Cascading Style Sheets (CSS) play a fundamental role in shaping the visual appearance of websites and web applications. Understanding how CSS works behind the scenes is essential for developers who aim to create engaging and visually appealing user interfaces. One crucial aspect of CSS is parsing, which involves interpreting and processing CSS code to extract the styles that define the presentation of HTML elements.
In this in-depth blog, we will dive into the concept of CSS parsing and explore its significance in web development. We will also touch upon related topics such as painting and constructing the CSS Object Model (CSSOM). By the end of this journey, you will have a solid understanding of the parsing process and how it influences the rendering of web pages.
So, let’s start with the CSS parsing, its inner workings, and try to understand its impact on the overall web development workflow.
CSS Parsing:
CSS parsing is the vital initial step in the process of browser rendering and applying CSS styles to HTML elements. It involves analyzing and breaking down CSS code into a structured format that can be understood by the browser rendering engine. Let’s explore the purpose and process of CSS parsing in more detail.
CSS parsing refers to the parsing or interpretation of CSS code to extract the style information contained within it. The browser’s parsing engine reads the CSS code and converts it into a format that can be utilized during the rendering process. By understanding the structure and rules defined in the CSS code, the browser can determine how to visually present the corresponding HTML elements.
Purpose of CSS Parsing:
The main purpose of CSS parsing is to separate and extract the style declarations from the CSS code. These style declarations contain information such as font sizes, colors, margins, and positioning that define the visual appearance of HTML elements. Through parsing, the browser identifies and stores this style information to later apply it during the rendering process.
The primary purposes of CSS parsing are as follows:
- Syntax Validation:
CSS parsing ensures that the CSS code adheres to the defined syntax rules and structure. It verifies whether the code is written correctly, including the proper use of selectors, properties, values, and punctuation. Syntax validation helps identify and flag any errors or inconsistencies in the CSS code, allowing developers to rectify them and ensure proper rendering of styles. - Building the CSS Object Model (CSSOM):
CSS parsing is instrumental in constructing the CSS Object Model (CSSOM). The CSSOM represents the structured representation of the CSS code, allowing developers to programmatically access and manipulate CSS properties and values. It provides a way to interact with the stylesheets and apply dynamic changes to the presentation of web elements. - Style Resolution:
During parsing, CSS rules are matched with the corresponding HTML elements based on the selectors. The browser’s rendering engine utilizes the parsed CSS to determine which styles should be applied to each element. By accurately parsing and resolving the styles, CSS parsing ensures that the visual presentation of the web page aligns with the intended design. - Performance Optimization:
Efficient CSS parsing contributes to the overall performance of the web page. Parsing CSS code involves parsing and analyzing multiple rules, properties, and values. Optimized parsing algorithms and techniques help reduce parsing time, resulting in faster rendering of web pages and improved user experience. - Error Handling:
CSS parsing identifies and handles various types of errors that may occur in the CSS code. These errors could be syntax errors, such as missing semicolons or invalid property-value pairs. By detecting and reporting parsing errors, developers can debug and correct the CSS code, ensuring the proper application of styles.
Process of CSS parsing:
CSS parsing involves several key steps that collectively convert the CSS code into a format that can be utilized by the browser’s rendering engine. These steps include tokenization, lexical analysis, and syntax analysis.
- Tokenization:
The first step in CSS parsing is tokenization, where the CSS code is divided into tokens. Tokens represent individual units such as selectors, properties, and values. For example, in the CSS rule “h1 { color: red; }”, tokens would include “h1”, “{“, “color”, “:”, “red”, “;”, and “}”. - Lexical analysis:
After tokenization, lexical analysis assigns meaning to the tokens by categorizing them based on their role. It handles whitespace, comments, and special characters while identifying the different types of tokens. - Syntax analysis:
Syntax analysis is the process of determining the structure and validity of the CSS rules. It involves analyzing the relationships between tokens and building a parse tree, which represents the hierarchical structure of the CSS code.- Common challenges and errors during CSS parsing:
During CSS parsing, developers may encounter certain challenges and errors that can affect the correct interpretation of the CSS code. Two common issues include parsing errors and invalid CSS syntax.
