OpenAI introduces Sora, a groundbreaking text-to-video model that represents a significant leap forward in artificial intelligence. Sora can transform textual descriptions into dynamic, realistic videos. This advancement opens new possibilities for a wide range of applications, from content creation to educational tools. This article aims to provide a comprehensive understanding of the technical architecture and operational mechanics behind Sora. Targeted at developers and technical professionals, we will explore the intricacies of how Sora works, from its foundational technologies to the step-by-step process that turns text into video. Our focus is to demystify the complexities of Sora, presenting the information in a straightforward, accessible manner.
Understanding the Basics
Text-to-video AI models, such as Sora, convert written text into visual content by integrating several key technologies: natural language processing (NLP), computer vision, and generative algorithms. These technologies work in tandem to ensure the accurate and effective transformation of text into video.
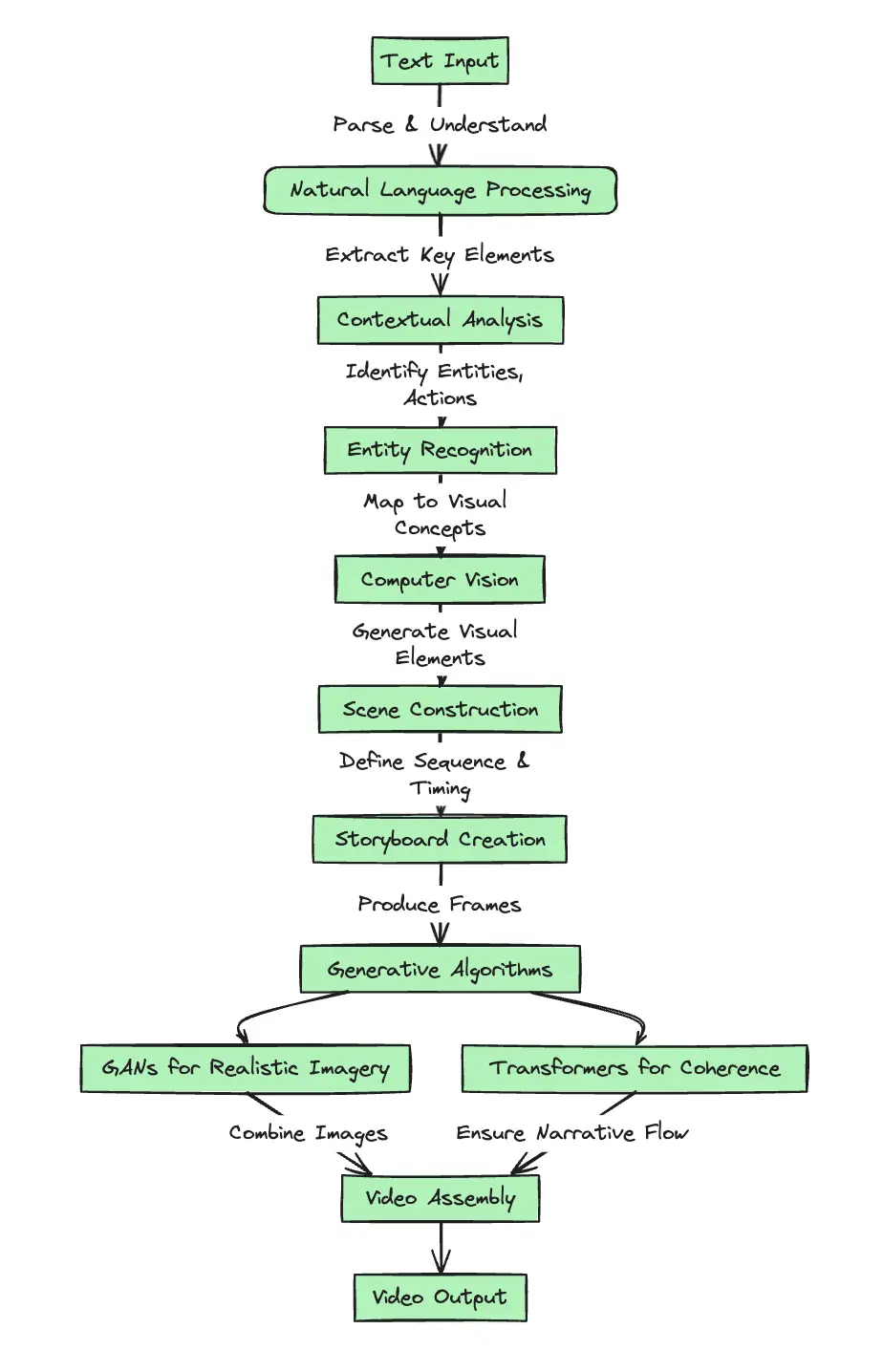
- Natural Language Processing (NLP) enables the model to parse and understand the text input(like a language model). This technology breaks down sentences to grasp the context, identify key entities, and extract the narrative elements that need visual representation.
- Computer Vision is responsible for the visual interpretation and generation of elements described in the text. It identifies and creates objects, environments, and actions, ensuring the video matches the textual description in detail and intent.
- Generative Algorithms, including Generative Adversarial Networks (GANs) and transformers, are crucial for producing the final video output. GANs generate realistic images and scenes by learning from vast datasets, while transformers maintain narrative coherence, ensuring the sequence of events in the video flows logically from the text.
