excels in scenarios where interaction with dynamic content and JavaScript execution is required. Selenium directly controls a real web browser, making it capable of simulating user interactions, such as clicking buttons and filling out forms. This capability is particularly useful for scraping websites that rely heavily on JavaScript to load content dynamically.
Key Advantages of Selenium:
- Handles Dynamic Content: Selenium can wait for JavaScript to execute, ensuring that all dynamic content is fully loaded before extraction.
- Cross-Browser Support: Selenium supports multiple browsers (Chrome, Firefox, Safari, etc.), making it versatile for different environments.
- Extensive Language Support: Selenium offers bindings for various programming languages, including Python, Java, C#, and JavaScript, providing flexibility in development.
However, Selenium can be slower compared to other tools like Scrapy due to the overhead of controlling a browser. It is also more resource-intensive, which might not be suitable for large-scale scraping tasks.
Why BeautifulSoup?
BeautifulSoup is a Python library used for parsing HTML and XML documents. It provides simple methods and Pythonic idioms for navigating, searching, and modifying the parse tree, making it an excellent choice for handling HTML content.
Key Advantages of BeautifulSoup:
- Ease of Use: BeautifulSoup’s API is intuitive and easy to learn, making it accessible even for beginners.
- Integration with Requests: BeautifulSoup pairs well with the
requestslibrary for fetching static web pages, allowing for straightforward and efficient scraping. - Efficient Parsing: For projects where the content is mostly static, BeautifulSoup can quickly parse and extract data without the overhead of a browser.
However, BeautifulSoup alone cannot handle dynamic content rendered by JavaScript. It requires the initial HTML content, which means it can miss data loaded asynchronously after the page load.
Combining Selenium and BeautifulSoup
Combining Selenium and BeautifulSoup leverages the strengths of both tools, providing a comprehensive solution for web scraping. Selenium excels in handling dynamic content and simulating user interactions, making it ideal for websites that rely heavily on JavaScript to load content. Once Selenium has fully rendered the web page, BeautifulSoup steps in to parse and extract the required data efficiently.
This combination works well for several reasons. First, Selenium ensures that all dynamic content is loaded before any data extraction occurs. This guarantees that no part of the web page is missed, which is crucial for accurate data collection. BeautifulSoup then takes over to handle the parsing and extraction of data from the fully loaded HTML. Its simple and intuitive API allows for quick navigation through the HTML structure, making the extraction process seamless and efficient.
Additionally, this combination offers great flexibility. By using Selenium to handle user interactions and dynamic content, and BeautifulSoup to parse and extract data, we can scrape a wide range of websites. This includes everything from simple static pages to complex, interactive sites. This flexibility ensures that no matter the complexity of the web page, the scraping process remains robust and effective.
The integration of Selenium and BeautifulSoup provides a powerful, flexible, and efficient solution for web scraping, making it suitable for various projects and requirements.
Comparing with Other Tools
Other popular web scraping tools include Scrapy and Puppeteer. Scrapy is highly efficient for large-scale scraping tasks but struggles with JavaScript-heavy sites. Puppeteer, on the other hand, is fast and tightly integrated with Chromium, making it excellent for headless browsing and quick tasks but lacks the cross-browser flexibility of Selenium.
To visualize the performance and suitability of these tools, here is an interactive line chart comparing Selenium, BeautifulSoup, Scrapy, and Puppeteer on various parameters such as speed, ease of use, and handling of dynamic content.
This chart provides a visual representation of how each tool performs across different parameters, helping you make an informed decision based on your specific needs.
In conclusion, the combination of Selenium and BeautifulSoup offers a powerful and flexible solution for web scraping. Selenium’s ability to handle dynamic content and BeautifulSoup’s efficient parsing capabilities make them ideal partners for a wide range of web scraping tasks.
Have you thought about the specific needs of your scraping project? This combination might just be the perfect fit.
Setting Up the Environment
To start web scraping with Selenium, you need to set up your development environment properly. Follow these steps to get everything ready:
- Install Python and Pip:
- Ensure Python is installed on your system. You can check by running:
python --version - If Python is not installed, download and install it from python.org.
- Pip, the Python package manager, comes bundled with Python. Verify Pip installation with:
pip --version
- Ensure Python is installed on your system. You can check by running:
- Install Selenium and Webdriver Manager:
- Install Selenium and WebDriver Manager using Pip:
pip install selenium pip install webdriver-manager - Selenium allows you to automate browser interactions. WebDriver Manager simplifies the process of managing browser drivers, ensuring compatibility and easy setup.