- Common challenges and errors during CSS parsing:
- Parsing errors:
Parsing errors occur when the browser encounters unexpected or incorrect CSS code. These errors can lead to the misinterpretation of style rules, potentially resulting in unexpected visual output. Proper error handling and debugging techniques are essential to identify and resolve parsing errors effectively. - Invalid CSS syntax:
Invalid CSS syntax refers to code that does not conform to the CSS specifications. This can include misspelled properties, incorrect property-value pairs, or improper use of selectors. Browsers attempt to recover from invalid syntax by applying error-correction techniques, but it’s crucial to write valid CSS code to ensure consistent and intended rendering.
Understanding the process of CSS parsing and being aware of potential challenges and errors can greatly assist developers in creating well-formed CSS code that delivers the desired visual presentation on the web page.
CSS Parsing Steps:
Now that we have a basic understanding of CSS parsing, let’s explore the individual steps involved in this process and gain a deeper insight into how CSS code is parsed and interpreted by the browser’s rendering engine.
The following diagram illustrates the sequential steps involved in CSS parsing, showcasing the interconnected process of tokenization, lexical analysis, and syntax analysis.

Starting with the first step:
Tokenization:
Tokenization is the initial step in the CSS parsing process. It involves breaking down the CSS code into individual tokens, which are the building blocks of CSS syntax. Tokens represent distinct units such as selectors, properties, values, symbols, and keywords. By tokenizing the CSS code, the browser’s parsing engine can identify and process each element of the CSS rules.
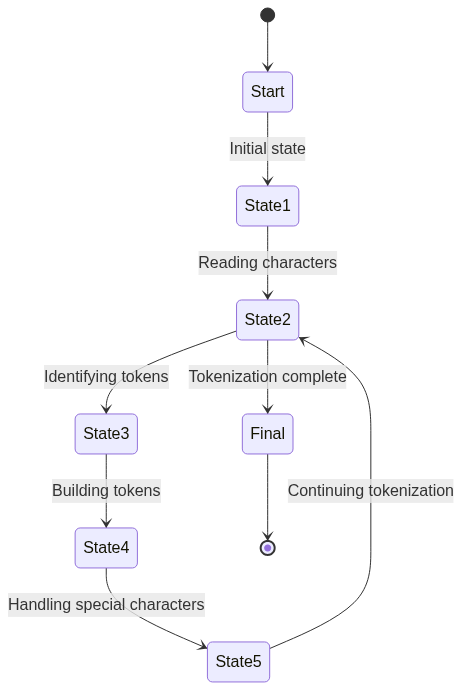
Here’s an explanation of the steps represented in the diagram for tokenization:
- Tokenization:
Tokenization is the process of breaking down the CSS code into individual tokens. Each token represents a distinct element of the CSS syntax. - Token 1: Selector:
The first token represents the selector, which in this case is “.example-class”. It identifies the HTML element or elements to which the styles will be applied. - Token 2: Identifier:
The second token represents the identifier, which is “example-class”. It corresponds to the class name that is being targeted. - Token 3: LeftCurlyBracket:
The third token is the left curly bracket ({), which indicates the start of the CSS rule block. - Token 4: Property:
The fourth token represents the property, such as “color”, “font-size”, or “margin-top”. It defines the specific CSS attribute that will be modified. - Token 5: Colon:
The fifth token is the colon (:), which separates the property from its corresponding value. - Token 6: Value:
The sixth token represents the value associated with a particular property. It specifies the desired styling for the selected element. - Token 7: Semicolon:
The seventh token is the semicolon (;), which marks the end of each property-value declaration within the CSS rule. - Token 8: Property (and subsequent tokens):
The eighth token and beyond follow the same pattern, representing additional properties, values, and semicolons within the CSS rule. - Token 16: RightCurlyBracket:
The sixteenth token is the right curly bracket (}), which signifies the end of the CSS rule block.
By tokenizing the CSS code, the browser’s parsing engine can identify and process each individual element, enabling further analysis and interpretation during the CSS parsing process.