These technologies collectively enable a text-to-video AI model to understand written descriptions, interpret them into visual elements, and generate cohesive, narrative-driven videos.
The diagram shows the sequential flow from receiving text input to generating a video output. It highlights the crucial roles played by NLP in understanding text, computer vision in visualizing the narrative, and generative algorithms in creating the final video, ensuring a comprehensive understanding of the basics behind text-to-video AI technology.
Also Read: How to create Local AI platform with Ollama and Open WebUI?
Technical Architecture of Sora
Having established a foundational understanding of the technologies that drive text-to-video models, we now turn our focus to the technical architecture of Sora. This section delves into the intricacies of Sora’s design, highlighting how it leverages advanced AI techniques to transform textual descriptions into vivid, coherent videos. We will explore the key components of Sora’s architecture, including data processing, model architecture, training methodologies, and performance optimization strategies. Through this examination, we aim to shed light on the sophisticated engineering that enables Sora to set new benchmarks in the field of AI-driven video generation. Let’s begin by exploring the first critical aspect of Sora’s technical architecture: data processing and input handling.
Data Processing and Input Handling
A critical initial step in Sora’s operation involves processing the textual data input by users and preparing it for the subsequent stages of video generation. This process ensures that the model not only understands the content of the text but also identifies the key elements that will guide the visual output. The following explains how Sora handles data processing and input.
- Text Input Analysis: Upon receiving a textual input, Sora first performs an in-depth analysis to parse the content. This analysis involves breaking down the text into manageable components, such as sentences and phrases, to better understand the narrative or description provided by the user.
- Contextual Understanding: The next step focuses on grasping the context behind the input text. Sora employs NLP techniques to interpret the semantics of the text, recognizing the overall theme, mood, and specific requests embedded within the input. This understanding is crucial for accurately reflecting the intended message in the video output.
- Key Element Extraction: With a clear grasp of the text’s context, Sora then extracts key elements such as characters, objects, actions, and settings. This extraction is essential for determining what visual elements need to be included in the generated video.
- Preparation for Visual Mapping: The extracted elements serve as a blueprint for the subsequent stages of video generation. Sora maps these elements to visual concepts that will be used to construct the scenes, ensuring that the video accurately represents the textual description.
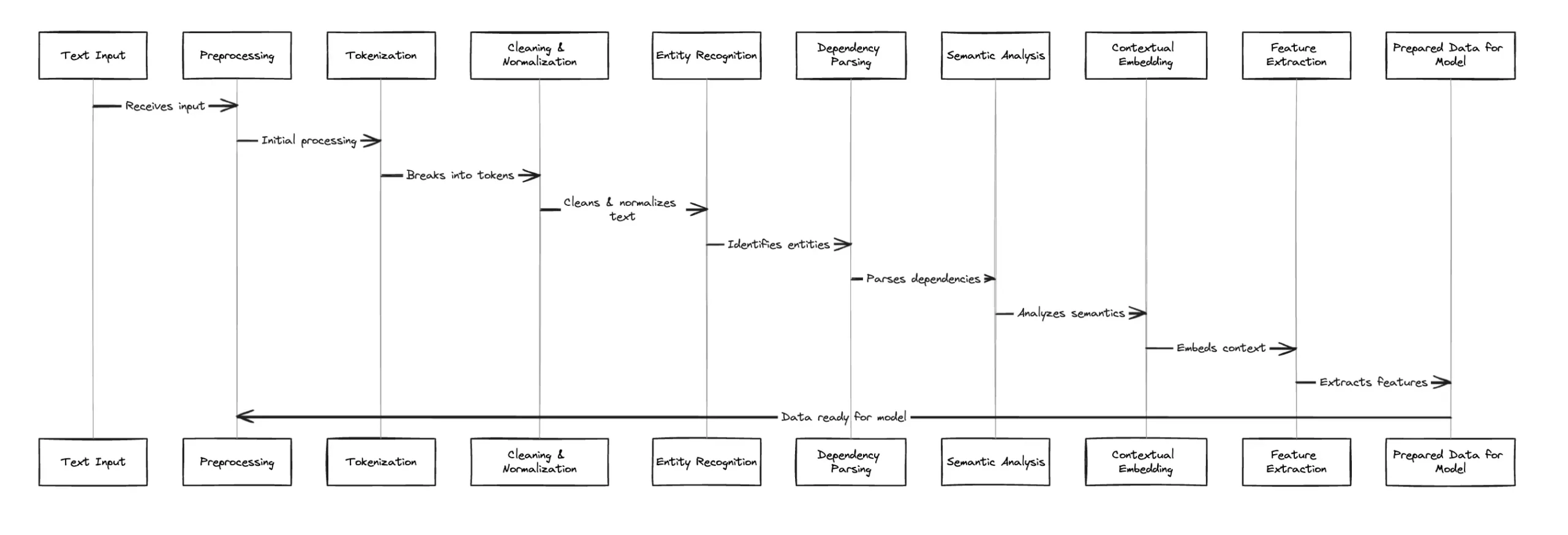
This diagram succinctly captures the initial phase of Sora’s technical architecture, emphasizing the importance of accurately processing and handling textual input. By meticulously analyzing and preparing the text, Sora lays the groundwork for generating videos that are not only visually compelling but also faithful to the user’s original narrative. This careful attention to detail in the early stages of data processing and input handling is what enables Sora to achieve remarkable levels of creativity and precision in video generation.