- Install Selenium and WebDriver Manager using Pip:
- Setting Up ChromeDriver:
- Selenium requires a browser driver to interact with web browsers. WebDriver Manager handles this for you. It downloads and sets up the appropriate driver automatically.
- When you run your Selenium script, WebDriver Manager will take care of installing and managing ChromeDriver, so you don’t need to download it manually.
By following these steps, you will have a fully configured environment for web scraping with Selenium. This setup ensures you can run your scripts without issues and focus on extracting the data you need.
Writing the Scraping Script
In this section, we’ll write a complete web scraping script using Selenium. We’ll go through each part of the script step-by-step to ensure you understand how everything works.
1. Importing Necessary Libraries
First, we need to import the required libraries. These include Selenium for browser automation, BeautifulSoup for parsing HTML, and WebDriver Manager for handling the browser driver installation.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from webdriver_manager.chrome import ChromeDriverManager
from bs4 import BeautifulSoup2. Defining the Selector Function
We need a function to return CSS selectors based on the domain of the website. This function helps in identifying the elements we want to scrape.
def get_selectors(domain):
if 'amazon' in domain:
return {
'product_name': 'span#productTitle',
'product_price': 'span.a-price-whole',
'offer': 'div#dealBadge_feature_div'
}
elif 'flipkart' in domain:
return {
'product_name': 'span.B_NuCI',
'product_price': 'div._30jeq3._16Jk6d',
'offer': 'div._3Ay6Sb'
}
else:
raise ValueError(f"Selectors not defined for domain: {domain}")- Purpose: The
get_selectorsfunction provides specific CSS selectors for different domains, ensuring we can locate the desired elements accurately. - Domains Supported: Currently supports Amazon and Flipkart. You can add more domains as needed.
3. Creating the Scrape Function
This function handles the actual scraping process. It sets up the Selenium WebDriver, navigates to the target URL, and extracts the product data.
def scrape_product_data(url):
options = Options()
options.add_argument('--headless') # Run in headless mode to avoid opening the browser window
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
# Use webdriver_manager to handle driver installation
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=options)
driver.get(url)- Options Setup: The
Optionsobject configures the browser to run in headless mode (without opening a browser window), making the script more efficient. - WebDriver Manager: Automatically installs and manages the ChromeDriver.
Next, we extract the domain from the URL and fetch the appropriate CSS selectors.
try:
domain = driver.current_url.split('/')[2]
selectors = get_selectors(domain)
# Wait for elements to load
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, selectors['product_name']))
)
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, selectors['product_price']))
)
soup = BeautifulSoup(driver.page_source, 'html.parser')- Domain Extraction: Extracts the domain from the URL to determine which selectors to use.
- Waiting for Elements: Uses
WebDriverWaitto wait until the necessary elements are present on the page.
Now, we parse the page source with BeautifulSoup and extract the required data.
product_name = soup.select_one(selectors['product_name'])
product_price = soup.select_one(selectors['product_price'])
offer = soup.select_one(selectors['offer'])
product_data = {
'Product Name': product_name.get_text(strip=True) if product_name else 'N/A',
'Product Price': product_price.get_text(strip=True) if product_price else 'N/A',
'Offer Available': True if offer else False
}- Data Extraction: Uses BeautifulSoup to select elements based on the provided selectors.
- Handling Missing Data: If an element is not found, it assigns ‘N/A’ to that field.
Finally, we handle any potential errors and ensure the browser is closed properly.
except Exception as e:
print(f"Error: {e}")
product_data = {
'Product Name': 'N/A',
'Product Price': 'N/A',
'Offer Available': False
}
finally:
driver.quit()
return product_data- Error Handling: Catches any exceptions during the scraping process and assigns default values.
- Driver Cleanup: Ensures the WebDriver is closed properly, even if an error occurs.
4. Main Function Execution
To run the script, you need to provide a URL and call the scrape_product_data function. Here is how you can do it:
if __name__ == "__main__":
# URL to scrape
url = 'https://www.amazon.in/2022-Apple-MacBook-Laptop-chip/...'
product_data = scrape_product_data(url)
print(product_data)- Sample URL: Replace the URL with the one you want to scrape.
- Output: The script prints the extracted product data to the console.
By following these detailed steps, you can create a robust web scraping script using Selenium like below. This script is flexible and can be extended to support more websites and handle more complex scraping tasks.
Enhancing the Script
While our initial web scraping script using Selenium and BeautifulSoup is robust, there are several ways to enhance it further. These enhancements can improve the script’s efficiency, versatility, and error-handling capabilities, making it more suitable for a wide range of web scraping tasks.