Let’s tokenize our example CSS code to better understand how these steps works:
.example-class {
color: blue;
font-size: 16px;
margin-top: 20px;
}Tokenized CSS code:
Token: . Type: Selector
Token: example-class Type: Identifier
Token: { Type: LeftCurlyBracket
Token: color Type: Property
Token: : Type: Colon
Token: blue Type: Value
Token: ; Type: Semicolon
Token: font-size Type: Property
Token: : Type: Colon
Token: 16px Type: Value
Token: ; Type: Semicolon
Token: margin-top Type: Property
Token: : Type: Colon
Token: 20px Type: Value
Token: ; Type: Semicolon
Token: } Type: RightCurlyBracketIn the tokenized CSS code, each line represents a token, along with its associated type. For instance, the first token is a selector token represented by a period (.), and the second token is an identifier token representing the class name “example-class.” Similarly, property tokens are identified by their names, value tokens by their corresponding values, and symbols by their respective symbols.
Tokenization provides a structured representation of the CSS code, allowing subsequent parsing steps to analyze and interpret the individual elements accurately.
Lexical Analysis:
Lexical Analysis is the second step in the CSS parsing process. It involves breaking down the tokens generated during tokenization into meaningful units and handling whitespace, comments, and special characters appropriately.
- Breaking down tokens into meaningful units:
During Lexical Analysis, the tokens obtained from tokenization are further processed and categorized into meaningful units. This step involves identifying the purpose and role of each token in the CSS code. For example, tokens such as selectors, properties, values, symbols, and keywords are recognized and categorized based on their respective functions within CSS syntax. Breaking down tokens into meaningful units provides a structured representation of the CSS code, allowing for better analysis and interpretation in subsequent parsing steps. - Handling whitespace, comments, and special characters:
During the Lexical Analysis step, whitespace, comments, and special characters are handled appropriately to ensure the accurate interpretation of the CSS code. Let’s delve into how this step handles these elements:- Whitespace Handling: Whitespace, such as spaces, tabs, and line breaks, is generally insignificant in CSS and does not impact the interpretation of the code. Therefore, during Lexical Analysis, whitespace is typically ignored or skipped. It does not contribute to the structure or meaning of the CSS rules and is not considered during further parsing.
- Comment Handling: CSS supports two types of comments: single-line comments (//) and multi-line comments (/* */). Comments are non-significant elements in CSS that provide annotations or explanations within the code. During Lexical Analysis, comments are treated as white space and are often excluded from further processing. They are simply ignored and do not affect the interpretation of the CSS rules.
- Special Character Handling: Special characters in CSS, such as braces ({ }), colons (:), semicolons (;), and other punctuation marks, play crucial roles in defining the structure and syntax of the CSS rules. During Lexical Analysis, these special characters are recognized and handled appropriately. They are used to identify the start and end of selector blocks, separate properties from their values, and mark the termination of property-value pairs. Special character handling ensures the correct interpretation and parsing of the CSS rules.
By performing Lexical Analysis, the CSS parser ensures that tokens are properly categorized, whitespace is appropriately handled, and comments and special characters are treated as expected. This step sets the stage for subsequent analysis and interpretation of the CSS rules during the parsing process.
Syntax Analysis:
Syntax Analysis, also known as parsing, is a critical step in the CSS parsing process. It involves analyzing the structure and grammar of the CSS code to ensure that it conforms to the defined syntax rules. Syntax Analysis checks the arrangement and relationship of tokens to build a parse tree, representing the hierarchical structure of the CSS code.
During Syntax Analysis, the following tasks are performed:
- Arranging Tokens: Syntax Analysis arranges the tokens generated during tokenization into a meaningful order based on the rules of CSS syntax. This step considers the sequence and placement of tokens to determine the structure of CSS rules, properties, values, and other elements.
- Building the Parse Tree: The parse tree represents the hierarchical structure of the CSS code. Syntax Analysis constructs the parse tree by organizing tokens into nodes and defining the relationships between them. For example, the parse tree may have nodes for selectors, properties, values, and declarations, with parent-child relationships that reflect their hierarchy in the CSS code.
- Checking Syntax Rules: Syntax Analysis verifies that the CSS code follows the defined syntax rules. It checks for correct usage of selectors, proper placement of colons and semicolons, valid property-value pairs, and adherence to other syntactic rules. If any syntax errors are detected, appropriate error handling mechanisms are applied to ensure that the parsing process can recover or provide meaningful error messages.