Also Read: How do Large Language Models work?
Model Architecture
Within Sora’s sophisticated framework, the model architecture employs a harmonious integration of various neural network models, each contributing uniquely to the video generation process. This section delves into the specifics of these neural networks, including Generative Adversarial Networks (GANs), Recurrent Neural Networks (RNNs), and Transformer models, followed by an explanation of how these components integrate for video synthesis.
Generative Adversarial Networks (GANs):
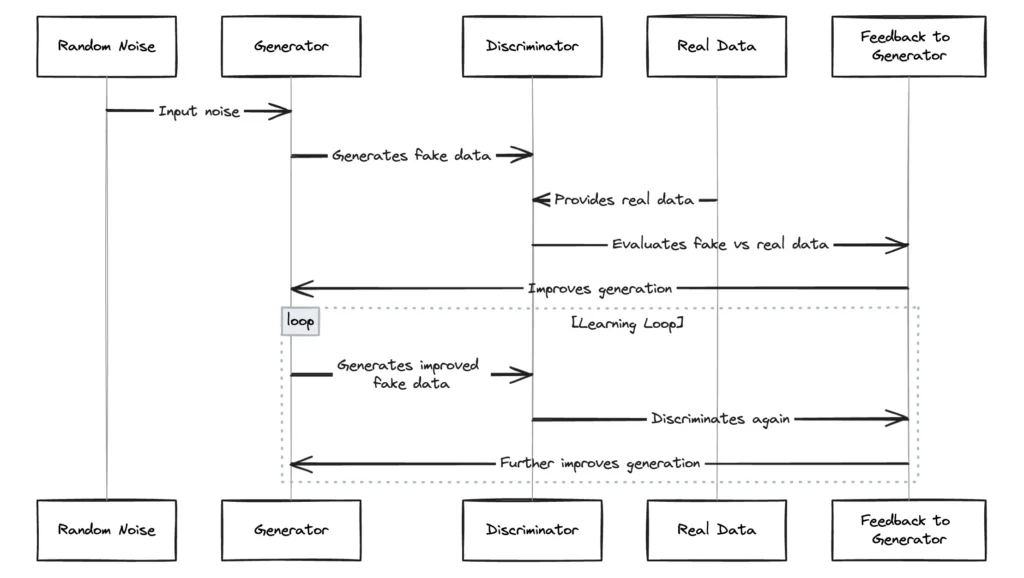
GANs are a class of machine learning frameworks designed for generative tasks. They consist of two main components: a generator and a discriminator. The generator’s role is to create data (in this case, video frames) that are indistinguishable from real data. The discriminator’s role is to distinguish between the generator’s output and actual data. This setup creates a competitive environment where the generator continuously improves its output to fool the discriminator, leading to highly realistic results. In the context of Sora:
- Generator: It synthesizes video frames from noise and guidance from the text-to-video interpretation models. The generator employs deep convolutional neural networks (CNNs) to produce images that capture the complexity and detail required for realistic videos.
- Discriminator: It evaluates video frames against a dataset of real videos to assess their authenticity. The discriminator also uses deep CNNs to analyze the frames’ quality, providing feedback to the generator for refinement.
Recurrent Neural Networks (RNNs):
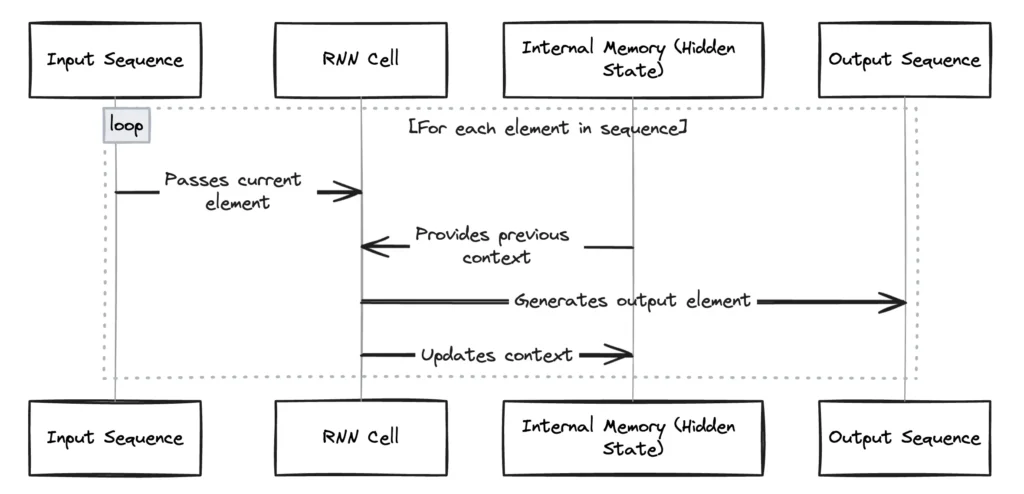
RNNs are designed to handle sequential data, making them ideal for tasks where the order of elements is crucial. Unlike traditional neural networks, RNNs can use their internal state (memory) to process sequences of inputs. This makes them particularly effective for understanding the temporal dynamics in videos, where each frame is dependent on its predecessors. For Sora, RNNs:
- Manage the narrative structure of the video, ensuring that each frame logically follows from the previous one in terms of storyline progression.