Adding More Domains and Their Selectors
To make the script more versatile, you can extend the get_selectors function to include additional domains. This allows the script to scrape data from a broader range of websites without requiring significant modifications.
def get_selectors(domain):
if 'amazon' in domain:
return {
'product_name': 'span#productTitle',
'product_price': 'span.a-price-whole',
'offer': 'div#dealBadge_feature_div'
}
elif 'flipkart' in domain:
return {
'product_name': 'span.B_NuCI',
'product_price': 'div._30jeq3._16Jk6d',
'offer': 'div._3Ay6Sb'
}
elif 'ebay' in domain:
return {
'product_name': 'h1[itemprop="name"]',
'product_price': 'span#prcIsum',
'offer': 'div#viBadgeNew'
}
else:
raise ValueError(f"Selectors not defined for domain: {domain}")Handling Dynamic Content and JavaScript-Heavy Pages
Some websites use JavaScript extensively to load content dynamically. Enhancing the script to handle these cases ensures that you do not miss any important data. You can use Selenium to interact with these elements, such as clicking buttons or waiting for content to load.
def scrape_product_data(url):
options = Options()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=options)
driver.get(url)
try:
domain = driver.current_url.split('/')[2]
selectors = get_selectors(domain)
# Example: Click a button to load more content
try:
load_more_button = driver.find_element(By.CSS_SELECTOR, 'button.load-more')
load_more_button.click()
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, selectors['product_name']))
)
except Exception as e:
print(f"No load more button found: {e}")
# Wait for elements to load
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, selectors['product_name']))
)
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, selectors['product_price']))
)
soup = BeautifulSoup(driver.page_source, 'html.parser')
product_name = soup.select_one(selectors['product_name'])
product_price = soup.select_one(selectors['product_price'])
offer = soup.select_one(selectors['offer'])
product_data = {
'Product Name': product_name.get_text(strip=True) if product_name else 'N/A',
'Product Price': product_price.get_text(strip=True) if product_price else 'N/A',
'Offer Available': True if offer else False
}
except Exception as e:
print(f"Error: {e}")
product_data = {
'Product Name': 'N/A',
'Product Price': 'N/A',
'Offer Available': False
}
finally:
driver.quit()
return product_dataImplementing Error Handling and Logging
Adding robust error handling and logging mechanisms ensures that the script can gracefully handle unexpected situations and provides insights into any issues that arise during execution.
import logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
def scrape_product_data(url):
options = Options()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=options)
logging.info(f"Scraping URL: {url}")
driver.get(url)
try:
domain = driver.current_url.split('/')[2]
selectors = get_selectors(domain)
# Example: Click a button to load more content
try:
load_more_button = driver.find_element(By.CSS_SELECTOR, 'button.load-more')
load_more_button.click()
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, selectors['product_name']))
)
except Exception as e:
logging.warning(f"No load more button found: {e}")
# Wait for elements to load
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, selectors['product_name']))
)
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, selectors['product_price']))
)
soup = BeautifulSoup(driver.page_source, 'html.parser')
product_name = soup.select_one(selectors['product_name'])
product_price = soup.select_one(selectors['product_price'])
offer = soup.select_one(selectors['offer'])
product_data = {
'Product Name': product_name.get_text(strip=True) if product_name else 'N/A',
'Product Price': product_price.get_text(strip=True) if product_price else 'N/A',
'Offer Available': True if offer else False
}
logging.info(f"Scraped data: {product_data}")
except Exception as e:
logging.error(f"Error during scraping: {e}")
product_data = {
'Product Name': 'N/A',
'Product Price': 'N/A',
'Offer Available': False
}
finally:
driver.quit()
return product_dataOptimizing Performance
To optimize the script for better performance, consider using techniques such as parallel processing or minimizing unnecessary interactions with the web browser. For instance, you can scrape multiple URLs concurrently using Python’s concurrent.futures module.
from concurrent.futures import ThreadPoolExecutor
def scrape_multiple_urls(urls):
with ThreadPoolExecutor(max_workers=5) as executor:
results = executor.map(scrape_product_data, urls)
return list(results)
urls = [
'https://www.amazon.in/Redmi-Jade-Black-6GB-128GB/dp/B0C9JFWBH7',
'https://www.flipkart.com/apple-iphone-15-blue-128-gb/p/itmbf14ef54f645d',
# Add more URLs as needed
]
product_data_list = scrape_multiple_urls(urls)
for data in product_data_list:
print(data)By enhancing the script with these additional features, you can make it more versatile, robust, and efficient. These improvements ensure that the script can handle a wide range of scenarios and provide reliable data extraction, making it a powerful tool for any web scraping project.