- Detecting Common Syntax Errors: Syntax Analysis identifies and flags common syntax errors that developers may make in the CSS code. Examples of such errors include missing or mismatched curly brackets, improperly nested selectors, invalid property names or values, or incomplete declarations. Detecting these errors helps developers troubleshoot and correct their CSS code effectively.
Now, let’s perform the Syntax Analysis on our example CSS code:
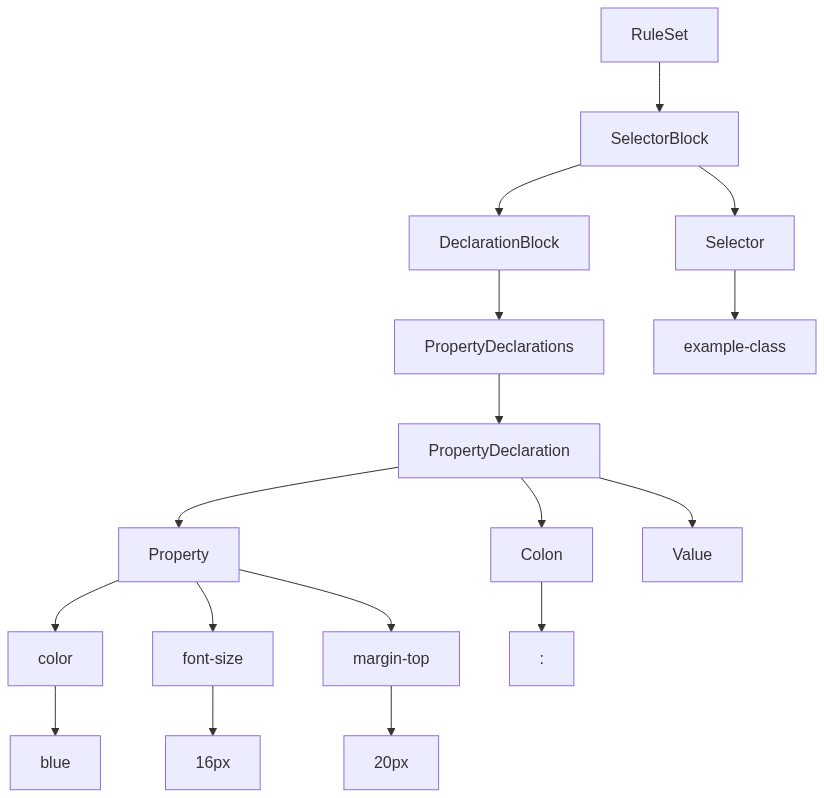
In the example, the Syntax Analysis produces a parse tree that represents the hierarchical structure of the CSS code. The parse tree consists of nodes for the RuleSet, SelectorBlock, Selector, DeclarationBlock, PropertyDeclarations, PropertyDeclaration, Property, Colon, and Value. The parent-child relationships between these nodes reflect their respective positions in the CSS code.
CSS Parsing Algorithm:
Now that we have a clear understanding of the individual steps involved in CSS parsing, let’s explore the CSS parsing algorithm, which encompasses the main logic behind the parsing process and guides how CSS rules are interpreted and applied.
The CSS parsing algorithm defines the systematic process by which CSS rules are parsed, evaluated, and applied to the HTML elements within a web page. It outlines the main steps involved in interpreting CSS code and determining the final styles that should be applied to each element.
The CSS parsing algorithm can be summarized as follows:
- Rule selection and matching:
The first step of the CSS parsing algorithm is rule selection and matching. This process involves selecting CSS rules and determining whether they match the corresponding HTML elements in the document tree. Let’s delve into the details of this step:- Selector Evaluation: The algorithm evaluates the selectors within each CSS rule to identify the elements they target. Selectors can be based on various criteria such as element types, classes, IDs, attributes, pseudo-classes, or combinations of these. The specificity of selectors is also considered, with more specific selectors taking precedence over less specific ones.
- Selector Matching: Once the selectors are evaluated, the algorithm matches them against the HTML elements in the document tree. It checks if the selector conditions are satisfied by any elements in the tree. If a selector matches an element, the associated CSS rule is considered a potential candidate for applying styles to that element.
- Rule Order: The algorithm takes into account the order of the CSS rules when multiple rules match the same element. Rules specified later in the stylesheet have higher precedence than earlier rules. This ensures that the most recently defined rules are applied to elements that match multiple selectors.