- Enable the model to maintain continuity and context throughout the video, contributing to a coherent narrative flow.
Transformer Models:
Transformers represent a significant advancement in handling sequence-to-sequence tasks, such as language translation, with greater efficiency than RNNs, especially for longer sequences. They rely on self-attention mechanisms to weigh the importance of each part of the input data relative to others. In Sora, Transformers:
- Analyze the textual input in-depth, understanding not only the basic narrative but also the nuances and subtleties contained within the text.
- Guide the generation process by mapping out a detailed storyboard that includes the key elements to be visualized, ensuring the video aligns closely with the text’s intent.
Integration of these components:
The integration of GANs, RNNs, and Transformer models within Sora’s architecture is a testament to the model’s sophisticated design. This integration occurs through a multi-stage process:
- Text Analysis: The process begins with Transformer models analyzing the textual input. These models excel at understanding the nuances of language, extracting key information, narrative structure, and contextual cues that will guide the video generation process.
- Storyboard Planning: Using the insights gained from the text analysis, a storyboard is planned out. This storyboard outlines the key scenes, actions, and transitions required to tell the story as described in the text, setting a blueprint for the video.
- Sequential Processing: RNNs take the storyboard and process it sequentially, ensuring that each scene logically follows from the last in terms of narrative progression. This step is crucial for maintaining the flow and coherence of the video narrative over time.
- Scene Generation: With a clear narrative structure in place, GANs generate the individual scenes. The generator within the GANs creates video frames based on the storyboard, while the discriminator ensures these frames are realistic and consistent with the video’s overall aesthetic.
- Integration and Refinement: Finally, the generated scenes are integrated into a cohesive video. This phase may involve additional refinement to ensure visual and narrative consistency across the video, polishing the final product for delivery.
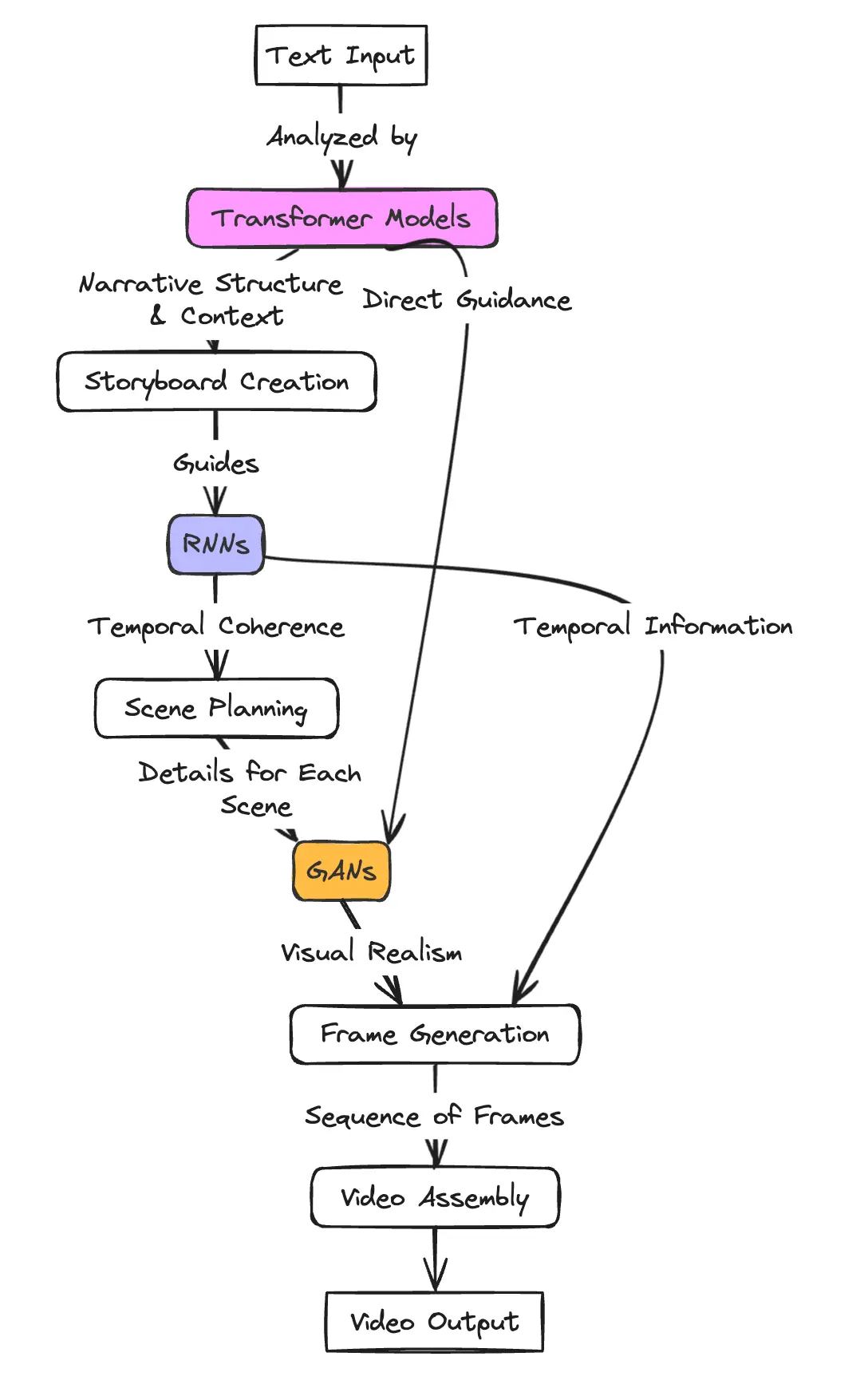
This architecture allows Sora to not only generate videos that are visually stunning but also ensure that they are coherent and true to the narrative intent of the input text, showcasing the model’s advanced capabilities in AI-driven video generation.