Ethical Considerations and Legal Aspects
When engaging in web scraping, it is essential to consider the ethical and legal implications of your activities. While web scraping can be a powerful tool for data collection, it must be conducted responsibly and within the bounds of the law to avoid potential legal issues and respect the rights of website owners.
1. Respecting Website Terms of Service
Before scraping a website, always review its terms of service (ToS). Many websites explicitly prohibit scraping in their ToS, and violating these terms can lead to legal actions against you. If a website’s ToS forbids scraping, you should seek permission from the website owner or consider alternative data sources.
2. Avoiding Overloading Servers
Web scraping can place a significant load on a website’s servers, potentially disrupting the site’s normal operations. To avoid this, implement polite scraping practices, such as:
- Rate Limiting: Introduce delays between requests to avoid overwhelming the server.
- Respecting
robots.txt: Check the website’srobots.txtfile to see which parts of the site are allowed to be scraped and which are not. - Concurrency Limits: Limit the number of concurrent requests to the server to minimize the impact on its performance.
These practices help ensure that your scraping activities do not negatively affect the website’s functionality or user experience.
3. Handling Personal Data Responsibly
If your scraping activities involve collecting personal data, you must comply with data protection regulations such as the General Data Protection Regulation (GDPR) in Europe or the California Consumer Privacy Act (CCPA) in the United States. These regulations mandate how personal data should be collected, processed, and stored, emphasizing transparency and user consent. Ensure that you:
- Collect Data Transparently: Inform users about what data you are collecting and why.
- Obtain Consent: Obtain explicit consent from users before collecting their personal data.
- Secure Data: Implement strong security measures to protect the collected data from unauthorized access and breaches.
Failing to adhere to these regulations can result in severe legal consequences, including fines and sanctions.
4. Ethical Use of Scraped Data
Consider the ethical implications of how you use the data you collect. Ensure that the data is used in a manner that respects individuals’ privacy and does not cause harm. For instance, avoid using scraped data for:
- Spamming: Do not use contact information for unsolicited marketing.
- Discrimination: Avoid using data in ways that could discriminate against individuals or groups.
By using data ethically, you contribute to a fair and respectful digital environment.
5. Legal Precedents and Cases
Several legal cases have set precedents regarding web scraping. For instance, the case of LinkedIn vs. HiQ Labs highlighted the importance of understanding the legal boundaries of scraping publicly accessible data. LinkedIn argued that HiQ’s scraping of publicly available LinkedIn profiles violated the Computer Fraud and Abuse Act (CFAA). However, the court ruled that scraping publicly accessible data did not constitute unauthorized access under the CFAA.
This case underscores the complexity of web scraping law and the importance of staying informed about legal developments in this area. Always seek legal advice if you are uncertain about the legality of your web scraping activities.
Ethical and legal considerations are paramount when engaging in web scraping. By respecting website terms of service, avoiding overloading servers, handling personal data responsibly, and using scraped data ethically, you can ensure that your scraping activities are both effective and compliant with legal standards. Staying informed about legal precedents and seeking legal advice when necessary will help you navigate the complexities of web scraping law. Have you reviewed the ethical and legal aspects of your web scraping projects? Ensuring compliance can save you from potential legal troubles and contribute to a responsible data collection practice.
Conclusion
Web scraping, when executed correctly, is a powerful tool for data extraction. Utilizing Selenium and BeautifulSoup together combines the strengths of both tools, enabling efficient handling of dynamic content and effective HTML parsing. By setting up the environment, writing a robust script, and enhancing it with additional features, you can create a versatile and powerful web scraping solution.
Throughout this guide, we’ve emphasized the importance of understanding the ethical and legal aspects of web scraping. Respecting website terms of service, implementing polite scraping practices, and handling personal data responsibly are essential to maintaining ethical standards. Staying informed about legal precedents ensures that your web scraping activities remain compliant with the law.
By adhering to these principles and leveraging the capabilities of Selenium and BeautifulSoup, you can harness the full potential of web scraping. This approach not only saves time but also provides accurate and reliable data for a variety of applications, from market research to competitive analysis. Have you considered how ethical and responsible web scraping can benefit your projects? Embracing these best practices will ensure your scraping efforts are both effective and compliant.
In summary, ethical web scraping with Selenium and BeautifulSoup offers a comprehensive solution for data collection. By following the guidelines and best practices outlined in this guide, you can achieve efficient and responsible data extraction, contributing to a more informed and data-driven world.