- Rule Specificity: The specificity of selectors plays a vital role in determining which rules take precedence over others. The algorithm assigns specificity values to selectors based on the types of selectors used, such as element selectors, class selectors, ID selectors, or inline styles. The selector with the highest specificity is chosen when multiple rules match the same element.
- Importance of Declarations: Declarations with the
!importantkeyword have the highest precedence in rule selection and matching. When conflicting rules have declarations marked as!important, those declarations will override any other conflicting styles. - Pseudo-classes and Pseudo-elements: The algorithm handles pseudo-classes and pseudo-elements during selector evaluation and matching. Pseudo-classes are used to style elements based on their states or certain conditions, such as
:hover,:active, or:nth-child(). Pseudo-elements, on the other hand, target specific parts of an element, such as::beforeor::after.
- Style inheritance and cascading:
The second step of the CSS parsing algorithm is style inheritance and cascading. This step determines how styles are inherited from parent elements and how conflicting styles are resolved through the cascade. Let’s explore the details of this step:- Inheritance of Styles: In CSS, some properties are inherited by default from parent elements to their children. During style inheritance, the algorithm propagates styles from parent elements to their descendants unless explicitly overridden. Inherited properties include font-related properties, text color, line height, and more. Inherited styles create a consistent visual theme throughout the document.
- Cascade Order: The CSS cascade is the process of resolving conflicts when multiple rules target the same element. The algorithm follows a specific order of precedence known as the cascade order. It considers the specificity of selectors, the order of rules, and the importance of declarations to determine which styles take precedence over others.
- Specificity Calculation: Specificity determines the weight or priority of a selector. It is calculated based on the types of selectors used, such as element selectors, class selectors, ID selectors, or inline styles. The algorithm assigns specificity values to each selector and compares them to resolve conflicts. Selectors with higher specificity override those with lower specificity.
- Importance of Declarations: Declarations marked with the
!importantkeyword have the highest precedence during style inheritance and cascading. When conflicts occur, declarations with!importantoverride any other conflicting styles, regardless of selector specificity. However, it is generally recommended to use!importantsparingly to avoid specificity wars. - Declaration Ordering: When selectors have the same specificity and there are no
!importantdeclarations, the algorithm follows the order of declarations within a rule. Declarations defined later in a rule take precedence over earlier declarations. This allows developers to override or modify styles by placing more specific or targeted declarations later in the rule. - Origin of Styles: The algorithm takes into account the origin of styles when resolving conflicts. Styles can originate from multiple sources, such as user-defined stylesheets, author stylesheets, inline styles, or browser defaults. Styles from external stylesheets typically have lower precedence than inline styles or styles defined within the HTML document.
- Calculating Computed Styles: After resolving conflicts, the algorithm calculates the computed styles for each element. Computed styles represent the final values of CSS properties that will be applied to the elements during rendering. The computed styles consider the inherited styles, cascaded styles, and the specificity of the matching rules.
- Calculating final property values:
The third and final step of the CSS parsing algorithm is calculating the final property values for each CSS property specified within the matched rules. This step involves resolving relative units, performing calculations based on inherited or cascaded values, and handling conflicts or overrides. Let’s delve into the details of this step:- Resolving Relative Units: The algorithm handles relative units, such as percentages (%), ems (em), or roots (rem), by resolving them to their corresponding absolute values. Relative units depend on other factors, such as the size of parent elements or the root element’s font size. The algorithm calculates and converts relative units to absolute values based on these contextual factors.
- Handling Inheritance: During the calculation process, the algorithm takes into account inherited values from parent elements. If a property is not explicitly defined for an element, the algorithm retrieves the computed value from the nearest parent element that has the property defined. Inheritance ensures consistency and propagates styles throughout the document tree.
- Cascaded Value Calculation: The algorithm calculates the cascaded value of each property based on the cascade order and specificity. It considers the value specified in the matching CSS rule and takes into account any overrides or conflicting styles from higher-specificity selectors. The cascaded value represents the result of the cascade resolution for each property.
- Resolving Conflicts and Overrides: Conflicts can occur when multiple rules target the same element with different values for the same property. The algorithm resolves these conflicts by applying the cascade rules, selector specificity, and the order of declarations. Conflicts may also arise when using shorthand properties, and the algorithm resolves these conflicts by following the specific rules for each shorthand property.