Training Data and Methodologies
The effectiveness of Sora in generating realistic and contextually accurate videos from textual descriptions is significantly influenced by its training data and methodologies. This section explores the types of datasets used for training Sora and delves into the detailed training process, including strategies like fine-tuning and transfer learning.
Types of Datasets Used for Training Sora:
Sora’s training involves a diverse range of datasets, each contributing to the model’s understanding of language, visual elements, and their interrelation. Examples of these datasets include:
- Natural Language Datasets: Collections of textual data that help the model learn language structures, grammar, and semantics. Examples include large corpora like Wikipedia, books, and web text, which offer a broad spectrum of language use and contexts.
- Visual Datasets: These datasets consist of images and videos annotated with descriptions. They enable Sora to learn the correlation between textual descriptions and visual elements. Examples include MS COCO (Microsoft Common Objects in Context) and the Visual Genome, which provide extensive visual annotations.
- Video Datasets: Specifically for understanding temporal dynamics and narrative flow in videos, datasets like Kinetics and Moments in Time are used. These datasets contain short video clips with annotations, helping the model learn how actions and scenes evolve.
Training Process:
The training of Sora involves several key methodologies designed to optimize its performance across different aspects of text-to-video generation.
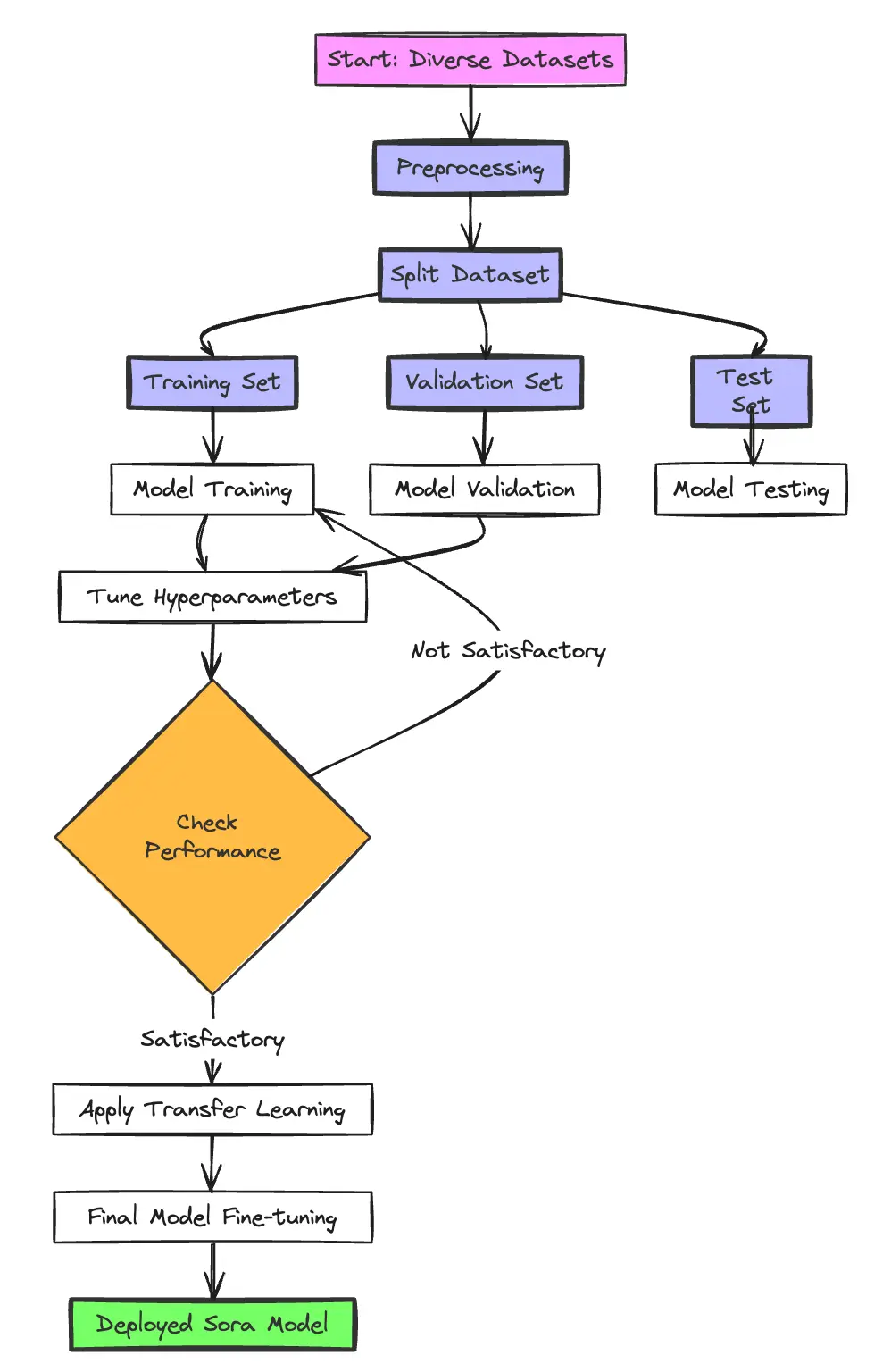
- Pre-training: Initially, separate components of Sora (such as Transformer models, RNNs, and GANs) are pre-trained on their respective datasets. For instance, Transformer models might be pre-trained on large text corpora to understand language, while GANs are pre-trained on visual datasets to learn image and video generation.