- Final Computed Value Determination: Once conflicts are resolved, the algorithm determines the final computed value for each property. It takes into account the cascaded value, any inheritances, calculations based on relative units, and any other factors affecting the property. The final computed value represents the value that will be used for rendering and displaying the element on the web page.
The CSS parsing algorithm provides a systematic approach to handle the complexities of CSS code, ensuring accurate interpretation and application of styles to HTML elements. It follows a rule-based evaluation and cascading mechanism, resulting in the determination of the final computed styles for each element.
Painting:
Painting is a crucial step in the rendering process of web pages that involves applying visual styles to the elements on the screen. Once the CSS parsing and layout calculations are completed, the browser proceeds to the painting step to render the final visual representation of the web page. Let’s explore how this step called Painting happens after parsing.
Here you can see a detailed class diagram for this step. You can
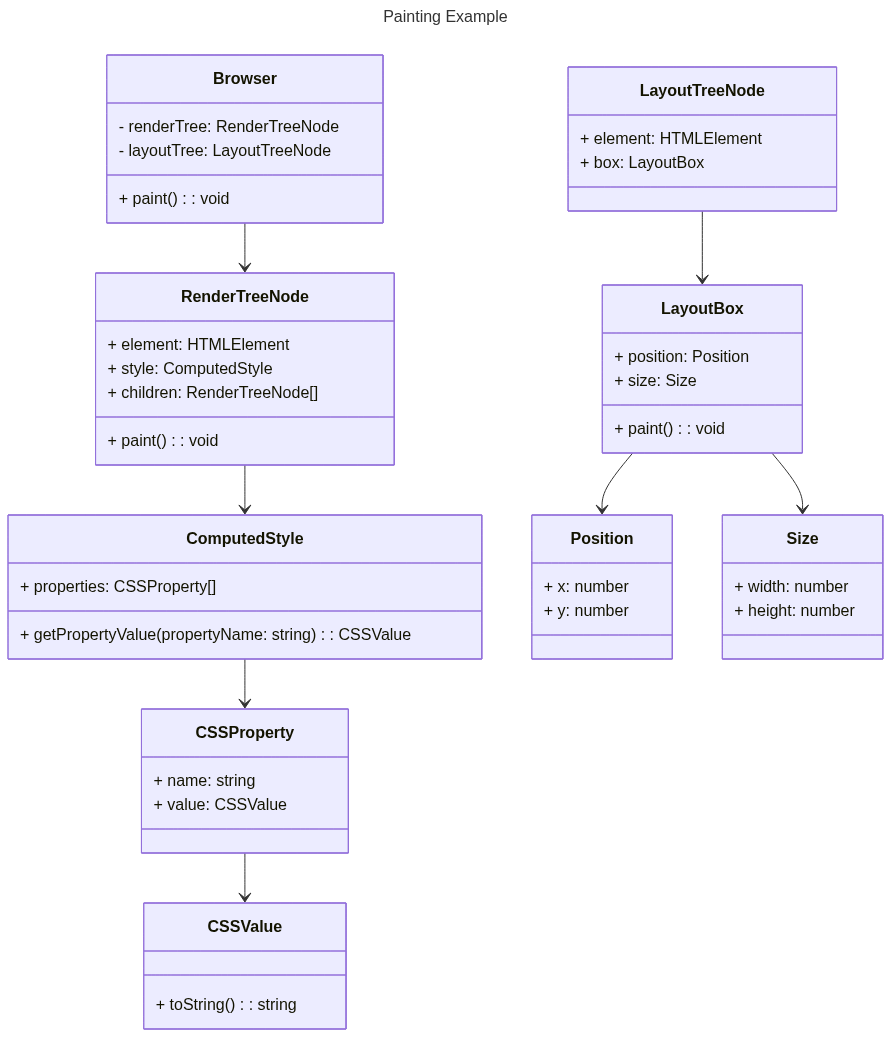
- Painting Process: During the painting step, the browser traverses the render tree, which is a tree-like structure representing the visual elements of the web page. It determines the visual styles for each element, such as colors, backgrounds, borders, shadows, and text styles. The browser then applies these styles to the corresponding regions on the screen.
- Style Calculation: Before painting, the browser needs to calculate the final computed styles for each element. This involves considering the cascaded styles, inheritance, and resolved conflicts from the parsing and computation steps. The computed styles provide the necessary information for the painting process.
- Creating Layers: To optimize performance and enable efficient rendering, modern browsers use a technique called layering. The browser creates separate layers for different elements or groups of elements. These layers allow for independent painting, compositing, and manipulation, resulting in smoother animations and interactions.
- Rendering and Painting Order: The painting process follows a specific order to determine which elements should be painted first and how they overlap. Elements are painted from back to front, following the stacking order defined by the z-index property and the document structure. Elements with a higher stacking context or a higher z-index value are painted on top of elements with a lower stacking order.
- Repaint and Optimization: Painting is an expensive operation, so browsers employ various optimization techniques to minimize unnecessary repaints. When changes occur, such as hovering over an element or resizing the browser window, the browser identifies the affected regions and repaints only those specific areas, rather than repainting the entire page. This optimization helps improve performance and reduce rendering time.
The painting step in CSS ensures that the visual styles defined in the CSS rules are applied accurately to the corresponding elements on the screen. It takes into account the final computed styles, layers, stacking order, and optimization techniques to create a visually appealing and responsive web page.
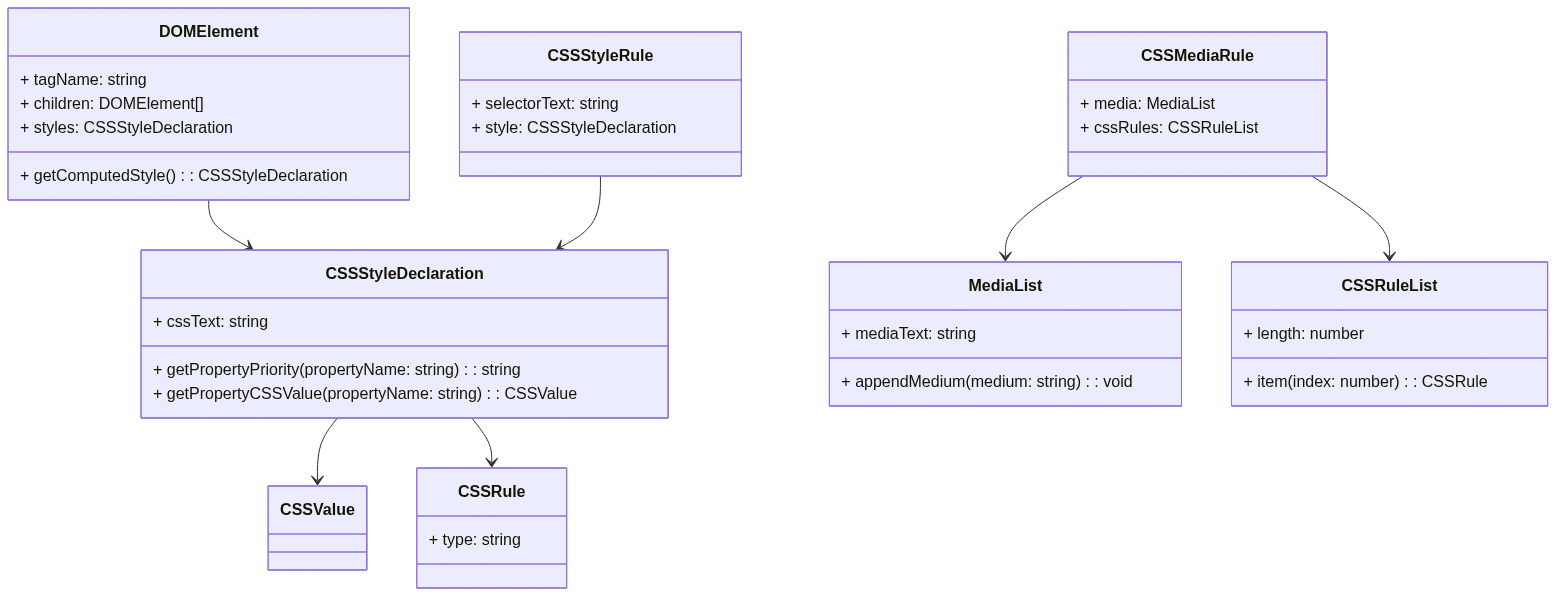
Constructing the CSS Object Model:
The CSS Object Model (CSSOM) is a representation of CSS stylesheets that allows developers to access, manipulate, and apply CSS styles programmatically. It plays a vital role in the rendering process of web pages, working alongside the Document Object Model (DOM) to create a comprehensive model of the web page’s structure and styling.