- Joint Training: After pretraining, the components are jointly trained on video datasets with associated textual descriptions. This phase allows Sora to refine its ability to match textual inputs with appropriate visual outputs, learning to generate coherent video sequences that align with the described scenes and actions.
- Fine-Tuning: Sora undergoes fine-tuning on specific datasets that might be closer to its intended application scenarios. This process adjusts the model’s parameters to improve performance on tasks that require more specialized knowledge, such as generating videos in particular genres or styles.
- Transfer Learning: Sora also employs transfer learning techniques, where knowledge gained while training on one task is applied to another. This is particularly useful for adapting the model to generate videos in domains or styles not extensively covered in the initial training data. By leveraging prelearned representations, Sora can more effectively generate videos in new contexts with less additional training.
The combination of these diverse datasets and sophisticated training methodologies ensures that Sora not only understands the complex interplay between text and video but also can adapt and generate high-quality videos across a wide range of inputs and requirements. This comprehensive training approach is critical for achieving the model’s advanced capabilities in text-to-video synthesis.
Performance Optimization
In the development of Sora, performance optimization plays a critical role in ensuring that the model not only generates high-quality videos but also operates efficiently. This subsection explores the techniques and strategies employed to optimize Sora’s performance, focusing on computational efficiency, output quality, and scalability.
- Computational Efficiency: To enhance computational efficiency, Sora incorporates several optimization techniques:
- Model Pruning: This technique reduces the complexity of the neural networks by removing neurons that contribute little to the output. Pruning helps in reducing the model size and speeds up computation without significantly affecting performance.
- Quantization: Quantization involves converting a model’s weights from floating-point to lower-precision formats, such as integers, which reduces the model’s memory footprint and speeds up inference times.
- Parallel Processing: Leveraging GPU acceleration and distributed computing, Sora processes multiple components of the video generation pipeline in parallel, significantly reducing processing times.
- Output Quality: Maintaining high output quality is paramount. To this end, Sora employs:
- Adaptive Learning Rates: By adjusting the learning rates dynamically, Sora ensures that the model training is efficient and effective, leading to higher-quality outputs.
- Regularization Techniques: Techniques such as dropout and batch normalization prevent overfitting and ensure that the model generalizes well to new, unseen inputs, thus maintaining the quality of the generated videos.
- Scalability: To address scalability, Sora uses:
- Modular Design: The architecture of Sora is designed to be modular, allowing for easy scaling of individual components based on the computational resources available or the specific requirements of a task.
- Dynamic Resource Allocation: Sora dynamically adjusts its use of computational resources based on the complexity of the input and the desired output quality. This allows for efficient use of resources, ensuring scalability across different operational scales.
- Efficiency and Quality Enhancement:
- Batch Processing: Where possible, Sora processes data in batches, allowing for more efficient use of computational resources by leveraging vectorized operations.
- Advanced Encoding Techniques: For video output, Sora uses advanced encoding techniques to compress video data without significant loss of quality, ensuring that the generated videos are not only high in quality but also manageable in size.
Through these optimization strategies, Sora achieves a balance between computational efficiency, output quality, and scalability, making it a powerful tool for generating realistic and engaging videos from textual descriptions. This careful attention to performance optimization ensures that Sora can meet the demands of diverse applications, from content creation to educational tools, without compromising on speed or quality.
How does Sora work?
After entering a prompt, Sora initiates a complex backend workflow to transform the text into a coherent and visually appealing video. This process leverages cutting-edge AI technologies and algorithms to interpret the prompt, generate relevant scenes, and compile these into a final video. The workflow ensures that user inputs are effectively translated into high-quality video content, tailored to the specified requirements. Here, we detail the backend operations from prompt reception to video generation, emphasizing the technology at each stage and how customization affects the outcome.