Starting with the definition:
The CSSOM represents the CSS stylesheets of a web page as a structured object model, enabling developers to programmatically interact with and manipulate CSS styles. It provides a set of APIs and interfaces that allow access to CSS rules, selectors, declarations, and other styling properties. With the CSSOM, developers can dynamically modify, add, or remove CSS styles, enabling powerful control over the visual presentation and behavior of web pages.
The CSSOM plays a critical role in the rendering process by providing the necessary styling information to the rendering engine of web browsers. It is responsible for computing the final styles for each element, resolving conflicts and inheritance, and applying the styles to the corresponding elements in the DOM. The CSSOM provides the rendering engine with a comprehensive representation of the CSS rules, allowing for efficient and accurate rendering of web pages.
Relationship between CSSOM and Document Object Model (DOM):
The CSSOM and the DOM work together to create a complete representation of the web page. While the DOM represents the structure and content of the HTML document, the CSSOM represents the styles and layout information applied to the DOM elements. Together, they form a unified model known as the render tree, which combines the structural and styling aspects of the web page.
Here is a small difference between these two terms, to make it easier to understand:
| CSSOM | DOM |
|---|---|
| The CSSOM represents the CSS stylesheets of a web page as a structured object model. | The DOM represents the structure and content of an HTML document as a tree-like structure. |
| It provides APIs and interfaces to access, manipulate, and apply CSS styles programmatically. | It provides APIs and interfaces to access, modify, and traverse the elements and content of an HTML document. |
| The CSSOM allows developers to dynamically modify, add, or remove CSS styles, providing powerful control over the visual presentation and behavior of web pages. | The DOM allows developers to dynamically interact with and modify the structure, content, and attributes of HTML elements, enabling dynamic and responsive web experiences. |
| The CSSOM represents CSS rules, selectors, declarations, and other styling properties as objects. | The DOM represents HTML elements, text nodes, attributes, and other document components as objects. |
| The CSSOM interacts with the DOM by associating CSS rules with specific DOM elements. | The DOM provides access to the associated CSS styles for each element through the CSSOM. |
| Changes made to the CSSOM, such as modifying or adding CSS rules, are reflected in the render tree, triggering updates to the visual rendering of the affected elements. | Changes made to the DOM, such as modifying element structure or content, can trigger updates to the associated CSS styles through the CSSOM. |
| The CSSOM and DOM work in tandem during the rendering process to determine the size, position, appearance, and behavior of elements on a web page. | The CSSOM provides the necessary styling information to the rendering engine, which applies the computed styles to the visual rendering of elements based on the DOM structure. |
The relationship between CSSOM and DOM can be visualized as a unified model known as the render tree. This render tree combines the structural hierarchy of the DOM with the styling rules defined in the CSSOM. It forms the basis for rendering and displaying the web page.
Conclusion:
In conclusion, understanding CSS parsing is important for developers who are seeking to optimize website performance, enhance user experiences, and create visually appealing web pages. Through the process of CSS parsing, which involves tokenization, lexical analysis, and syntax analysis, the browser converts CSS code into a structured representation called the CSS Object Model (CSSOM). This model provides a foundation for applying styles, resolving conflicts, and rendering web pages accurately.
It is important to note that CSS parsing is not without its challenges. Incorrect syntax, conflicting styles, and inefficient use of CSS properties can lead to rendering issues and performance bottlenecks. It is advisable to ensure clean and valid CSS code, utilize efficient selectors, and leverage CSS optimization techniques to mitigate these challenges.
To further explore CSS parsing and deepen your understanding, resources such as the MDN Web Docs and CSS-Tricks provide comprehensive documentation and examples. These platforms offer in-depth explanations, code snippets, and best practices to enhance your knowledge and proficiency in CSS parsing.
Happy developing! I hope you found this article helpful. (^///^)