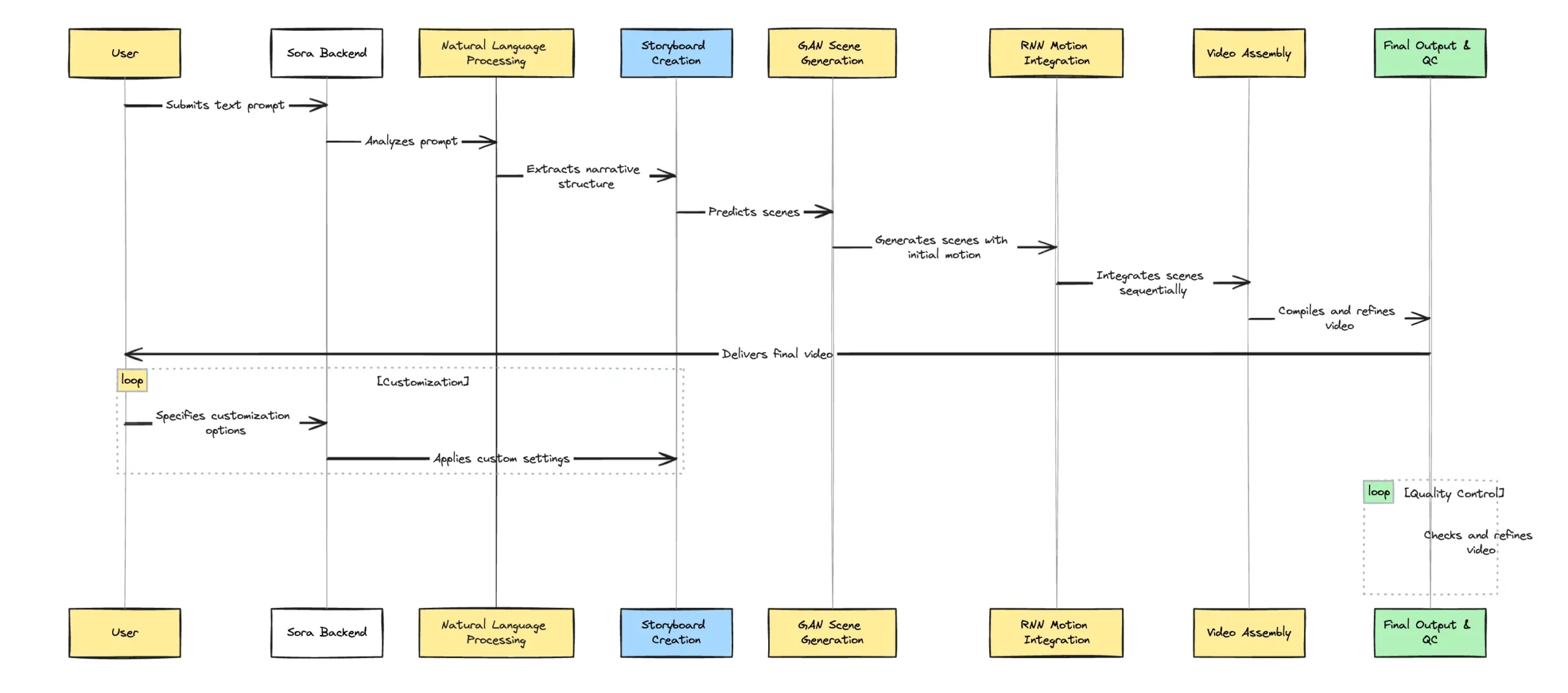
From Text to Video:
- Prompt Reception and Analysis: Upon receiving a text prompt, Sora first analyzes the input using natural language processing (NLP) technologies. This step involves understanding the context, extracting key information, and identifying the narrative structure of the prompt.
- Storyboard and Scene Prediction: Based on the analysis, Sora then creates a storyboard, outlining the sequence of scenes that will make up the video. This involves predicting the setting, characters, and actions that need to be visualized to match the narrative intent of the prompt.
- Scene Generation: With the storyboard as a guide, Sora proceeds to generate individual scenes. This process utilizes generative adversarial networks (GANs) to create realistic images and animations. Recurrent neural networks (RNNs) ensure that the scenes are generated in a sequence that maintains narrative coherence.
- Motion Generation and Integration: For each scene, motion is generated to animate characters and objects, bringing the story to life. This involves sophisticated algorithms that simulate realistic movements based on the actions described in the prompt.
- Video Assembly: The generated scenes, complete with motion, are then compiled into a continuous video. This step involves adjusting transitions between scenes for smoothness and ensuring that the video flows in a way that accurately represents the narrative.
Customization and User Input
- Influence of User Inputs: User inputs significantly influence the generation process. Customization options allow users to specify characters, settings, and even the style of the video, guiding Sora in creating a video that matches the user’s vision.
- Capabilities for Customization: Sora offers a range of customization options, from basic adjustments like video length and resolution to more detailed specifications such as character appearance and scene settings. This flexibility ensures that the videos are not unique but also closely aligned with user preferences.
Real-time Processing and Output
- Real-time Processing: Sora is designed to handle processing in real time, optimizing the workflow for speed without compromising on quality. This capability is crucial for applications requiring quick turnaround times, such as content creation for social media or marketing campaigns.
- Output Formats: The final video is rendered in popular formats, ensuring compatibility across a wide range of platforms and devices. Users can select the desired format and resolution based on their needs.
- Quality Control and Refinement: After the initial video generation, Sora implements quality control measures, reviewing the video for any inconsistencies or errors. If necessary, refinement processes are applied to enhance the visual quality, narrative coherence, and overall impact of the video.
Generated by OpenAI’s Sora
Through the integration of NLP, GANs, and RNNs, Sora efficiently translates textual descriptions into compelling video content, offering users unparalleled customization and real-time processing capabilities. This detailed process ensures that each video not only meets the high standards of quality and coherence but also aligns closely with user expectations, marking a new era in content creation powered by AI.
Current Limitations of Sora
Despite Sora’s advanced capabilities in generating realistic and coherent videos from text prompts, it faces certain limitations that are inherent to the current state of AI technology and its implementation. Understanding these limitations is crucial for setting realistic expectations and identifying areas for future development. The current limitations include:
- Complexity of Natural Language: While Sora is adept at parsing and understanding straightforward prompts, it may struggle with highly ambiguous or complex narratives. The nuances of language and storytelling can sometimes lead to discrepancies between the user’s intent and the generated video.
- Visual Realism: Although Sora employs advanced techniques like GANs for generating realistic scenes, there can be instances where the visuals do not perfectly align with real-world physics or the specific details of a narrative. Achieving absolute realism in every frame remains a challenge.
- Customization Depth: Sora offers a range of customization options, but the depth and granularity of these customizations are still evolving. Users may find limitations in precisely tailoring every aspect of the video to their specifications.
- Processing Time and Resources: High-quality video generation is resource-intensive and time-consuming. While Sora aims for efficiency, the processing time can vary significantly based on the complexity of the prompt and the length of the generated video.
- Generalization Across Domains: Sora’s performance is influenced by the diversity and breadth of its training data. While it excels in scenarios closely related to its training, it may not generalize as well to entirely new or niche domains.
- Ethical and Creative Considerations: As with any generative AI, there are concerns regarding copyright, authenticity, and ethical use. Ensuring that Sora’s generated content respects these boundaries is an ongoing effort.
These limitations underscore the importance of continuous research and development in AI, machine learning, and computational resources. Addressing these challenges will not only enhance Sora’s capabilities but also expand its applicability and reliability in generating video content across a wider array of contexts.
Conclusion
Sora, OpenAI’s innovative text-to-video model, represents a significant leap forward in the field of artificial intelligence, blending natural language processing, generative adversarial networks, and recurrent neural networks to transform textual prompts into vivid, dynamic videos. This technology opens new avenues for content creation, offering a powerful tool for professionals across various industries to realize their creative visions with unprecedented ease and speed.
While Sora’s capabilities are impressive, its current limitations—ranging from handling complex language nuances to achieving absolute visual realism—highlight the challenges that lie at the intersection of AI and creative content generation. These challenges not only underscore the complexity of replicating human creativity and understanding through AI but also mark areas ripe for further research and development. Enhancing Sora’s ability to parse more intricate narratives, improve visual accuracy, and offer deeper customization options will be crucial in bridging the gap between AI-generated content and human expectations.
From a constructive standpoint, addressing these limitations necessitates a multifaceted approach. Expanding the diversity and depth of training datasets can help improve generalization across domains and enhance the model’s understanding of complex narratives. Continuous optimization of the underlying algorithms and computational strategies will further refine Sora’s efficiency and output quality. Moreover, engaging with the broader ethical and creative implications of AI-generated content will ensure that advancements in technology like Sora align with societal values and norms.
In conclusion, Sora stands as a testament to the remarkable progress in AI, offering a glimpse into a future where machines can collaborate with humans to create diverse forms of visual content. The journey of refining Sora and similar technologies is ongoing, with each iteration promising not only more sophisticated outputs but also a deeper understanding of the creative capabilities of AI. As we look forward, it is the blend of technical innovation and thoughtful consideration of its implications that will shape the next frontier of content creation in the digital age.
People Also Ask for:
How does SORA differ from traditional diffusion models in video generation?
SORA combines a diffusion transformer (DiT) architecture with spacetime latent patches, enabling it to process video frames as spatiotemporal tokens. Unlike standard diffusion models that operate on pixels or fixed latent spaces, SORA’s patch-based approach allows for dynamic scaling and longer context retention.
What role does the “visual tokenizer” play in SORA’s workflow?
The visual tokenizer (likely a VQ-VAE or similar) compresses raw video frames into discrete latent representations. This reduces computational overhead and enables the transformer to process videos as sequences of patches—similar to how LLMs handle text tokens.
Why does SORA use a diffusion transformer instead of a pure autoregressive model?
Diffusion transformers offer better scalability for high-dimensional data (like video) and mitigate the compounding error problem of autoregressive models. The DiT architecture also allows for parallel training and efficient long-range dependency modeling.
How does SORA handle variable-length video generation?
By treating videos as spacetime patches, SORA can dynamically adjust the number of tokens based on duration and resolution. The transformer’s attention mechanism scales across these patches, enabling flexible generation without fixed frame limits.
What are the key challenges in SORA’s training pipeline?
1. Data diversity: Requires massive, high-quality video datasets with precise temporal alignment.
2. Compute cost: Training DiTs on video data demands exa-scale GPU/TPU resources.
3. Temporal coherence: Maintaining consistency across long sequences is non-trivial (addressed via recaptioning and causal attention).
Does SORA support multimodal inputs (e.g., text + image conditioning)?
Yes. SORA likely uses cross-modal embeddings (e.g., CLIP for text, ViT for images) to align prompts with latent patches. This enables hybrid conditioning, such as animating a static image via text instructions.
Are there open-source alternatives to SORA’s architecture?
Not yet, but projects like Stable Diffusion 3 (using DiTs) and Pika Labs (for video) hint at similar directions. SORA’s technical report suggests OpenAI hasn’t open-sourced the model weights.







